






一、空字段赋值
1、NVL(给值为 NULL 的数据赋值)
格式是 NVL( string1, replace_with)。它的功能是如果string1 为 NULL,则 NVL 函数返回 replace_with 的值,否则返回 string1 的值,如果两个参数都为 NULL ,则返回 NULL。
举例:如果员工的 comm 为 NULL,则用-1 代替
select nvl(comm,-1) from emp;
二、时间类 (只针对时间格式yyyy-MM-dd HH:mm:ss)
1、date_format(格式化时间 )
select date_format('2020-02-02 10:45:00','yyyy-MM-dd');

2、date_add(时间跟天数相加 )
select date_add('2020-02-02',5);

select date_add('2020-02-02 10:20:00',5);

select date_add('2020-02-02',-5);

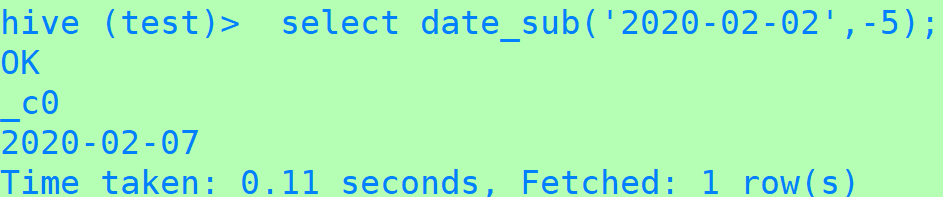
3、date_sub(时间跟天数相减)
select date_sub('2020-02-02 10:20:00',5);

select date_sub('2020-02-02',-5);
4、datediff(两个时间相减)
select datediff('2020-02-02','2020-02-01');

select datediff('2020-02-01','2020-02-02');

select datediff('2020-02-02 10:20:00','2020-02-01 16:10:00');

