








创建索引优化、写入流程核心概念讲解
一、索引刷新间隔调整:refresh_interval
默认情况下索引的refresh_interval为1秒,这意味着数据写1秒后就可以被搜索到,每次索引的 refresh 会产生一个新的 lucene 段,这会导致频繁的 segment merge 行为,如果你不需要这么高的搜索实时性,应该降低索引refresh 周期(即你可能想优化索引速度而不是近实时搜索, 可以通过设置 refresh_interval , 降低每个索引的刷新频率),如:
PUT /my_logs
{
"settings": {
"refresh_interval": "30s" # 每30秒刷新 my_logs 索引
}
}
# refresh_interval 可以在既存索引上进行动态更新。
# 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,
# 待开始使用该索引时,再把它们调回来
PUT /my_logs/_settings
{
"refresh_interval": -1 # 关闭自动刷新
}
PUT /my_logs/_settings
{
"refresh_interval": "1s" # 每秒自动刷新
}
二、事务日志操作间隔调整:translog flush
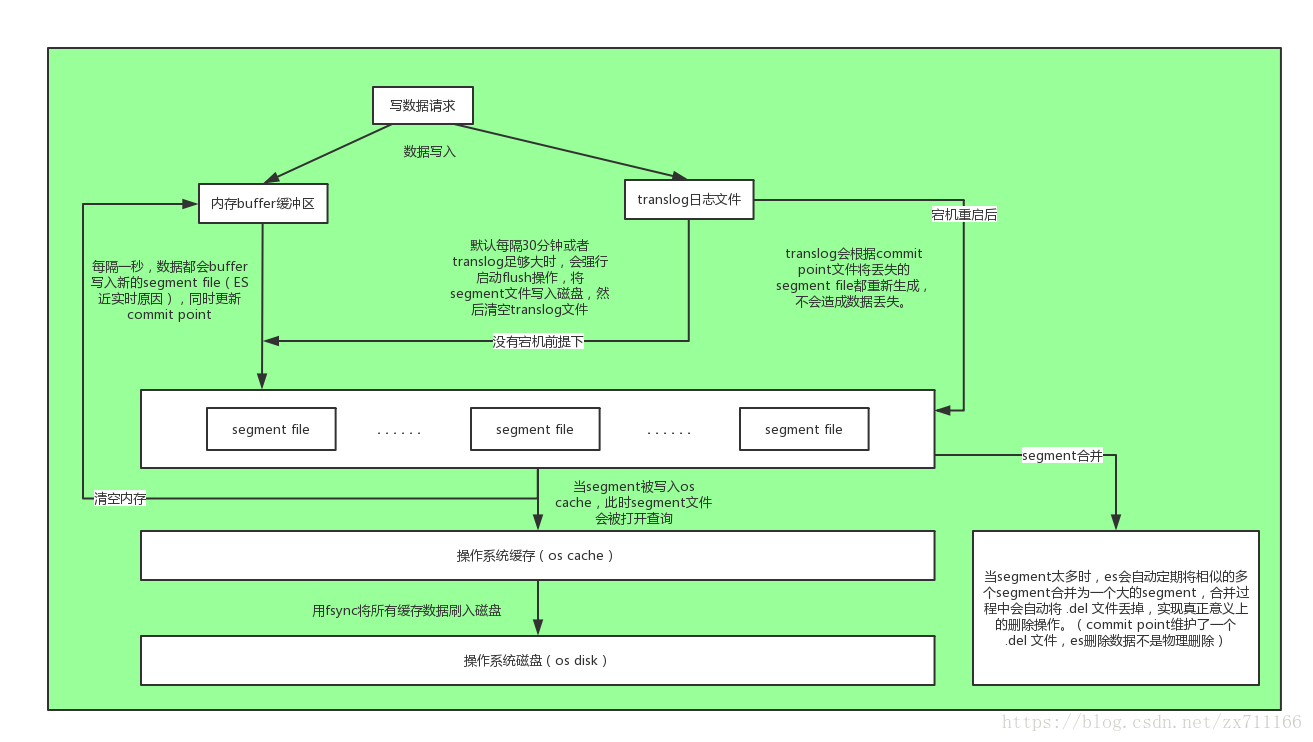
- translog是elasticsearch的事务日志文件,它记录了所有对索引分片的事务操作(add/update/delete),每个分片对应一个 translog 文件。
- translog是用来恢复数据的。Es用 “后写” 的套路来加快写入速度 — 写入的索引并没有实时落盘到索引文件,而是先双写到 内存 和 translog 文件,有三种状态(可搜索 & 未落盘 & 已写日志) 。如果掉电,es重启后还可以把数据从日志文件中读回来。
从 es 2.x 开始, 默认设置下,translog 的持久化策略为:每个请求都flush.对应配置项为:
/*
* 每操作都写(默认策略),可靠性最高。
* 如果你不确定这个行为的后果,
* 最好是使用默认的参数( "index.translog.durability": "request")
* 来避免数据丢失
*/
index.translog.durability: request
这是影响 es 写入速度的最大因素.但是只有这样,写操作才有可能是可靠的,原因参考写入流程。
如果系统可以接受一定几率的数据丢失,调整 translog 持久化策略为周期性和一定大小的时候 flush:
index.translog.durability: async //异步刷新
index.translog.sync_interval: 120s //间隔120s异步刷新(设置后无法更改)
index.translog.flush_threshold_size: 1024mb //内容容量到达1gb异步刷新
三、segment merge
segment merge 操作对系统 CPU 和 IO 占用都比较高,从es 2.0开始,merge 行为不再由 es 控制,而是转由 lucene 控制,因此以下配置已被删除:
indices.store.throttle.type
indices.store.throttle.max_bytes_per_sec
index.store.throttle.type
index.store.throttle.max_bytes_per_sec
改为以下调整开关:
/* 最大线程数的默认值为:
* Math.max(1,Math.min(4,Runtime.getRuntime().availableProcessors()/2))
* 是一个比较理想的值,如果你只有一块硬盘并且非 SSD, 应该把他设置为1,
* 因为在旋转存储介质上并发写,由于寻址的原因,不会提升,只会降低写入速度。
