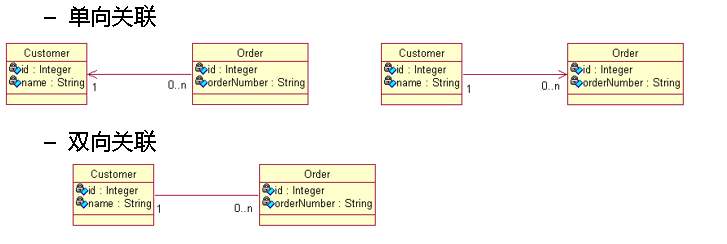
一对多关联关系
•
在领域模型中
,
类与类之间最普遍的关系就是关联关系
.
•
在
UML
中
,
关联是有方向的
.
–
以
Customer
和
Order
为例:一个用户能发出多个订单
,
而一个订单只能属于一个客户
.
从
Order
到
Customer
的关联是多对一关联
;
而从
Customer
到
Order
是一对多关联
单向 n-1
•
单向
n-1
关联只需从
n
的一端可以访问
1
的一端
•
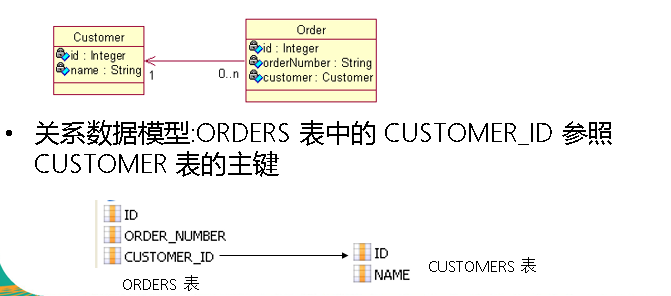
域模型
:
从
Order
到
Customer
的多对一单向关联需要在
Order
类中定义一个
Customer
属性
,
而在
Customer
类中无需定义存放
Order
对象的集合属性
•
显然无法直接用
property
映射
customer
属性
•
Hibernate
使用
<many-to-one>
元素来映射多对一关联关系
<many-to-one name="customer" class="Customer" column="CUSTOMER_ID" not-null="true"/>
many-to-one
•
<many-to-one>
元素来映射组成关系
–
name:
设定待映射的持久化类的属性的名字
–
column:
设定和持久化类的属性对应的表的外键
–
class
:设定待映射的持久化类的属性的类型
–
save方法时:先插入1的一端,再插入n的一端,只有insert语句
如果先插入N的一端,则会多出update语句,因为没有依赖的id
select方法:
1》查N的一端,不会查一的一端
2》在需要使用到关联对象时,才发送对应的sql语句
3》由多的一端导航到1的一端时,若session被关闭,则默认情况下,则会发生懒加载异常
4》获取Order对象时,默认情况下,其关联的Customer对象是一个代理对象!
在未设定级联关系的情况下,且1这一端的对象有N的对象引用,不能直接删除1这一端的对象
双向 1-n
•
双向
1-n
与双向
n-1
是完全相同的两种情形
•
双向
1-n
需要在
1
的一端可以访问
n
的一端
,
反之依然
.
•
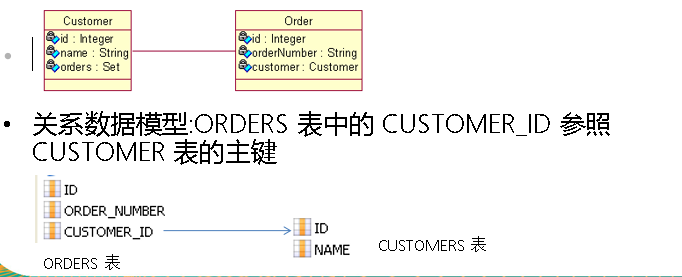
域模型
:
从
Order
到
Customer
的多对一双向关联需要在
Order
类中定义一个
Customer
属性
,
而在
Customer
类中需定义存放
Order
对象的集合属性
多对一举例:先插入1端1个,再插N端2个。3条insert,2条update(需要检查一遍)
先插N端2个,再插入1端1个,3条insert,4条update。
因为1的一端和N的一端都维护关联关系,所以会多出update。可以通过inverse属性来设置维护方
在set节点指定inverse=true使得1的一端放弃维护关联关系,建议先插1的一端。
1》声明集合类型时,需使用接口类型,因为hibernate在获取集合类型时,返回的是hibernate内置的集合类型(会延迟加载),而不是JavaSE的标准集合类型。
2》需要把集合 类量进行初始化,避免空指针问题
3》session断了也会抛出懒加载异常。
4》在需要使用集合中元素的时候进行初始化。
•
当
Session
从数据库中加载
Java
集合时
,
创建的是
Hibernate
内置集合类的实例
,
因此
在持久化类中定义集合属性时必须把属性声明为
Java
接口类型
–
Hibernate
的内置集合类具有集合代理功能
,
支持延迟检索策略
–
事实上
,Hibernate
的内置集合类封装了
JDK
中的集合类
,
这使得
Hibernate
能够对缓存中的集合对象进行脏检查
,
按照集合对象的状态来同步更新数据库。
•
在定义集合属性时
,
通常把它初始化为集合实现类的一个实例
.
这样可以提高程序的健壮性
,
避免应用程序访问取值为
null
的集合的方法抛出
NullPointerException
private Set<Order> orders = new HashSet<Order>();
public Set<Order> getOrders(){
return orders;
}
public void setOrders(Set<Order> orders){
this.orders = orders;
}
•Hibernate 使用<set>元素来映射set类型的属性
<set name="orders">
<key column="CUSTOMER_ID"></key>
<one-to-man class="Order"/>
</set>
set
•
<
set
>元素来映射
持久化类的
set
类型的属性
–
name:
设定待映射的持久化类的属性的
key
•
<
key
>元素
设定与所关联的持久化类对应的表的外键
–
column:
指定关联表的外键名
one-to-many
•
<
one-to-many
>元素
设定集合属性中所关联的持久化类
–
class:
指定关联的持久化类的类名
<set>元素的inverse属性
•
在
hibernate
中通过对
inverse
属性的来决定是由双向关联的哪一方来维护表和表之间的关系
.inverse = false
的为主动方,
inverse= true
的为被动方
,
由主动方负责维护关联关系
•
在没有设置
inverse=true
的情况下,父子两边都维护父子
关系
•
在
1-n
关系中,将
n
方设为主控方将有助于性能改善
(
如果要国家元首记住全国人民的名字,不是太可能,但要让全国人民知道国家元首,就容易的多
)
•
在
1-N
关系中,若将
1
方设为主控方
–
会额外多出
update
语句
。
–
插入数据时无法同时插入外键列,因而无法为外键列添加非空约束
cascade属性(开发时不建议设定该属性,建议使用手工)
•
在对象
–
关系映射文件中
,
用于映射持久化类之间关联关系的元素
,<set>, <many-to-one>
和
<one-to-one>
都有一个
cascade
属性
,
它用于指定如何操纵与当前对象关联的其他对象
.

