







Caffe手写数字训练识别
在配置caffe后,验证编译是否成功和caffe入门,那我们就从训练手写数字识别开始吧。
用手写数据库MInist数据库:
THE MNIST DATABASEof handwritten digits download url:http://yann.lecun.com/exdb/mnist/
其中包含60,000个示例的训练集以及10,000个示例的测试集。MNIST数据集包含四个文件
| 文件 | 内容 |
|---|---|
| train-images-idx3-ubyte.gz | training set images (9912422 bytes) |
| train-labels-idx1-ubyte.gz | training set labels (28881 bytes) |
| t10k-images-idx3-ubyte.gz | test set images (1648877 bytes) |
| t10k-labels-idx1-ubyte.gz: | test set labels (4542 bytes) |
这四个文件不能直接用于caffe的训练和测试。需要利用生成的convert_mnist_data.exe把四个文件转换为caffe所支持的leveldb或lmdb文件。
转换caffe可以识别的数据
四个文件放到 . \examples\mnist\mnist_data文件夹下
在caffe-windows安装的根目录下,新建一个convert-mnist-data-train.bat批处理文件转换为训练数据,并在文件中添加代码:
Build\x64\Release\convert_mnist_data.exe --backend=leveldb examples\mnist\mnist_data\train-images.idx3-ubyte examples\mnist\mnist_data\train-labels.idx1-ubyte examples\mnist\mnist_data\mnist_train_leveldb
pause
convert-mnist-data-test.bat转换测试数据,代码为:
Build\x64\Release\convert_mnist_data.exe --backend=leveldb examples\mnist\mnist_data\t10k-images.idx3-ubyte examples\mnist\mnist_data\t10k-labels.idx1-ubyte examples\mnist\mnist_data\mnist_test_leveldb
Pause
convert_mnist_data.exe的命令格式为:
convert_mnist_data [FLAGS] input_image_file input_label_file output_db_file
[FLAGS]:转换的文件格式可取leveldb或lmdb,示例:–backend=leveldb
Input_image_file:输入的图片文件,示例:train-images.idx3-ubyte
input_label_file:输入的图片标签文件,示例:train-labels.idx1-ubyte
output:保存输出文件的文件夹,示例:mnist_train_lmdb
修改 proto文件