三、CASE WHEN
例子:
数据源:
hive (test)> select * from stuinfo;
OK
stuinfo.name stuinfo.age stuinfo.gender stuinfo.pdate
neo 28 male 2020-01-09
tom 30 female 2020-01-09
neo 28 male 2020-01-10
tom 30 female 2020-01-10
neo 28 male 2020-01-11
tom 30 female 2020-01-11
Time taken: 0.481 seconds, Fetched: 6 row(s)
按照时间分组,求男女各多少人
select pdate,count(case when gender='male' then 1 else null end) as malecount,
count(case when gender='female' then 1 else null end) as femalecount
from stuinfo
group by pdate;
结果如下:
pdate malecount femalecount
2020-01-09 1 1
2020-01-10 1 1
2020-01-11 1 1
Time taken: 53.455 seconds, Fetched: 3 row(s)
扩展:
select pdate,count(if(gender='male',1,null)) as malecount,
count(if(gender='female',1,null)) as femalecount
from stuinfo
group by pdate;
结果:
pdate malecount femalecount
2020-01-09 1 1
2020-01-10 1 1
2020-01-11 1 1
Time taken: 51.662 seconds, Fetched: 3 row(s)
四、行列互转
1、CONCAT(返回输入字符串连接后的结果)
CONCAT(str1,str2,…)
支持任意个输入字符串,如有任何一个参数为NULL ,则返回值为 NULL
(1)select concat(name,',',age,',',gender) from stuinfo;
hive (test)> select concat(name,',',age,',',gender) from stuinfo;
OK
_c0
neo,28,male
tom,30,female
neo,28,male
tom,30,female
neo,28,male
tom,30,female
Time taken: 0.384 seconds, Fetched: 6 row(s)
(2)select concat(name,null,age,',',gender) from stuinfo;
hive (test)> select concat(name,null,age,',',gender) from stuinfo;
OK
_c0
NULL
NULL
NULL
NULL
NULL
NULL
Time taken: 0.666 seconds, Fetched: 6 row(s)
2、CONCAT_WS
使用函数CONCAT_WS()。使用语法为:CONCAT_WS(separator,str1,str2,…)
CONCAT_WS() 代表 CONCAT With Separator ,是CONCAT()的特殊形式。第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。但是CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。
(1)select concat_ws('_',null,name,',',gender) from stuinfo;
hive (test)> select concat_ws('_',null,name,',',gender) from stuinfo;
OK
_c0
neo_,_male
tom_,_female
neo_,_male
tom_,_female
neo_,_male
tom_,_female
Time taken: 0.295 seconds, Fetched: 6 row(s)
(2)select concat_ws('_','',name,',',gender) from stuinfo;
hive (test)> select concat_ws('_','',name,',',gender) from stuinfo;
OK
_c0
_neo_,_male
_tom_,_female
_neo_,_male
_tom_,_female
_neo_,_male
_tom_,_female
Time taken: 0.366 seconds, Fetched: 6 row(s)
3、COLLECT_SET,COLLECT_LIST(某列的多行变成一列,列里数据为数组)
函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生 array 类型字段
collect_list 不去重,而 collect_set 去重
select collect_set(name) from stuinfo;
["neo","tom"]
Time taken: 46.644 seconds, Fetched: 1 row(s)
select collect_list(name) from stuinfo;
["neo","tom","neo","tom","neo","tom"]
Time taken: 50.584 seconds, Fetched: 1 row(s)
按天查询有哪些学生名字,学生名字用'-'分割
select pdate,concat_ws('-',collect_set(name)) as names
from
stuinfo
group by pdate;
结果:
pdate names
2020-01-09 neo-tom
2020-01-10 neo-tom
2020-01-11 neo-tom
Time taken: 48.89 seconds, Fetched: 3 row(s)
4、EXPLODE( 一列中复杂的 array 或者 map 结构拆分成多行)
(1)用于array类型的数据
select explode(array_col) as new_col from table_name
array_col:为数组类型的字段
例:
hive (test)> select * from movie_info;
OK
movie_info.movie movie_info.category
《疑犯追踪》 ["悬疑","动作","科幻","剧情 "]
《Lie to me》 ["悬疑","警匪","动作","心理","剧情 "]
《战狼 2》 ["战争","动作","灾难"]
Time taken: 0.21 seconds, Fetched: 3 row(s)
select explode(category) as new_category from movie_info;
hive (test)> select explode(category) as new_category from movie_info;
OK
new_category
悬疑
动作
科幻
剧情
悬疑
警匪
动作
心理
剧情
战争
动作
灾难
Time taken: 0.104 seconds, Fetched: 12 row(s)
(2)用于map类型数据
由于map是kay-value结构的,所以它在转换的时候会转换成两列,一列是kay转换而成的,一列是value转换而成的。
select explode(map_col) as (may_key_col, may_value_col) from table_name
例:
hive (test)> select * from personinfo;
OK
personinfo.name personinfo.friends personinfo.children personinfo.address
neo ["zs","lisi"] {"xiao neo":18,"xiaoxiao neo":10} {"street":"yuanqu","city":"suzhu"}
Time taken: 0.615 seconds, Fetched: 1 row(s)
select explode(children) as (children_name, children_age) from personinfo;
hive (test)> select explode(children) as (children_name, children_age) from personinfo;
OK
children_name children_age
xiao neo 18
xiaoxiao neo 10
Time taken: 0.125 seconds, Fetched: 2 row(s)
5、lateral view
lateral view 用于和UDTF相结合使用。他会将UDTF生成的结果放在一张虚拟表(即lateral view里)。虚拟表相当于再和主表关联, 从而达到添加“UDTF生成的字段“以外的字段, 即主表里的字段或者主表运算后的字段。
select o.*, table_view.new_col from table_origin o lateral view UDTF(expression) table_view as `new_col_1`, `new_col_2`
(1)lateral view 表示将UDTF分裂的字段放在虚拟表中, 然后和主表table_origin进行关联。
(2)UDTF(expression):复合逻辑规则的UDTF函数,最常用的explode
(3)table_view : 对应的虚拟表的表名
(4)new_col: 虚拟表里存放的有效字段
(5)from子句后面也可以跟多个lateral view语句,使用空格间隔就可以了
select movie,category_name
from
movie_info
lateral view explode(category) table_tmp as category_name;
结果:
hive (test)> select movie,category_name
> from
> movie_info
> lateral view explode(category) table_tmp as category_name;
OK
movie category_name
《疑犯追踪》 悬疑
《疑犯追踪》 动作
《疑犯追踪》 科幻
《疑犯追踪》 剧情
《Lie to me》 悬疑
《Lie to me》 警匪
《Lie to me》 动作
《Lie to me》 心理
《Lie to me》 剧情
《战狼 2》 战争
《战狼 2》 动作
《战狼 2》 灾难
Time taken: 0.106 seconds, Fetched: 12 row(s)
lateral view其他用法参看:
https://www.deeplearn.me/2892.html
http://blog.csdn.net/oopsoom/article/details/26001307
https://my.oschina.net/leejun2005/blog/120463
五、替换
1、regexp_replace
(1)select regexp_replace('2020/02/02','/','-');
hive (test)> select regexp_replace('2020/02/02','/','-');
OK
_c0
2020-02-02
Time taken: 0.111 seconds, Fetched: 1 row(s)














 5046
5046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