在数据库中对集合排序
•
<set>
元素有一个
order-by
属性
,
如果设置了该属性
,
当
Hibernate
通过
select
语句到数据库中检索集合对象时
,
利用
orderby
子句进行排序
•
order-by
属性中还可以加入
SQL
函数
举例:<set order-by="表的字段名称_name desc">
映射一对一关联关系
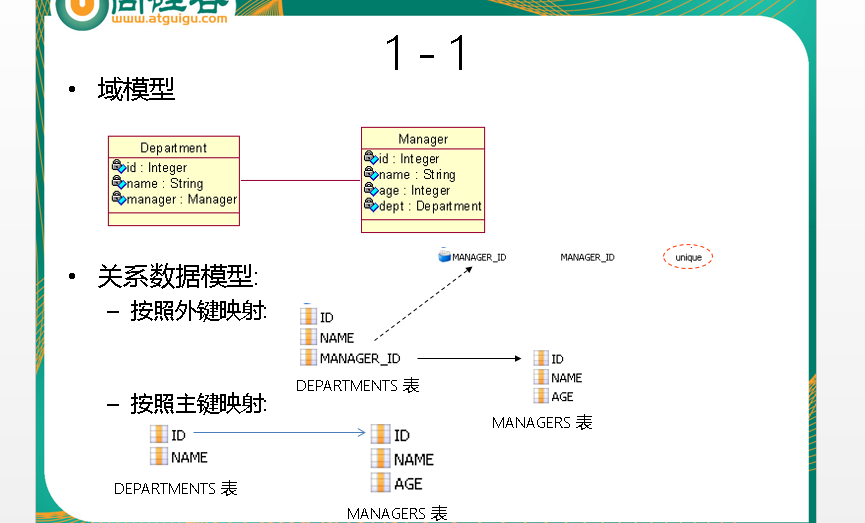
基于外键映射的 1-1

