







排序算法系列学习,主要描述冒泡排序,选择排序,直接插入排序,希尔排序,堆排序,归并排序,快速排序等排序进行分析。
文章规划:
一。通过自己对排序算法本身的理解,对每个方法写个小测试程序。具体思路分析不展开描述。
二。通过《大话数据结构》一书的截图,详细分析该算法。
在此,推荐下程杰老师的《大话数据结构》一书,当然不是打广告,只是以一名读者的身份来客观的看待这本书,确实是通俗易懂,值得一看。
ps:一个较为详细的学习链接 http://blog.csdn.net/guo_hongjun1611/article/details/7632047
五。堆排序
一。个人理解
学习堆排序,要了解以下两方面内容。
1.堆的定义
2.堆排序的实现。
1.堆的定义
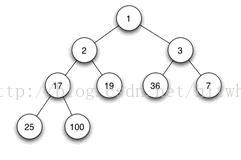
堆实际上是一棵完全二叉树,其任何一非叶节点满足性质:
一。 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2] 小顶堆
或者 Key[i]>=Key[2i+1]&&key[i]>=key[2i+2] 大顶堆
即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。
由上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
二。 每个结点的左子树和右子树都是一个二叉堆(都是小顶堆或大顶堆)。
满足以上条件的二叉树就是一个堆。
如下图所示,就是一个小顶堆。
2.堆排序的实现。
堆排序是利用堆的性质进行的一种选择排序。
其基本思想为(大顶堆):
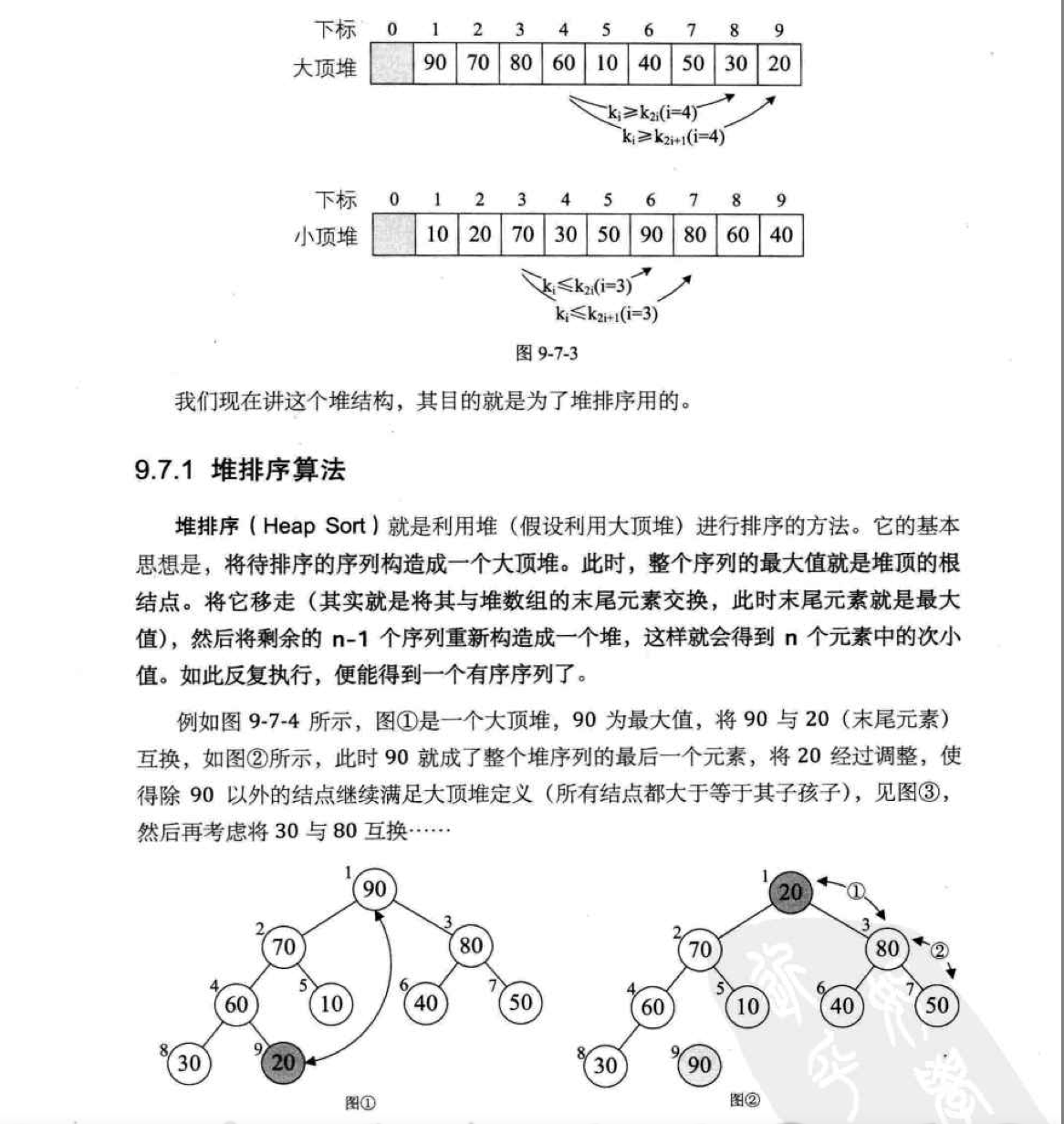
1)将初始待排序关键字序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无序区;
2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。
不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
具体的演示过程我就不详细介绍了。可以通过阅读下面的《大话数据结构》一书截图系统的学习。
