







转载自http://blog.csdn.net/qq_19917081/article/details/56841299
spark streaming 从kafka拉取数据,根绝消息内容,需要将不容的消息放到不同的文件夹下,大致内容为 从消息中拆分出域名,不同域名分不到不同目录,域名下按消息中的时间分年月日目录,底层目录下自定义文件个数,实现追加
由于sparkstreaming 10秒运行一次job,需要重写 OutputFormat,来实现按内容分目录,文件追加
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val line = lines.map(x => (x, 1)).repartition(20)
line.saveAsHadoopFiles("","",classOf[Text],classOf[NullWritable],classOf[MyMultipleTextOutputFormat[Text,NullWritable]])MyMultipleTextOutputFormat 即为我们重写的类
package com.linkingcloud.bigdata.common;
import com.linkingcloud.bigdata.common.interpret.LineInterpret;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat;
import org.apache.hadoop.util.Progressable;
import org.apache.hadoop.mapred.RecordWriter;
import java.io.IOException;
import java.util.Iterator;
import java.util.Random;
import java.util.TreeMap;
/**
* Created by apple on 2017/2/15.
*/
public class MyMultipleTextOutputFormat<K, V> extends MultipleTextOutputFormat<K, V> {
private TextOutputFormat<K, V> theTextOutputFormat = null;
public RecordWriter getRecordWriter(final FileSystem fs, final JobConf job, final String name, final Progressable arg3) throws IOException {
return new RecordWriter() {
TreeMap<String, RecordWriter<K, V>> recordWriters = new TreeMap();
public void write(Object key, Object value) throws IOException {
//key中为消息内容,value无意义
String line = key.toString();
//根据消息内容,定义输出路径和输出内容(同时清洗数据)
String[] ss = LineInterpret.interpretLine(line, "/test/spark/kafka");
if (ss != null && ss.length == 2) {
//name的最后两位为jobid,同一个文件只能同时允许一个job写入,多个job写一个文件会报错,将jobid作为文件名的一部分
//能解决此问题
String finalPath = ss[1] + "-" + name.substring(name.length() - 2);
RecordWriter rw = (RecordWriter) this.recordWriters.get(finalPath);
try {
if (rw == null) {
rw = getBaseRecordWriter(fs, job, finalPath, arg3);
this.recordWriters.put(finalPath, rw);
}
rw.write(ss[0], null);
} catch (Exception e) {
//一个周期内,job不能完成,下一个job启动,会造成同时写一个文件的情况,变更文件名,添加后缀
this.rewrite(finalPath + "-", ss[0]);
}
}
}
public void rewrite(String path, String line) {
String finalPath = path + new Random().nextInt(10);
RecordWriter rw = (RecordWriter) this.recordWriters.get(finalPath);
try {
if (rw == null) {
rw = getBaseRecordWriter(fs, job, finalPath, arg3);
this.recordWriters.put(finalPath, rw);
}
rw.write(line, null);
} catch (Exception e) {
//重试
this.rewrite(finalPath, line);
}
}
public void close(Reporter reporter) throws IOException {
Iterator keys = this.recordWriters.keySet().iterator();
while (keys.hasNext()) {
RecordWriter rw = (RecordWriter) this.recordWriters.get(keys.next());
rw.close(reporter);
}
this.recordWriters.clear();
}
};
}
protected RecordWriter<K, V> getBaseRecordWriter(FileSystem fs, JobConf job, String path, Progressable arg3) throws IOException {
if (this.theTextOutputFormat == null) {
this.theTextOutputFormat = new MyTextOutputFormat();
}
return this.theTextOutputFormat.getRecordWriter(fs, job, path, arg3);
}
}MyTextOutputFormat中实现对存在的文件进行append,而不是覆盖
package com.linkingcloud.bigdata.common;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.RecordWriter;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.Progressable;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.DataOutputStream;
import java.io.IOException;
/**
* Created by apple on 2017/2/15.