1》默认情况下对关联属性使用懒加载
2》所以会出现懒加载异常的问题。
没有外键的一端需要shiyongone-to-one元素,并使用property-ref属性指定使用被关联实体主键以外的字段作为管理字段。M端指定D端的一个非主键的 类字段
在查询没有外键的实体对象(M端),使用左外连接查询,一并查询出其管理的对象,并初始化。
两边都使用外键映射的 1-1
会造成混乱。
基于主键映射的 1-1
•
基于主键的映射策略
:
指一端的主键生成器使用
foreign
策略
,
表明根据
”对方”
的主键来生成自己的主键,自己并不能独立生成主键
.<
param
>
子元素指定
使用
当前持久化类的哪个属性作为
“对方”
•<id name="id" column="ID" type="integer">
<generator class="foreign">
<param name="property">manager</param>
</generator>
</id>
•
•
采用
foreign
主键生成器策略的一端增加
one-to-one
元素映射关联属性,其
one-to-one
属性还应增加
constrained=“true”
属性;另一端增加
one-to-one
元素映射关联属性。
•
constrained
(
约束
):
指定为当前持久化类对应的数据库表的主键添加一个外键约束,引用被关联的对象
(
“
对方”
)
所对应的数据库表主键
•<one-to-ont name="manager" class="Manager" constrained="true"/>
save()方法:D端没有主键,M端被先插入。
查询是左连接
映射多对多关联关系
单向 n-n
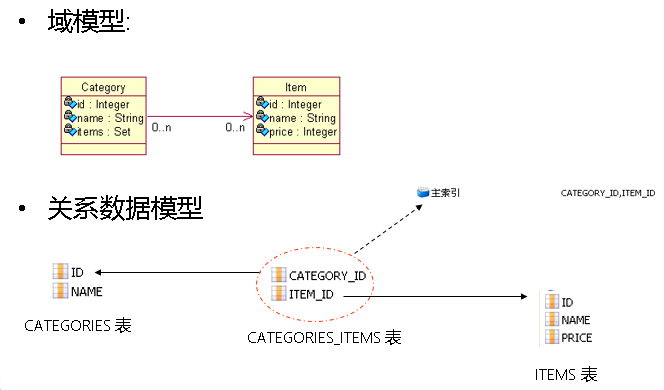
单向 n-n
•n-n 的关联必须使用连接表
•与 1-n 映射类似,必须为 set 集合元素添加 key 子元素,指定 CATEGORIES_ITEMS 表中参照 CATEGORIES 表的外键为 CATEGORIY_ID.与1-n关联映射不同的是,建立n-n关联时,集合中的元素使用many-to-many.many-to-many 子元素的 class属性指定items集合中存放的是Item对象,column 属性指定 CATEGORIES_ITEMS 表中参照 ITEMS 表的外键为 ITEM_ID