下面直接上代码
- #include<stdio.h>
- // 打印结果
- void Show(int arr[], int n)
- {
- int i;
- for ( i=0; i<n; i++ )
- printf("%d ", arr[i]);
- printf("\n");
- }
- // 交换数组元素位置
- void Swap( int *num_a, int *num_b )
- {
- int temp = *num_b;
- *num_b = *num_a;
- *num_a = temp;
- }
- // array是待调整的堆数组,i是待调整的数组元素的位置,nlength是数组的长度
- void HeapAdjust(int array[], int i, int nLength)
- {
- int nChild, nTemp;
- for (nTemp = array[i]; 2 * i + 1 < nLength; i = nChild)
- {
- // nChild:左子结点的位置是 父结点位置 * 2 + 1 nChild + 1: 右子结点
- nChild = 2 * i + 1;
- // 得到子结点中较大的结点
- if (nChild != nLength - 1 && array[nChild + 1] > array[nChild])
- ++nChild;
- // 如果较大的子结点大于父结点那么把较大的子结点往上移动,替换它的父结点
- if (nTemp < array[nChild])
- {
- array[i] = array[nChild];
- }
- else // 否则退出循环
- {
- break;
- }
- }
- // 最后把需要调整的元素值放到合适的位置
- array[i] = nTemp;
- }
- // 堆排序算法
- void HeapSort(int array[], int length)
- {
- // 调整序列的前半部分元素,(即每个有孩子的节点)调整完之后是一个大顶堆,第一个元素是序列的最大的元素
- for (int i = length / 2 - 1; i >= 0; --i)
- {