*/
public class MyTextOutputFormat<K, V> extends TextOutputFormat<K, V> {
public MyTextOutputFormat() {
}
@Override
public RecordWriter<K, V> getRecordWriter(FileSystem ignored, JobConf job, String path, Progressable progress) throws IOException {
String keyValueSeparator = job.get("mapreduce.output.textoutputformat.separator", "\t");
CompressionCodec codec = ReflectionUtils.newInstance(GzipCodec.class, job);
Path file = FileOutputFormat.getTaskOutputPath(job, path + codec.getDefaultExtension());
FileSystem fs = file.getFileSystem(job);
String file_path = path + codec.getDefaultExtension();
Path newFile = new Path(FileOutputFormat.getOutputPath(job), file_path);
FSDataOutputStream fileOut;
if (fs.exists(newFile)) {
fileOut = fs.append(newFile,4096,progress);
} else {
fileOut = fs.create(newFile, progress);
}
return new TextOutputFormat.LineRecordWriter(new DataOutputStream(codec.createOutputStream(fileOut)), keyValueSeparator);
}
}结果如下:
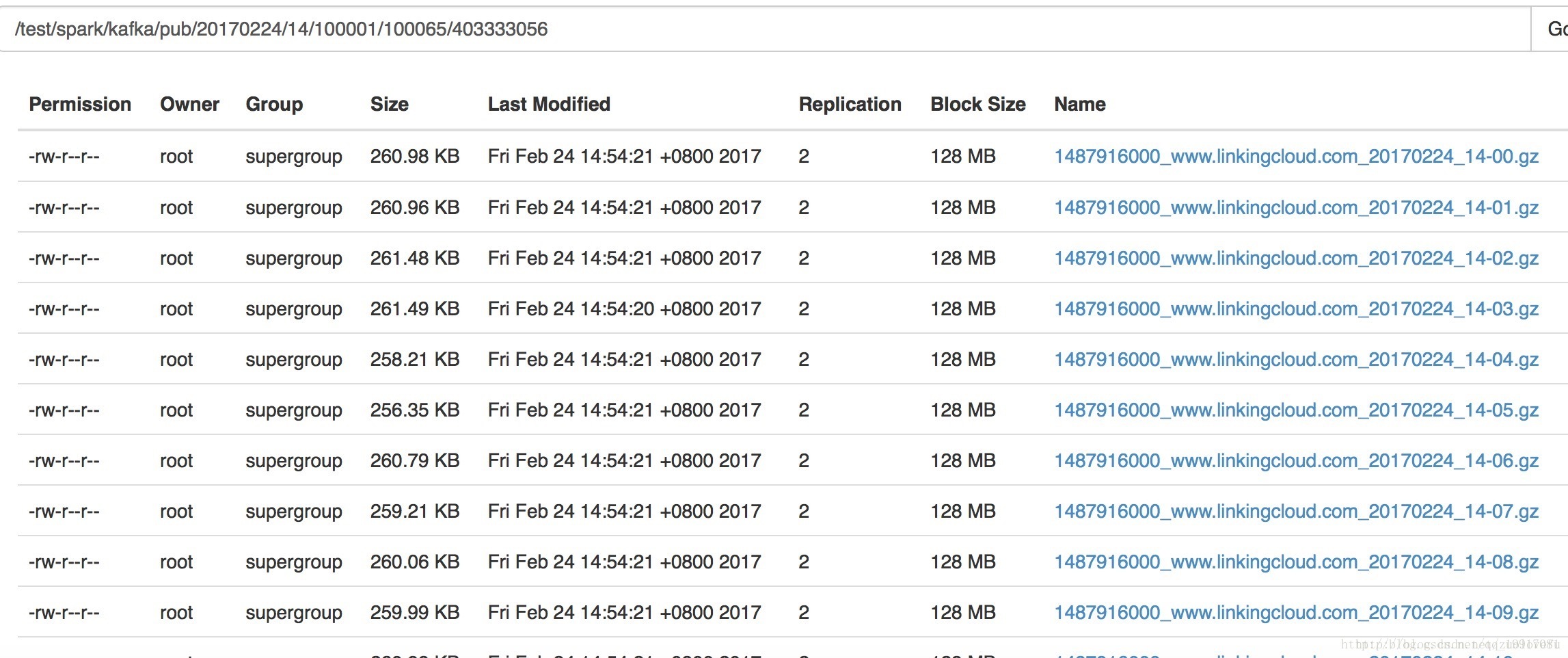
spark streaming 采用gzip压缩,会导致derect memory泄露,暂时没有找到好的解决方法,只能不使用压缩,谁解决了此问题,可以留言,感谢!















 5255
5255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