*/
index.merge.scheduler.max_thread_count: 1
/* merge 策略有三种:
* tiered(默认情况)、log_byete_size、log_doc
* 索引创建时合并策略就已确定,不能更改,但是可以动态更新策略参数,
* 一般情下,不需要调整.如果堆栈经常有很多 merge, 可以尝试调整以下配置。
*/
index.merge.polcy.type: tiered
/* 该属性用于阻止segment 的频繁flush, 小于此值将考虑优先合并,
* 默认为2M,可考虑适当降低此值。
*/
index.merge.policy.floor_segment: 2m
/* 一次最多只操作多少个segments,默认是10。*/
index.merge.policy.max_merge_at_once: 10
/* 显示调用optimize 操作或者 expungeDeletes时可以操作多少个segments,默认是30。*/
index.merge.policy.max_merge_at_once_explicit: 30
/* 超过多大size的segment不会再做merge(即指定了单个 segment 的最大容量),默认是5g。*/
index.merge.policy.max_merged_segment: 5g
/* 每个tier允许的segement 数,注意这个数要大于上面的at_once数,否则这个值会先于最大可操作数到达,就会立刻做merge,这样会造成频繁。
*/
index.merge.policy.segments_per_tier: 12
/* 考虑merge的segment 时删除文档数量多少的权重,默认即可*/
index.reclaim_deletes_weight
/* 是否设定compound format格式。
* compound format在基于文件的存储中能降低打开文件的句柄数目。默认设置是false,不启用。
* 因为non compound format性能较好。所以OS分配给es足够多的file handle是及其重要的。
* 另外:compound_format可以设置一个在0--1之间的数值。
* 0代表false,1代表true,中间值代表一个百分比:如果合并的segment小于总体的这个百分比,
* 那将会写成compound format,否则写成compound format。
*/
index.compound_format: false
总结
写入数据时涉及的核心概念有三个:
- segment file: 存储逆向索引的文件,每个segment本质上就是一个逆向索引,每秒都会生成一个segment文件,当文件过多时es会自动进行segment merge(合并文件),合并时会同时将已经标注删除的文档物理删除;
- commit point(重点理解): 记录当前所有可用的segment,每个commit point都会维护一个.del文件(es删除数据本质是不属于物理删除),当es做删改操作时首先会在.del文件中声明某个document已经被删除,文件内记录了在某个segment内某个文档已经被删除,当查询请求过来时在segment中被删除的文件是能够查出来的,但是当返回结果时会根据commit point维护的那个.del文件把已经删除的文档过滤掉;
- translog日志文件: 为了防止elasticsearch宕机造成数据丢失保证可靠存储,es会将每次写入数据同时写到translog日志中(图中会有详解)。
Java APi设置示例
ElasticsearchConfig中的setting设置的是全局变量,上述的参数设置不适合在这里设置,否者将会报这样的java.lang.IllegalArgumentException: node settings must not contain any index level settings.