1、首先用VS打开\examples\mnist目录下的lenet_solver.prototxt,将最后一行改成CPU:
The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt"`
test_iter specifies how many forward passes the test should carry out.
In the case of MNIST, we have test batch size 100 and 100 test iterations,
covering the full 10,000 testing images.
test_iter: 100
Carry out testing every 500 training iterations.
test_interval: 500
The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
Display every 100 iterations
display: 100
The maximum number of iterations
max_iter: 10000`
snapshot intermediate results
snapshot: 5000
snapshot_prefix: “examples/mnist/lenet”
solver mode: CPU or GPU
solver_mode: CPU
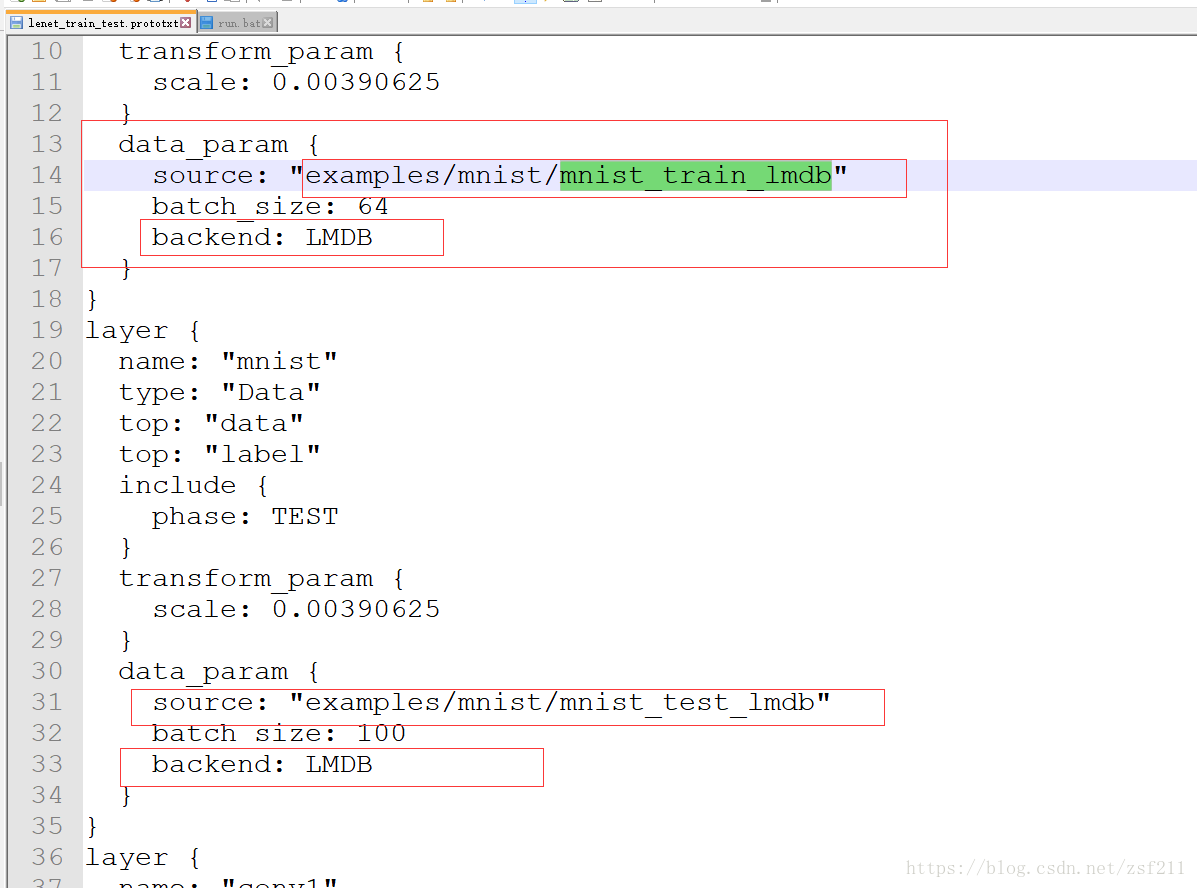
2、接着再用VS打开\examples\mnist目录下的lenet_train_test.prototxt,做如下修改以正确指定训练集和测试集。
3、转换好的训练\测试数据集(mnist_train_lmdb\ mnist_train_lmd
mnist_train_leveldb\mnist_train_leveldb)文件夹放在**.\examples\mnist**中。
开始train
1、在caffe-windows根目录下新建一个run.bat,文件中代码:
Build\x64\Release\caffe.exe train --solver=examples/mnist/lenet_solver.prototxt
pause
2、执行run.bat
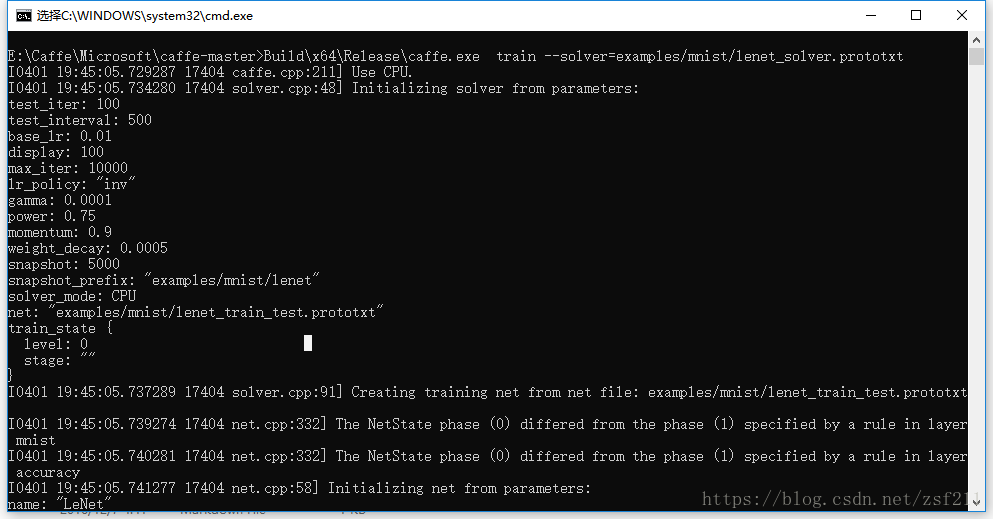
包括是用CPU还是GPU、训练参数、网络参数等等。
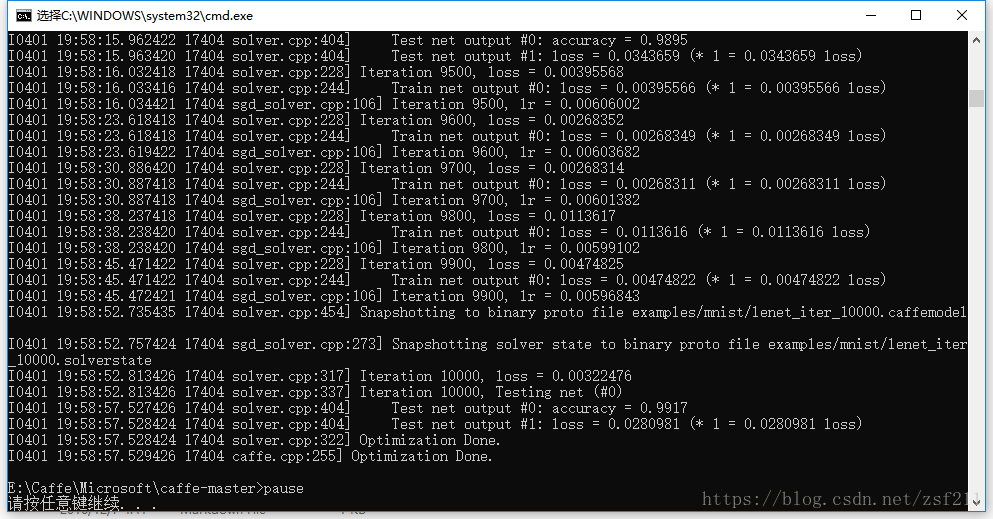
caffe采用的GLOG库内方法打印的信息,这个库主要起记录日志的功能,方便出现问题时查找根源,具体格式为:
日期 时间 进程号 文件名 行号
往右即为当前迭代次数以及损失值(训练过程不输出准确率accuracy)。
当迭代次数达到lenet_solver.prototxt定义的max_iter时,就可以认为训练结束了。并且最终会在目录\examples\mnist下产生训练出的模型(文件后缀名为caffemodel和solverstate),如下图所示:

分别是训练至一半和训练最终完成后的模型。














 7610
7610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