查询会连接中间表
双向 n-n
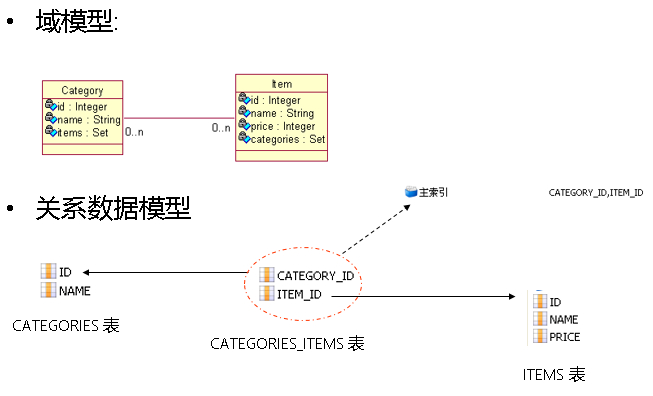
•
双向
n-n
关联需要
两端都使用集合属性
•
双向
n-n
关联
必须使用连接表
•
集合属性应增加
key
子元素用以映射外键列
,
集合元素里还应增加
many-to-many
子元素关联实体类
•
在双向
n-n
关联的两边都需指定连接表的表名及外键列的列名
.
两个集合元素
set
的
table
元素的值必须指定,而且必须相同
。
set
元素的两个子元素:
key
和
many-to-many
都必须指定
column
属性
,其中,
key
和
many-to-many
分别指定本持久化类和关联类在连接表中的外键列名,因此两边的
key
与
many-to-many
的
column
属性交叉相同
。
也就是说,一边的
set
元素的
key
的
cloumn
值为
a,many
-to-many
的
column
为
b
;则另一边的
set
元素的
key
的
column
值
b,many
-to-many
的
column
值为
a.
•
对于双向
n-n
关联
,
必须把其中一端的
inverse
设置为
true
,
否则两端都维护关联关系可能会造成主键冲突
.
 继承映射
继承映射
•
对于面向对象的程序设计语言而言,继承和多态是两个最基本的概念。
Hibernate
的继承映射可以理解持久化类之间的继承关系
。例如:人和学生之间的关系。学生继承了人,可以认为学生是一个特殊的人,如果对人进行查询,学生的实例也将被得到。
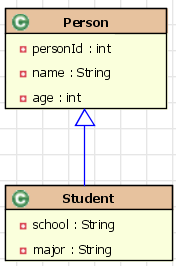
•
Hibernate
支持三种继承映射策略:
–
使用
subclass
进行映射
:
将域模型中的每一个实体对象映射到一个独立的表中,也就是说不用在关系数据模型中考虑域模型中的继承关系和多态。
–
使用
joined-subclass
进行映射
:
对于继承关系中的子类使用同一个表,这就需要在数据库表中增加额外的区分子类类型的字段。
–
使用
union-subclass
进行映射
:域模型中的每个类映射到一个表,通过关系数据模型中的外键来描述表之间的继承关系。这也就相当于按照域模型的结构来建立数据库中的表,并通过外键来建立表之间的继承关系。
•
采用 subclass元素的继承映射
•
采用
subclass
的继承映射可以实现对于继承关系中
父类和子类使用同一张表
•
因为父类和子类的实例全部保存在同一个表中,因此
需要在该表内增加一列
,使用该列来区分每行记录到低是哪个类的实例
----
这个列被称为辨别者列
(
discriminator
).
•
在这种映射策略下,
使用
subclass
来映射子类
,
使用
class
或
subclass
的
discriminator-value
属性指定辨别者列的值
•
所有子类定义的字段都不能有非空约束
。如果为那些字段添加非空约束,那么父类的实例在那些列其实并没有值,这将引起数据库完整性冲突,导致父类的实例无法保存到数据库中
•
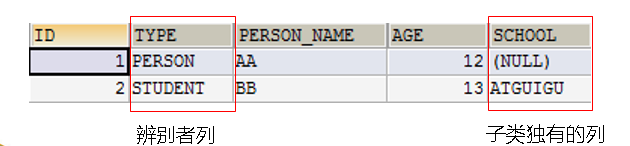
1》对于子类对象只需把记录插入到一张数据表中。
2》辨别者列由Hibernate自动维护
查询父类,子类,只需查一张表。
缺点:1》使用了辨别者列。2》子类独有的字段不能呢个添加非空约束3》若继承层次较深,则数据表的字段也会较多。
 采用
joined-subclass
元素的继承映射
采用
joined-subclass
元素的继承映射
•
采用
joined-subclass
元素的继承映射可以实现
每个子类一张表
•
采用这种映射策略时,父类实例保存在父类表中,
子类实例由父类表和子类表共同存储
。因为子类实例也是一个特殊的父类实例,因此必然也包含了父类实例的属性。于是将子类和父类共有的属性保存在父类表中,子类增加的属性,则保存在子类表中。
•
在这种映射策略下,无须使用鉴别者列,但需要为每
个子类使用
key
元素映射共有主键
。
•
子类增加的属性可以添加非空约束
。因为子类的属性和父类的属性没有保存在同一个表中

插入操作:1》子类表对象最少插入两张表,性能降低
查询:1》查询父类记录,做一个左连接;2查询子类记录,做内连接
优点:1》不需要辨别者列;2》子类独有字段可以使用非空约束;3》没有冗余字段。
采用 union-subclass元素的继承映射
•
采用
union-subclass
元素可以实现
将每一个实体对象映射到一个独立的表中
。
•
子类增加的属性可以有非空约束
---
即父类实例的数据保存在父表中,而子类实例的数据保存在子类表中。
•
子类实例的数据仅保存在子类表中
,
而在父类表中没有任何记录
•
在这种映射策略下,子类表的字段会比父类表的映射字段要多
,
因为子类表的字段等于父类表的字段、加子类增加属性的总和
•
在这种映射策略下,
既不需要使用鉴别者列,也无须使用
key
元素来映射共有主键
.
•
使用
union-subclass
映射策略是不可使用
identity
的主键生成策略
,
因为同一类继承层次中所有实体类都需要使用同一个主键种子
,
即多个持久化实体对应的记录的主键应该是连续的
.
受此影响
,
也不该使用
native
主键生成策略
,
因为
native
会根据数据库来选择使用
identity
或
sequence.

插入性能不错
查父类需把父表和子表记录汇总到一起再做查询,性能稍差。
对于子类记录,也只需要查询一张数据表
优点:1》无需辨别者;2》子类独有字段可非空
缺点:1》存在冗余字段,2》若更新父表的字段,则更新的效率较低


继承映射用的不多























 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