即在全局层面5.x不支持索引级别的设置,即5.x不支持index.refresh_interval配置,且名字也变更了,5.x只支持的Settings配置如下:
| 配置 | 说明 |
|---|---|
| cluster.name | 集群name |
| client.transport.sniff | 是否支持自动嗅探 |
| client.transport.ignore_cluster_name | 设置为true忽略连接节点的群集名称验证。(自0.19.4以来) |
| client.transport.ping_timeout | 等待来自节点的ping响应的时间。默认值为5s。 |
| client.transport.nodes_sampler_interval | 采样/ ping列出和连接的节点的频率。默认值为5s。 |
@Configuration
public class ElasticsearchConfig {
private static final Logger LOGGER = LoggerFactory.getLogger(ElasticsearchConfig.class);
/**
* elk集群地址
*/
@Value("${elasticsearch.host}")
private String hostName;
/**
* 端口
*/
@Value("${elasticsearch.port}")
private String port;
/**
* 集群名称
*/
@Value("${elasticsearch.cluster.name}")
private String clusterName;
/**
* 连接池
*/
@Value("${elasticsearch.pool}")
private String poolSize;
@Bean
public TransportClient init() {
TransportClient transportClient = null;
try {
// 配置信息
Settings esSetting = Settings.builder()
.put("cluster.name", clusterName)
.put("client.transport.sniff", true)// 增加嗅探机制,找到ES集群
.put("thread_pool.search.size", Integer.parseInt(poolSize))// 增加线程池个数,暂时设为5
.put("thread_pool.bulk.size", 5)
.build();
transportClient = new PreBuiltTransportClient(esSetting);
InetSocketTransportAddress inetSocketTransportAddress = new InetSocketTransportAddress(
InetAddress.getByName(hostName), Integer.valueOf(port));
transportClient.addTransportAddresses(inetSocketTransportAddress);
} catch (Exception e) {
LOGGER.error("elasticsearch TransportClient create error!!!", e);
}
return transportClient;
}
}
@Test
public void test1() throws Exception {
final String projectId = "ec53c48e-a3bc-4cc1-a46e-b93e17124f5d";
final String indexName = "tcp_435bf7ef-8a69-4da3-a3bf-4f174b7b4861";
List<IndexTableEntity> indexTableList = indexTableRepo.findByProjectId(projectId);
JSONArray jsonArray = createTable(indexTableList);
List<Column> colsList = jsonArray.toJavaList(Column.class);
esUtils.createPhyTable2(colsList, indexName, false);
}
private JSONArray createTable(List<IndexTableEntity> indexTableList) {
JSONArray jsonArray = new JSONArray();
for (IndexTableEntity indexTable : indexTableList) {
JSONObject json = new JSONObject();
json.put("colName", indexTable.getFieldName());
json.put("colType", TransformType.transformType(indexTable.getFieldType()));
json.put("showName", indexTable.getFieldNote());
jsonArray.add(json);
}
return jsonArray;
}
public void createPhyTable(List<Column> columnList, String indexName, boolean flag) {
if (!existTable(indexName)) {
// 创建索引
Settings esSetting = Settings.builder()
.put("index.refresh_interval", "30s")
.put("index.translog.durability", "async")
.put("index.translog.sync_interval", "30s")
.put("index.translog.flush_threshold_size", "1gb")
.put("index.merge.scheduler.max_thread_count", 1)
.build();
//下面的两种提交方式选择一种即可
//prepareCreate准备创建索引,增加setSetting()方法可以设置setting参数,否则将会按默认设置
client.admin().indices().prepareCreate(indexName).setSettings(esSetting).execute().actionGet();
//CreateIndexRequest request = new CreateIndexRequest(indexName, esSetting);
//client.admin().indices().create(request).actionGet();
}
// 创建索引结构
XContentBuilder builder = null;
