







scrapy爬虫的搭建过程(实战篇)
1. 爬虫功能
- 以 http://bbs.fengniao.com/forum/forum_125_1_lastpost.html 为起始页,爬取前十页的信息,包括文章的标题、链接地址和图片地址,保存到mongodb中。并下载对应的图片到本地目录。
2. 环境
- 系统:win7
- Scrapy 1.4.0
- mongodb v3.2
- python 3.6.1
3. 代码
3.1. 创建爬虫项目
# 第一步,进入需要防止爬虫代码的位置,下图中指定目录为:E:\myScrapyCode
scrapy startproject fengniao #创建一个爬虫项目fengniao
cd fengniao #进入到爬虫项目目录
scrapy genspider fengniaoClawer fengniao.com #创建一个具体的爬虫fengniaoClawer, 并初始化域名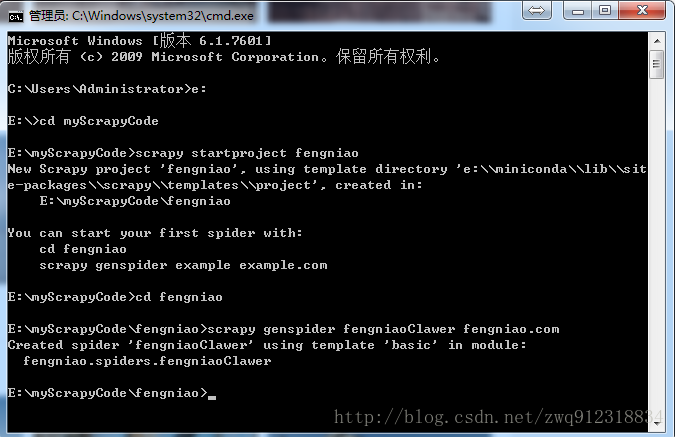
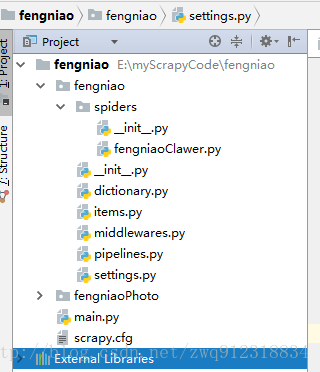
3.2. 代码结构
3.3. 详细代码
- fengniaoClawer.py
# 文件:fengniaoClawer.py
# -*- coding: utf-8 -*-
import scrapy
from fengniao.items import FengniaoItem
from scrapy.spidermiddlewares.httperror import HttpError
from twisted.internet.error import TimeoutError, TCPTimedOutError, DNSLookupError, ConnectionRefusedError
class FengniaoclawerSpider(scrapy.Spider):
name = 'fengniaoClawer' # 爬虫名字,爬虫启动时需要指定的名字
allowed_domains = ['fengniao.com'] # 允许的域名,非这个域名下的url都会被抛弃掉
manualRetry = 8 # 手动重试的次数,有些网页即使状态码为200,也未必说明内容被拉下来, 拉下来的可能是残缺的一部分
# 爬虫自定义设置,会覆盖 settings.py 文件中的设置
custom_settings = {
'LOG_LEVEL': 'DEBUG', # 定义log等级
'DOWNLOAD_DELAY': 0, # 下载延时
'COOKIES_ENABLED': False, # enabled by default
'DEFAULT_REQUEST_HEADERS': {
# 'Host': 'www.fengniao.com',
'Referer': 'https://www.fengniao.com',
},
# 管道文件,优先级按照由小到大依次进入
'ITEM_PIPELINES': {
'fengniao.pipelines.ImagePipeline':100,
'fengniao.pipelines.FengniaoPipeline': 300,
},
# 关于下载图片部分
'IMAGES_STORE':'fengniaoPhoto', # 没有则新建
'IMAGES_EXPIRES':90, # 图片有效期,已经存在的图片在这个时间段内不会再下载
'IMAGES_MIN_HEIGHT': 100, # 图片最小尺寸(高度),低于这个高度的图片不会下载
'IMAGES_MIN_WIDTH': 100, # 图片最小尺寸(宽度),低于这个宽度的图片不会下载
# 下载中间件,优先级按照由小到大依次进入
'DOWNLOADER_MIDDLEWARES': {
'fengniao.middlewares.ProxiesMiddleware': 400,
'fengniao.middlewares.HeadersMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
},
'DEPTH_PRIORITY': 1, # BFS,是以starts_url为准,局部BFS,受CONCURRENT_REQUESTS影响
'SCHEDULER_DISK_QUEUE': 'scrapy.squeues.PickleFifoDiskQueue',
'SCHEDULER_MEMORY_QUEUE': 'scrapy.squeues.FifoMemoryQueue',
'REDIRECT_PRIORITY_ADJUST': 2, # Default: +2
'RETRY_PRIORITY_ADJUST': -1, # Default: -1
'RETRY_TIMES': 8, # 重试次数
# Default: 2, can also be specified per-request using max_retry_times attribute of Request.meta
'DOWNLOAD_TIMEOUT': 30,
# This timeout can be set per spider using download_timeout spider attribute and per-request using download_timeout Request.meta key
# 'DUPEFILTER_CLASS': "scrapy_redis.dupefilter.RFPDupeFilter",
# 'SCHEDULER': "scrapy_redis.scheduler.Scheduler",
# 'SCHEDULER_PERSIST': False, # Don't cleanup redis queues, allows to pause/resume crawls.
# 并发度相关。根据网站情况,网速以及代理来设置
'CONCURRENT_REQUESTS': 110, # default 16,Scrapy downloader 并发请求(concurrent requests)的最大值,即一次读入并请求的url数量
# 'CONCURRENT_REQUESTS_PER_DOMAIN':15, #default 8 ,对单个网站进行并发请求的最大值。
'CONCURRENT_REQUESTS_PER_IP': 5, # default 0,如果非0,则忽略CONCURRENT_REQUESTS_PER_DOMAIN 设定, 也就是说并发限制将针对IP,而不是网站
'REACTOR_THREADPOOL_MAXSIZE': 20, # default 10
# 限制爬取深度, 相对于start_url的深度
# 注意,这个深度一定要大于 retry的深度,要不然的话,一旦重试次数达到极致,也就达到了最大深度,爬虫会丢弃这个Request
'DEPTH_LIMIT': 10,
}
# 爬虫发起的第一个请求
def start_requests(self): 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









