




 本文深入解析MySQL中select和update语句的执行流程,涵盖连接建立、查询缓存、解析优化、存储引擎交互及数据返回全过程。同时,阐述了redolog与binlog在更新操作中的作用及两阶段提交机制,确保数据一致性。
本文深入解析MySQL中select和update语句的执行流程,涵盖连接建立、查询缓存、解析优化、存储引擎交互及数据返回全过程。同时,阐述了redolog与binlog在更新操作中的作用及两阶段提交机制,确保数据一致性。
一条SQL语句的执行流程
前言
本文基于MySQL5.7版本。
前面几篇MySQL系列的文章介绍了索引,事务和锁相关知识,那么今天就让我们来看看当我们执行一条select语句和一条update语句的时候,MySQL要经过哪些步骤,才能返回我们想要的数据。
一条select语句的执行流程
MySQL从大方向来说,可以分为 Server 层和存储引擎层。而Server层包括连接器、查询缓存、解析器、预处理器、优化器、执行器等,最后Server层再通过API接口形式调用对应的存储引擎层提供的接口。如下图所示(图片来源于《高性能MySQL》):
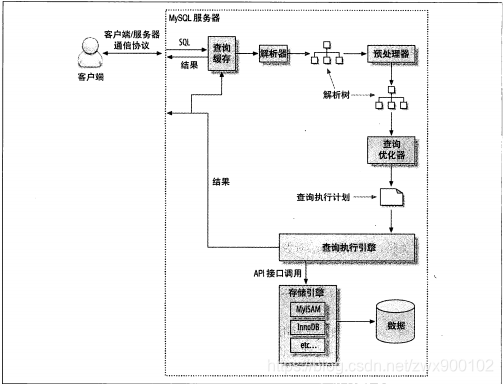
根据流程图,一条select查询大致经过以下六个步骤:
1、客户端发起一个请求时,首先会建立一个连接
2、服务端会检查缓存,如果命中则直接返回,否则继续之后后面步骤
3、服务器端根据收到的sql语句进行解析,然后对其进行词法分析,语法分析以及预处理
4、由优化器生成执行计划
5、调用存储引擎层API来执行查询
6、返回查询到的结果
查询流程也可以通过如下图表示(图片来源于丁奇MySQL45讲):
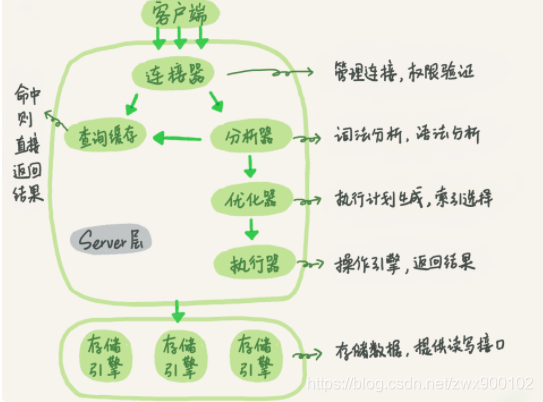
建立连接
第一步建立连接,这个很容易理解,需要特别指出的是MySQL服务端和客户端的通信方式采用的是半双工协议。
通信方式主要可以分为三种:单工,半双工,全双工,如下图:
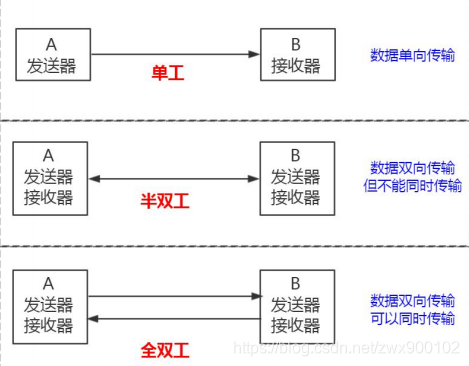
- 单工:通信的时候,数据只能单向传输。比如说遥控器,我们只能用遥控器来控制电视机,而不能用电视机来控制遥控器。
- 半双工:通信的时候,数据可以双向传输,但是同一时间只能有一台服务器在发送数据,当A给B发送数据的时候,那么B就不能给A发送数据,必须等到A发送结束之后,B才能给A发送数据。比如说对讲机。
- 全双工:通信的时候,数据可以双向传输,并且可以同时传输。比如说我们打电话或者用通信软件进行语音和视频通话等。
半双工协议让MySQL通信简单快速,但是也在一定程度上限制了MySQL的性能,因为一旦从一端开始发送数据,另一端必须要接收完全部数据才能做出响应。所以说我们批量插入的时候尽量拆分成多次插入而不要一次插入太大数据,同样的查询语句最好也带上limit限制条数,避免一次返回过多数据。
MySQL单次传输数据包的大小可以通过参数max_allowed_packet控制,默认大小为4MB
SHOW VARIABLES LIKE 'max_allowed_packet';

查询缓存
连接上了之后,如果缓存是打开的,那么就会进入查询缓存阶段,可以通过如下命令查看缓存是否开启:
SHOW VARIABLES LIKE 'query_cache_type';
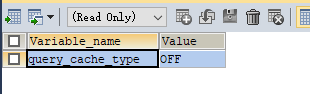
我们可以看到,缓存默认是关闭的。这是因为MySQL的缓存使用条件非常苛刻,是通过一个大小写敏感的哈希值去匹配的,这样就是说一条查询语句哪怕只是有一个空格不一致,都会导致无法使用缓存。而且一旦表里面有一行数据变动了,那么关于这种表的所有缓存都会失效。所以一般我们都是不建议使用缓存,MySQL最新的8.0版本已经将缓存模块去掉了。
解析器和预处理器
跳过了缓存模块之后,查询语句会进入解析器进行解析。
词法解析和语法解析(Parser)
这一步主要的工作就是检查sql语句的语法对不对,在这里,首先会把我们整个SQL语句打碎,比如:select name from test where id=1,就会被打散成select,name,from,test,where,id,=,1 这8个字符,并且能识别出关键字和非关键字,然后根据sql语句生成一个数据结构,也叫做解析树(select_lex),如下图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