try {
builder = XContentFactory.jsonBuilder().startObject().startObject(indexName).startObject("_all")
.field("enabled", false).endObject().startObject("_source").field("enabled", false).endObject()
.startObject("properties");
for (Column colume : columnList) {
builder.startObject(colume.getColName());
if (ColType.TEXT == colume.getColType().intValue()) {
builder.field("type", "keyword");
builder.field("index", "not_analyzed").endObject();
} else if (ColType.NUMBER == colume.getColType().intValue()) {
builder.field("type", "double");
builder.field("index", "not_analyzed").endObject();
} else if (ColType.DATE == colume.getColType().intValue()) {
builder.field("type", "date").field("format", "yyyy/MM/dd||yyyy/MM/dd HH:mm:ss");
builder.field("index", "not_analyzed").endObject();
}
}
builder.endObject().endObject().endObject();
} catch (IOException e) {
LOGGER.error("创建索引结构失败: " + indexName);
throw new RuntimeException("创建索引结构失败: " + indexName, e);
}
//更新索引属性(更新索引的settings属性,这是更改已经创建的属性、但有些一旦创建不能更改,需要按照自己的需求来进行选择使用)
/*client.admin().indices().prepareUpdateSettings(indexName)
.setSettings(Settings.builder()
.put("index.refresh_interval", "30s") //索引刷新间隔调整
.put("index.translog.durability", "async")
.put("index.translog.flush_threshold_size", "1gb")
.put("index.merge.scheduler.max_thread_count", 1))
.execute().actionGet();*/
PutMappingRequest mapping = Requests.putMappingRequest(indexName).type(indexName).source(builder);
client.admin().indices().putMapping(mapping).actionGet();
if (LOGGER.isInfoEnabled()) {
LOGGER.info("Create Index Structure Succeed:" + indexName);
}
}
测试结果
连接远程Elasticsearch
第一批次、单节点es,创建索引优化的写入性能(25000条数据的指标写入时间):
2018-08-08 09:25:29.629 INFO 7868 --- [ main] c.y.d.t.es.util.ElasticsearchUtilsTest : Started ElasticsearchUtilsTest in 9.704 seconds (JVM running for 10.441)
2018-08-08 09:25:30.463 INFO 7868 --- [ main] c.y.d.s.impl.IndexTableServiceImpl : importDateV1 ##### 调用DAService保存数据开始 ##### index: tcp_435bf7ef-8a69-4da3-a3bf-4f174b7b4861
2018-08-08 09:25:32.766 INFO 7868 --- [ main] c.y.d.tools.es.util.ElasticsearchUtils : ##### 调用ES BULK 批量插入25000条数据结束 ##### 时间: 2107
2018-08-08 09:25:32.893 INFO 7868 --- [ main] c.y.d.s.impl.IndexTableServiceImpl : importDateV1 ##### 调用DAService保存数据开始 ##### index: tcp_435bf7ef-8a69-4da3-a3bf-4f174b7b4861
2018-08-08 09:25:34.375 INFO 7868 --- [ main] c.y.d.tools.es.util.ElasticsearchUtils : ##### 调用ES BULK 批量插入25000条数据结束 ##### 时间: 1434
2018-08-08 09:25:34.476 INFO 7868 --- [ main] c.y.d.s.impl.IndexTableServiceImpl : importDateV1 ##### 调用DAService保存数据开始 ##### index: tcp_435bf7ef-8a69-4da3-a3bf-4f174b7b4861
2018-08-08 09:25:36.011 INFO 7868 --- [ main] c.y.d.tools.es.util.ElasticsearchUtils : ##### 调用ES BULK 批量插入25000条数据结束 ##### 时间: 1159
2018-08-08 09:25:36.049 INFO 7868 --- [ main] c.y.d.s.impl.IndexTableServiceImpl : importDateV1 ##### 调用DAService保存数据开始 ##### index: tcp_435bf7ef-8a69-4da3-a3bf-4f174b7b4861
2018-08-08 09:25:36.988 INFO 7868 --- [ main] c.y.d.tools.es.util.ElasticsearchUtils : ##### 调用ES BULK 批量插入25000条数据结束 ##### 时间: 920
2018-08-08 09:25:37.023 INFO 7868 --- [ main] c.y.d.s.impl.IndexTableServiceImpl : importDateV1 ##### 调用DAService保存数据开始 ##### index: tcp_435bf7ef-8a69-4da3-a3bf-4f174b7b4861
