








Hadoop概述— Hadoop简介 •什么是Hadoop 一个开源、高可靠、可扩展 的分布式计算框架• 解决的问题 海量数据的存储(HDFS) 海量数据的分析(MapReduce) 分布式资源调度(Yarn)• 产生背景 受Google三篇论文的启发(GFS、MapReduce、BigTable)• 扩容能力 能可靠地存储和处理千兆字节(PB)数据。• 成本低 可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。• 高效率 通过分发数据,Hadoop可以在数据所在的节点上并行地处理它们,这使得处理非常的快速。• 可靠性 Hadoop能自动维护数据的多份副本,并且在任务失败后能自动重新部署。
Hadoop概述— Hadoop生态圈
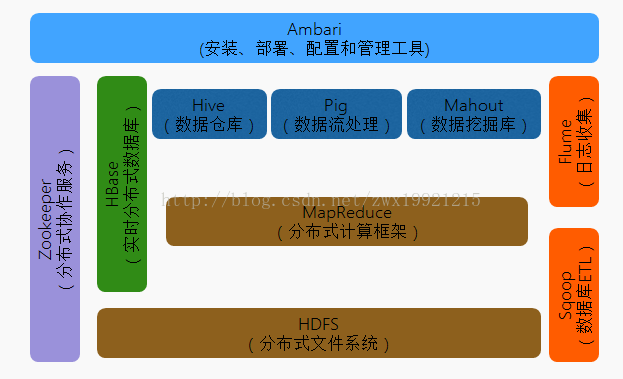
Hadoop概述— Hadoop核心
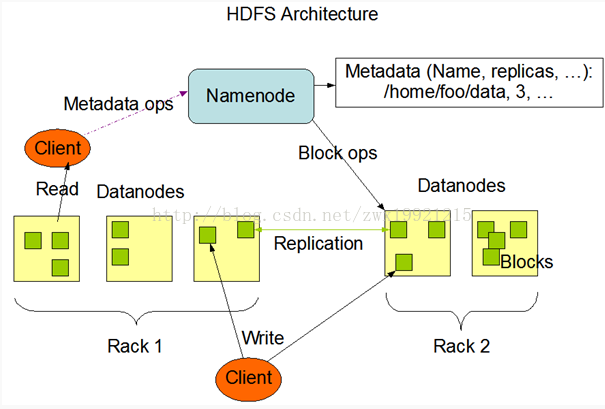
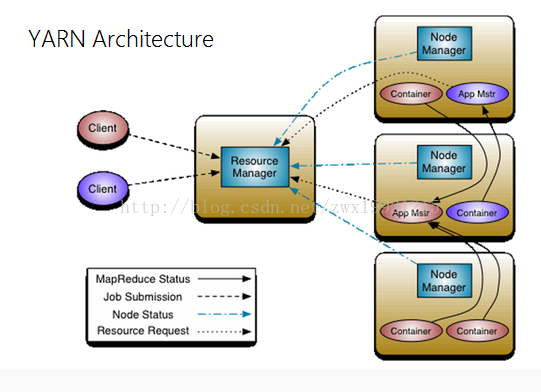
• Hadoop项目主要包括以下四个模块• Hadoop Common: 为其他Hadoop模块提供基础设施。• Hadoop HDFS: 一个高可靠、高吞吐量的分布式文件系统• Hadoop MapReduce: 一个分布式的离线并行计算框架•Hadoop YARN: 一个新的MapReduce框架,任务调度与资源管理
分布式离线计算框架 —- MapReduce
• Map任务处理
① 读取输入文件内容,解析成key、value对
② 重写map方法,编写业务逻辑输出新的key、value对
③ 对输出的key、value进行分区。(Partitioner类)
④对数据按照key进行排序、分组。相同key的value放到一个集合中。
• Reduce任务处理
①对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
②对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
③把reduce的输出保存到文件中。
Hadoop前置环境安装 — Linux环境准备
•关闭防火墙(chkconfig iptables off)•禁用SELinux (cd /etc/sysconfig/selinux 设置SELINUX=disable)•修改ip•修改hostname ( vi /etc/sysconfig/network 设置hostname=m1)•ip和主机名的对应(vi /etc/hosts 插入一行:192.168.0.102 m1)•设置ssh自动登录 ssh配置: 1.生成秘钥:ssh-keygen -t rsa 2.ssh-copy-id 192.168.0.102 3.测试:ssh 192.168.0.102
Haoop前置环境安装 — 安装JDK
•下载解压http://download.oracle.com/otn-pub/java/jdk/7u80-b15/jdk-7u80-linux-x64.tar.gz•将java添加到环境变量中 vim /etc/profile #在文件最后添加 export JAVA_HOME /usr/local/program/jdk1.7.0_55 export PATH=$PATH:$JAVA_HOME/bin•刷新配置source /etc/profile
Hadoop前置环境安装– lrzsz命令
• 安装linux上传下载命令:yum install –y lrzsz• 注:如果出现错误Error: Cannot find a valid baseurl for repo: base执行如下操作:vi /etc/resolv.conf在此文件最后加入:nameserver 8.8.8.8安装成功后:执行 rz 命令即可
Hadoop伪分布式安装 — Hadoop运行模式
• 本地模式 所有Hadoop的守护进程运行在一个JVM中• 伪分布式 所有Hadoop的守护进程各自运行在自己的JVM中(一台机器)• 集群模式 多台机器来搭建分布式集群,每个进程运行在独立的JVM中,并对 Namenode和ResourceManager做Ha配置
编译hadoop2.7.2源码
1.上传所需文件 *Maven 3.0 or later* Findbugs 1.3.9 (if running findbugs)* ProtocolBuffer 2.5.02.解压maven和findbugs,并配置环境变量3.编译protocolbuffer•安装make命令以及一些其他的依赖• 输入命令: yum -y install autoconf automake libtool cmake ncurses-devel openssl-devel lzo-devel zlib-devel gcc gcc-c++ 4.输入命令configure5.Make install6.cd hadoop-2.7.2-src 执行命令:mvn package -Pdist,native,docs -DskipTests –Dtar7.编译需要30min左右
Hadoop伪分布式配置安装文档
根据官网文档安装:
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/SingleCluster.html
注意点:
1.core-site.xml中添加配置,修改临时目录:
hadoop.tmp.dir = /usr/local/program/hadoop-2.7.2/data/tmp














 2615
2615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









