







如何在scrapy中集成selenium爬取网页
1.背景
- 我们在爬取网页时一般会使用到三个爬虫库:requests,scrapy,selenium。requests一般用于小型爬虫,scrapy用于构建大的爬虫项目,而selenium主要用来应付负责的页面(复杂js渲染的页面,请求非常难构造,或者构造方式经常变化)。
- 在我们面对大型爬虫项目时,肯定会优选scrapy框架来开发,但是在解析复杂JS渲染的页面时,又很麻烦。 尽管使用selenium浏览器渲染来抓取这样的页面很方便,这种方式下,我们不需要关心页面后台发生了怎样的请求,也不需要分析整个页面的渲染过程,我们只需要关心页面最终结果即可,可见即可爬,但是selenium的效率又太低。
- 所以,如果可以在scrapy中,集成selenium,让selenium负责复杂页面的爬取,那么这样的爬虫就无敌了,可以爬取任何网站了。
2. 环境
- python 3.6.1
- 系统:win7
- IDE:pycharm
- 安装过chrome浏览器
- 配置好chromedriver(设置好环境变量)
- selenium 3.7.0
- scrapy 1.4.0
3.原理分析
3.1. 分析request请求的流程
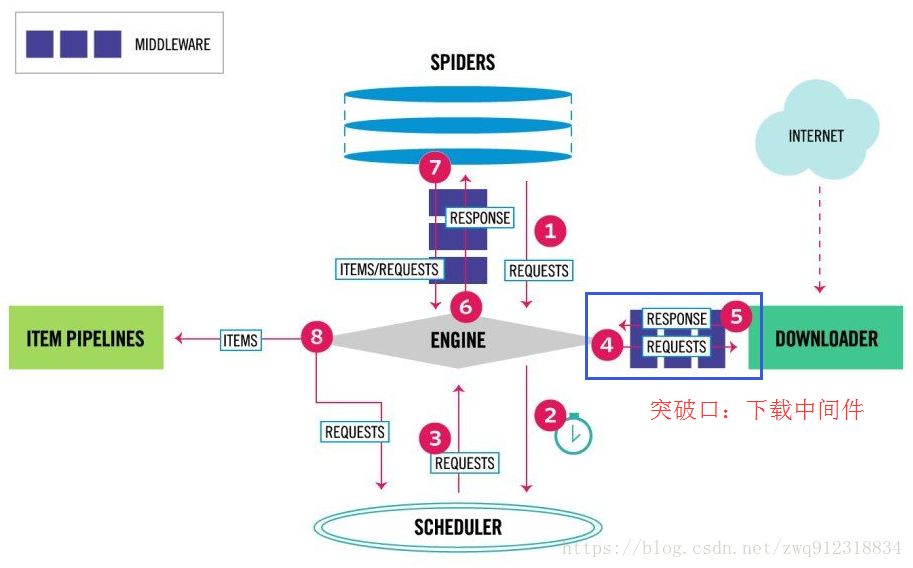
首先看一下scrapy最新的架构图(https://blog.csdn.net/zwq912318834/article/details/79720742):
部分流程:
- 第一:爬虫引擎生成requests请求,送往scheduler调度模块,进入等待队列,等待调度。
- 第二:scheduler模块开始调度这些requests,出队,发往爬虫引擎。
- 第三:爬虫引擎将这些requests送到下载中间件(多个,例如加header,代理,自定义等等)进行处理。
- 第四:处理完之后,送往Downloader模块进行下载。
- 从这个处理过程来看,突破口就在下载中间件部分,用selenium直接处理掉request请求。
3.2. requests和response中间处理件源码分析
相关代码位置:
源码解析:
# 文件:E:\Miniconda\Lib\site-packages\scrapy\core\downloader\middleware.py
"""
Downloader Middleware manager
See documentation in docs/topics/downloader-middleware.rst
"""
import six
from twisted.internet import defer
from scrapy.http import Request, Response
from scrapy.middleware import MiddlewareManager
from scrapy.utils.defer import mustbe_deferred
from scrapy.utils.conf import build_component_list
class DownloaderMiddlewareManager(MiddlewareManager):
component_name = 'downloader middleware'
@classmethod
def _get_mwlist_from_settings(cls, settings):
# 从settings.py或这custom_setting中拿到自定义的Middleware中间件
'''
'DOWNLOADER_MIDDLEWARES': {
'mySpider.middlewares.ProxiesMiddleware': 400,
# SeleniumMiddleware
'mySpider.middlewares.SeleniumMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
},
'''
return build_component_list(
settings.getwithbase('DOWNLOADER_MIDDLEWARES'))
# 将所有自定义Middleware中间件的处理函数添加到对应的methods列表中
def _add_middleware(self, mw):
if hasattr(mw, 'process_request'):
self.methods['process_request'].append(mw.process_request)
if hasattr(mw, 'process_response'):
self.methods['process_response'].insert(0, mw.process_response)
if hasattr(mw, 'process_exception'):
self.methods['process_exception'].insert(0, mw.process_exception)
# 整个下载流程
def download(self, download_func, request, spider):
@defer.inlineCallbacks
def process_request(request):
# 处理request请求,依次经过各个自定义Middleware中间件的process_request方法,前面有加入到list中
for method in self.methods['process_request']:
response = yield method(request=request, spider=spider)
assert response is None or isinstance(response, (Response, Request)), \
'Middleware %s.process_request must return None, Response or Request, got %s' % \
(six.get_method_self(method).__class__.__name__, response.__class__.__name__)
# 这是关键地方
# 如果在某个Middleware中间件的process_request中处理完之后,生成了一个response对象
# 那么会直接将这个response return 出去,跳出循环,不再处理其他的process_request
# 之前我们的header,proxy中间件,都只是加个user-agent,加个proxy,并不做任何return值
# 还需要注意一点:就是这个return的必须是Response对象
# 后面我们构造的HtmlResponse正是Response的子类对象
if response:
defer.returnValue(response)
# 如果在上面的所有process_request中,都没有返回任何Response对象的话
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