2018-08-08 09:25:38.131 INFO 7868 --- [ main] c.y.d.tools.es.util.ElasticsearchUtils : ##### 调用ES BULK 批量插入25000条数据结束 ##### 时间: 1090
2018-08-08 09:25:38.138 INFO 7868 --- [ Thread-3] o.s.w.c.s.GenericWebApplicationContext : Closing org.springframework.web.context.support.GenericWebApplicationContext@7fee8714: startup date [Wed Aug 08 09:25:20 CST 2018]; root of context hierarchy
2018-08-08 09:25:38.140 INFO 7868 --- [ Thread-3] o.s.c.support.DefaultLifecycleProcessor : Stopping beans in phase 2147483647
2018-08-08 09:25:39.978 INFO 7868 --- [ Thread-3] j.LocalContainerEntityManagerFactoryBean : Closing JPA EntityManagerFactory for persistence unit 'default'
连接本地Elasticsearch
第一批次、单节点es,创建索引优化的写入性能(25000条数据的指标写入时间):
2018-08-08 09:29:31.754 INFO 18020 --- [ main] c.y.d.t.es.util.ElasticsearchUtilsTest : Started ElasticsearchUtilsTest in 9.838 seconds (JVM running for 10.609)
2018-08-08 09:29:32.380 INFO 18020 --- [ main] c.y.d.s.impl.IndexTableServiceImpl : importDateV1 ##### 调用DAService保存数据开始 ##### index: tcp_435bf7ef-8a69-4da3-a3bf-4f174b7b4861
2018-08-08 09:29:33.821 INFO 18020 --- [ main] c.y.d.tools.es.util.ElasticsearchUtils : ##### 调用ES BULK 批量插入25000条数据结束 ##### 时间: 1279
2018-08-08 09:29:33.980 INFO 18020 --- [ main] c.y.d.s.impl.IndexTableServiceImpl : importDateV1 ##### 调用DAService保存数据开始 ##### index: tcp_435bf7ef-8a69-4da3-a3bf-4f174b7b4861
2018-08-08 09:29:34.998 INFO 18020 --- [ main] c.y.d.tools.es.util.ElasticsearchUtils : ##### 调用ES BULK 批量插入25000条数据结束 ##### 时间: 975
2018-08-08 09:29:35.232 INFO 18020 --- [ main] c.y.d.s.impl.IndexTableServiceImpl : importDateV1 ##### 调用DAService保存数据开始 ##### index: tcp_435bf7ef-8a69-4da3-a3bf-4f174b7b4861
2018-08-08 09:29:36.150 INFO 18020 --- [ main] c.y.d.tools.es.util.ElasticsearchUtils : ##### 调用ES BULK 批量插入25000条数据结束 ##### 时间: 895
2018-08-08 09:29:36.188 INFO 18020 --- [ main] c.y.d.s.impl.IndexTableServiceImpl : importDateV1 ##### 调用DAService保存数据开始 ##### index: tcp_435bf7ef-8a69-4da3-a3bf-4f174b7b4861
2018-08-08 09:29:37.123 INFO 18020 --- [ main] c.y.d.tools.es.util.ElasticsearchUtils : ##### 调用ES BULK 批量插入25000条数据结束 ##### 时间: 916
2018-08-08 09:29:37.162 INFO 18020 --- [ main] c.y.d.s.impl.IndexTableServiceImpl : importDateV1 ##### 调用DAService保存数据开始 ##### index: tcp_435bf7ef-8a69-4da3-a3bf-4f174b7b4861
2018-08-08 09:29:38.146 INFO 18020 --- [ main] c.y.d.tools.es.util.ElasticsearchUtils : ##### 调用ES BULK 批量插入25000条数据结束 ##### 时间: 964
2018-08-08 09:29:38.154 INFO 18020 --- [ Thread-3] o.s.w.c.s.GenericWebApplicationContext : Closing org.springframework.web.context.support.GenericWebApplicationContext@7fee8714: startup date [Wed Aug 08 09:29:22 CST 2018]; root of context hierarchy
2018-08-08 09:29:38.157 INFO 18020 --- [ Thread-3] o.s.c.support.DefaultLifecycleProcessor : Stopping beans in phase 2147483647
2018-08-08 09:29:39.878 INFO 18020 --- [ Thread-3] j.LocalContainerEntityManagerFactoryBean : Closing JPA EntityManagerFactory for persistence unit 'default'














 604
604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