- HeapAdjust(array, i, length);
- }
- // 从最后一个元素开始对序列进行调整,不断的缩小调整的范围直到第一个元素
- for (int i = length - 1; i > 0; --i)
- {
- // 把第一个元素和当前的最后一个元素交换,
- // 保证当前的最后一个位置的元素都是在现在的这个序列之中最大的
- Swap(&array[0], &array[i]);
- // 不断缩小调整heap的范围,每一次调整完毕保证第一个元素是当前序列的最大值
- HeapAdjust(array, 0, i);
- }
- }
- int main()
- { //测试数据
- int arr_test[10] = { 8, 4, 2, 3, 5, 1, 6, 9, 0, 7 };
- //排序前数组序列
- Show( arr_test, 10 );
- HeapSort( arr_test, 10 );
- //排序后数组序列
- Show( arr_test, 10 );
- return 0;
- }
可以看下这组测试数据的过程加深理解
- 一个测试及输出的结果,在每次HeapAdjust之后显示出来当前数组的情况
- before Heap sort:
- 71 18 151 138 160 63 174 169 79 78
- // 开始调整前半段数组元素
- 71 18 151 138 160 63 174 169 79 78
- 71 18 151 169 160 63 174 138 79 78
- 71 18 174 169 160 63 151 138 79 78
- 71 169 174 138 160 63 151 18 79 78
- 174 169 151 138 160 63 71 18 79 78
- // 开始进行全局的调整
- 169 160 151 138 78 63 71 18 79 174
- 160 138 151 79 78 63 71 18 169 174
- 151 138 71 79 78 63 18 160 169 174
- 138 79 71 18 78 63 151 160 169 174
- 79 78 71 18 63 138 151 160 169 174
- 78 63 71 18 79 138 151 160 169 174
- 71 63 18 78 79 138 151 160 169 174
- 63 18 71 78 79 138 151 160 169 174
- 18 63 71 78 79 138 151 160 169 174
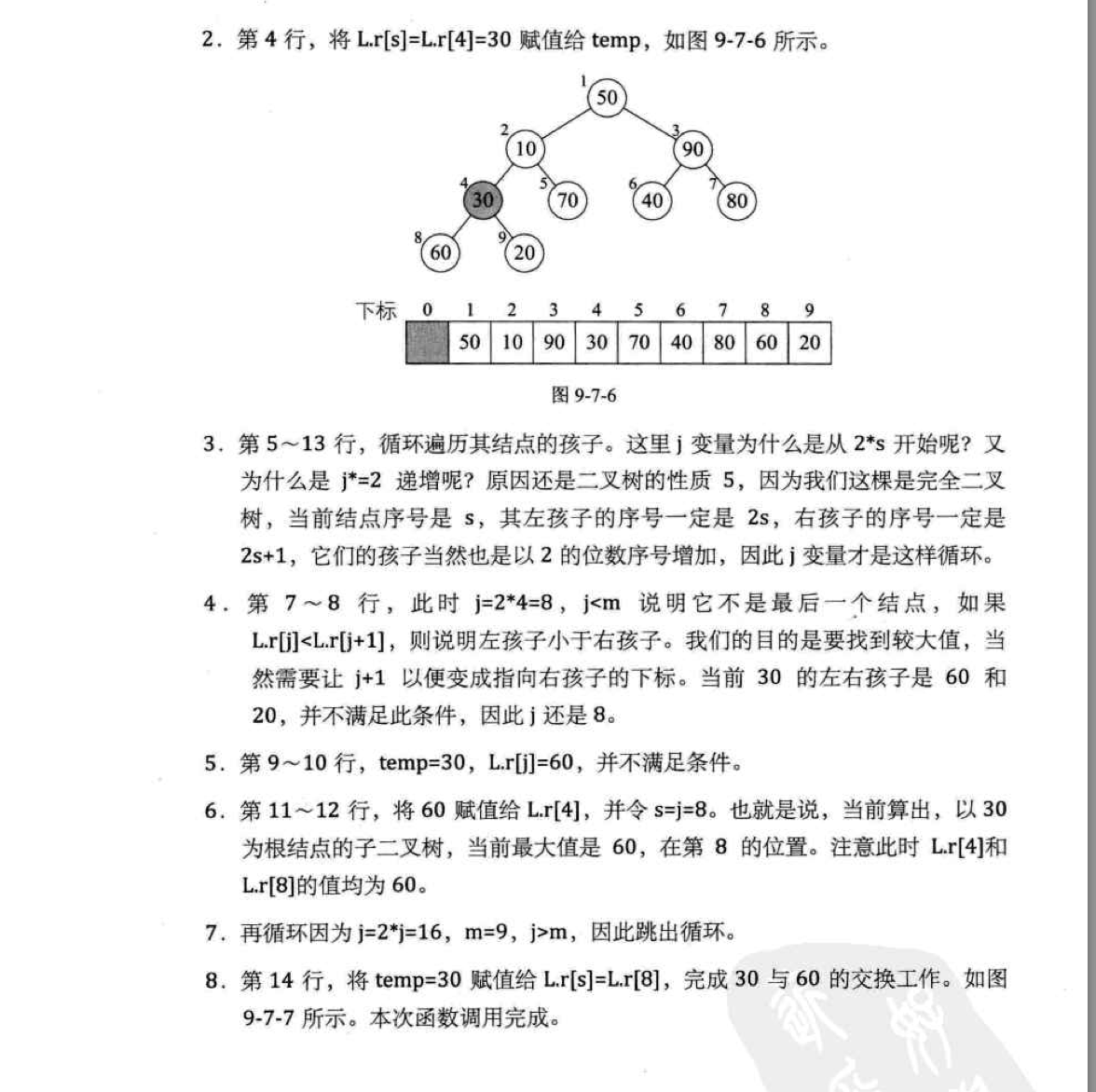
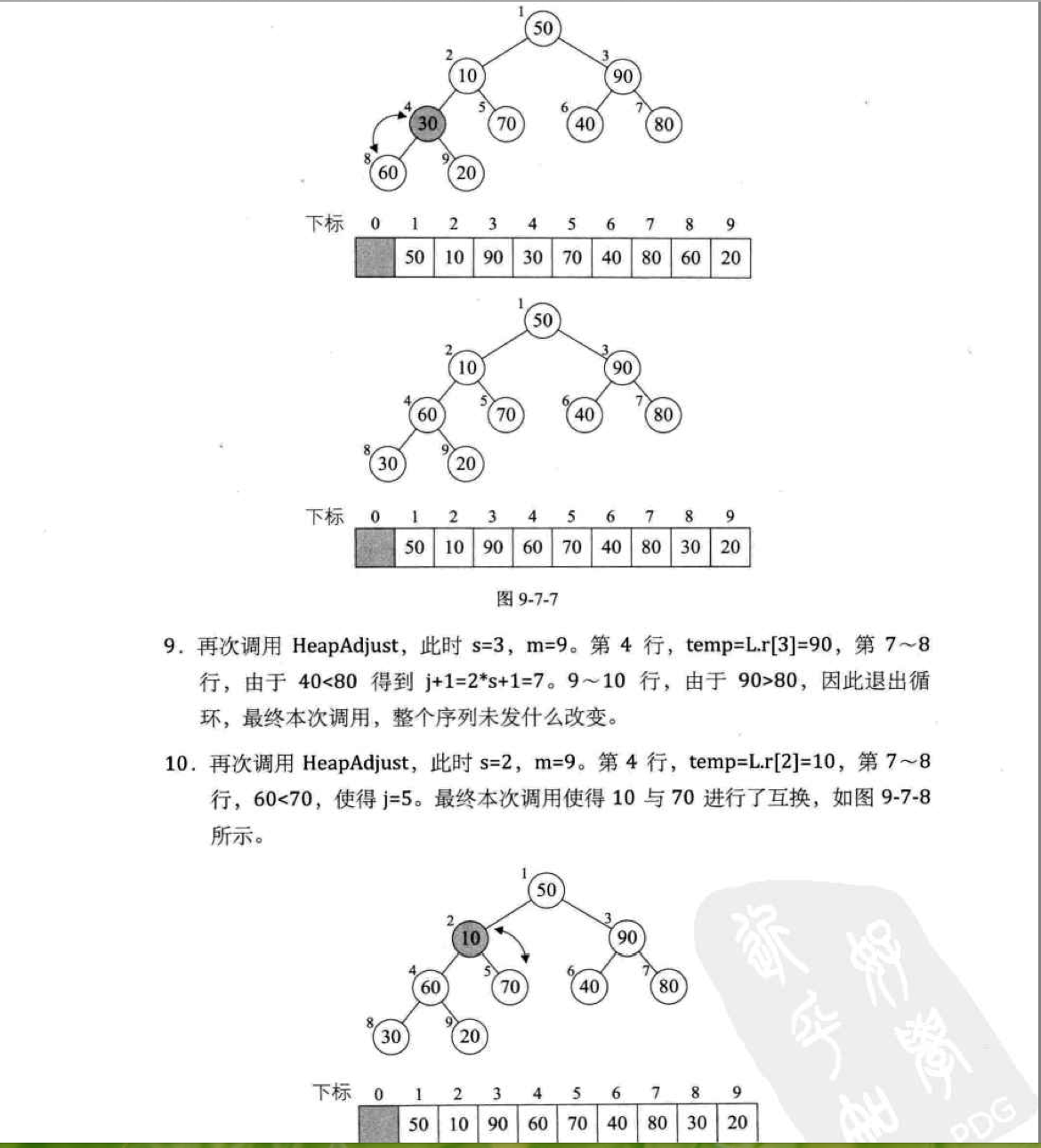
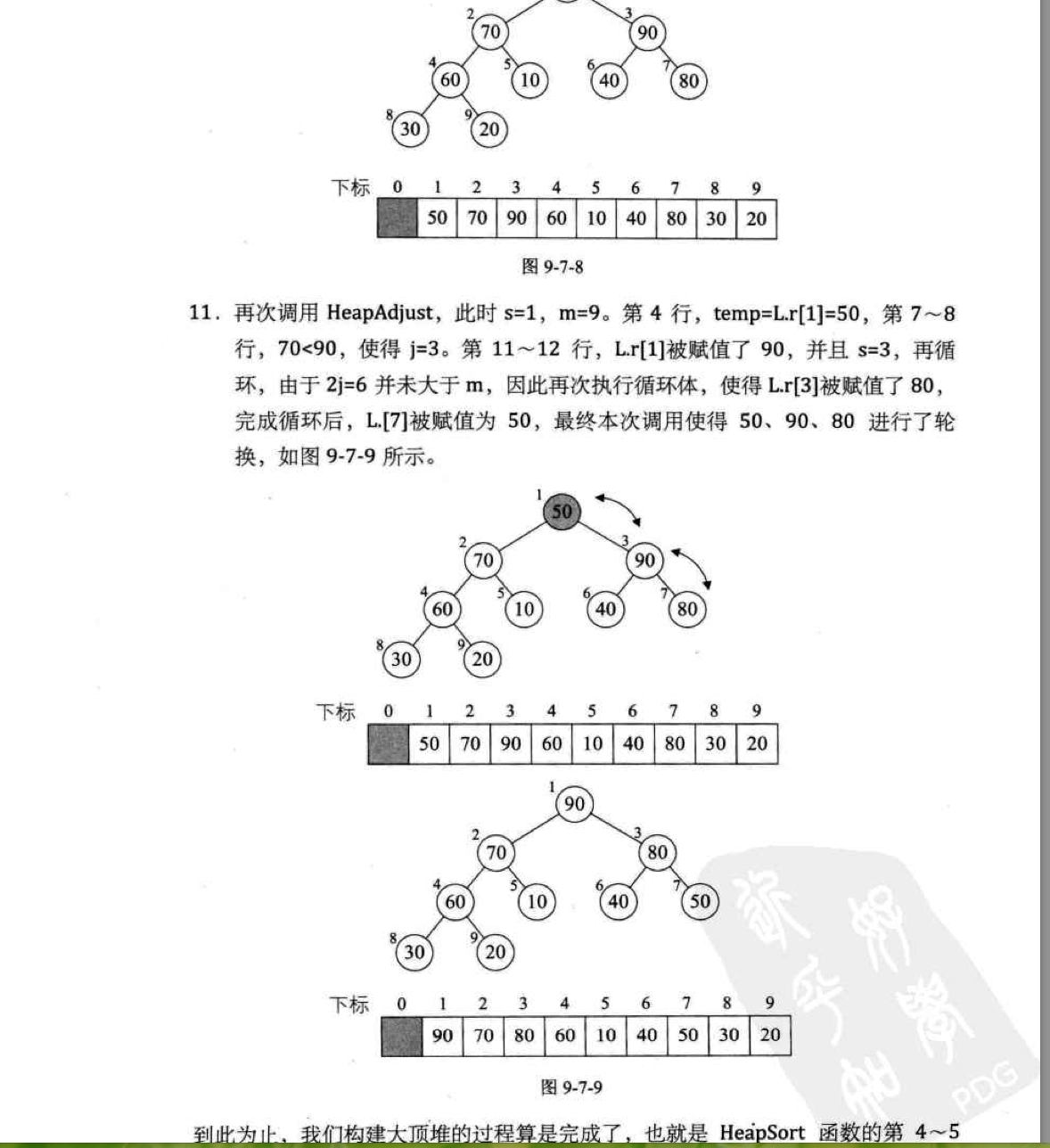
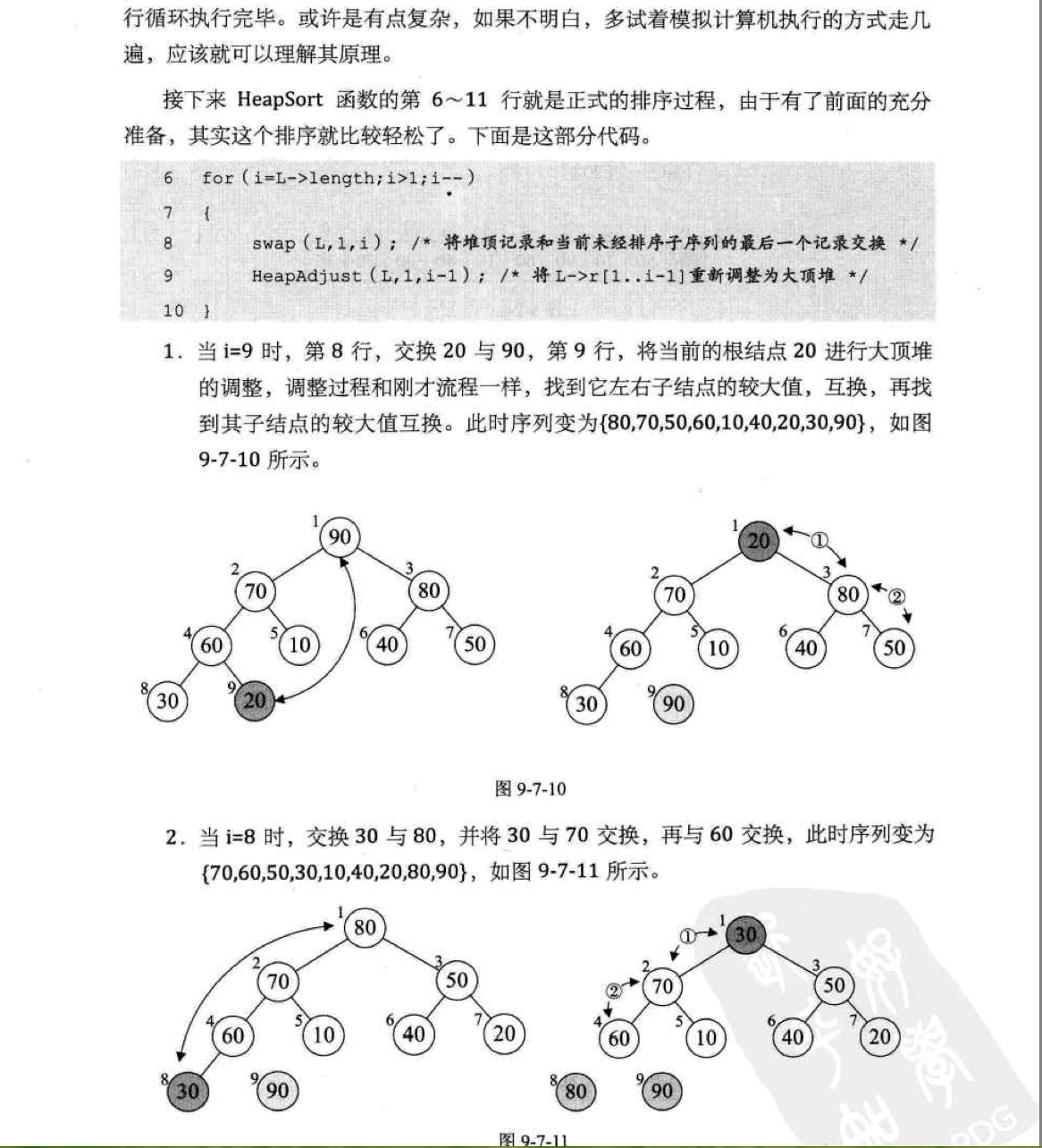
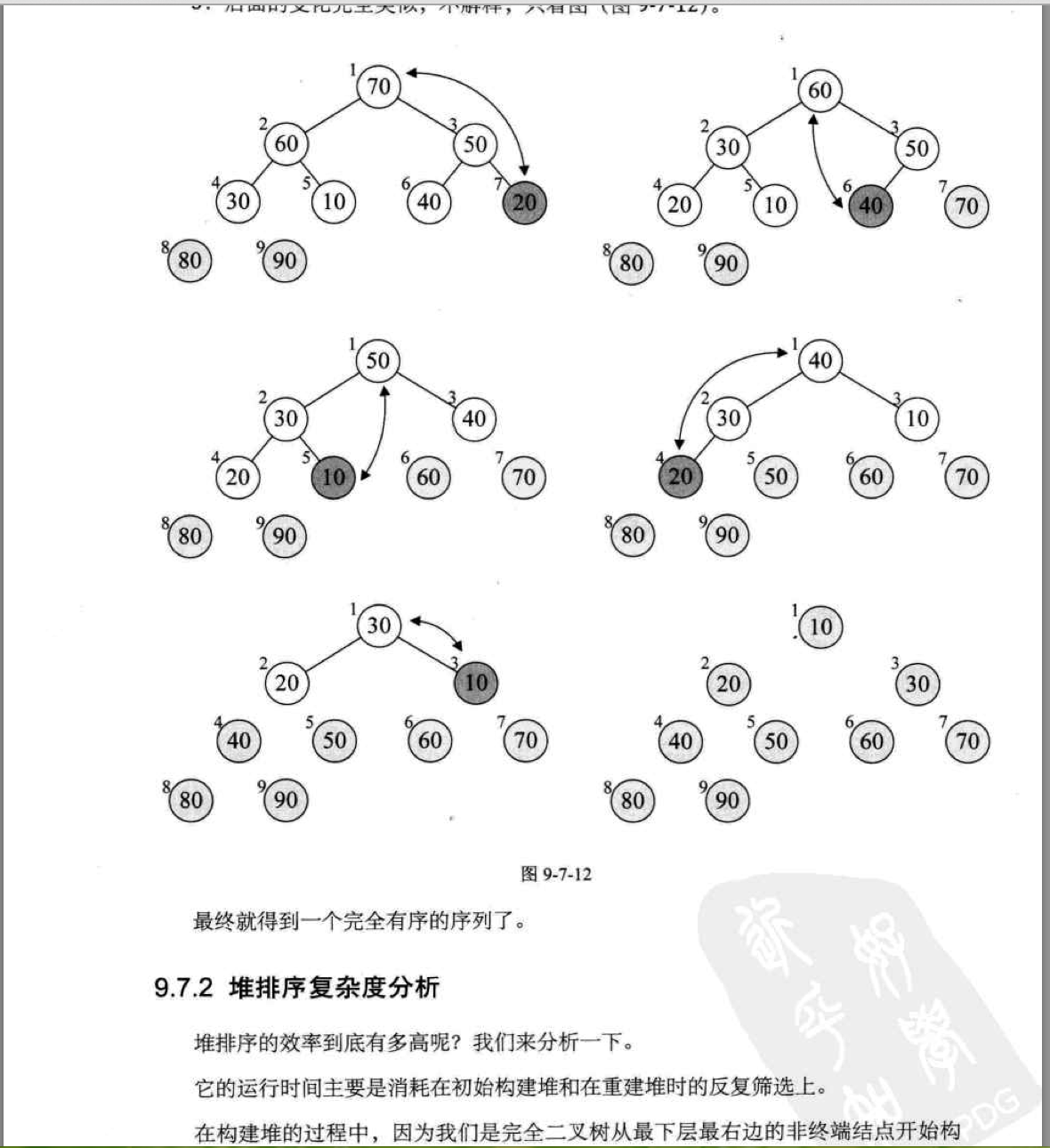
二。 《大话数据结构》一书截图分析
注:本文仅为分享知识,绝无商业用途。
如果以该种形式分享知识造成不必要的纠纷,还请第一时间告知。





















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









