







为什么要使用fiddler
最近爬了好多网站,每个网站的访问方式、翻页方式都各有特色,每次我都要在第一步卡很长时间,这个时候正确使用抓包工具就是很有必要的了。
因为我们爬虫其实就是模拟浏览器去访问网站,而抓包工具是监测我们访问网站的,我们可以用浏览器访问一次即将要爬取的网站,然后在fiddler中查看http请求行的数据,如headers内容、data内容等,然后模仿浏览器访问的这些数据。 只要我们程序的http请求和正确访问时的数据是一样的,我们的结果一定返回的是正确的页面。
如果我们获取的不是我们想要的结果,就还是要和正确的做对比。
fiddler常用的功能介绍
查看访问网站的一些数据
下图是我访问网站时,fiddler展示的界面
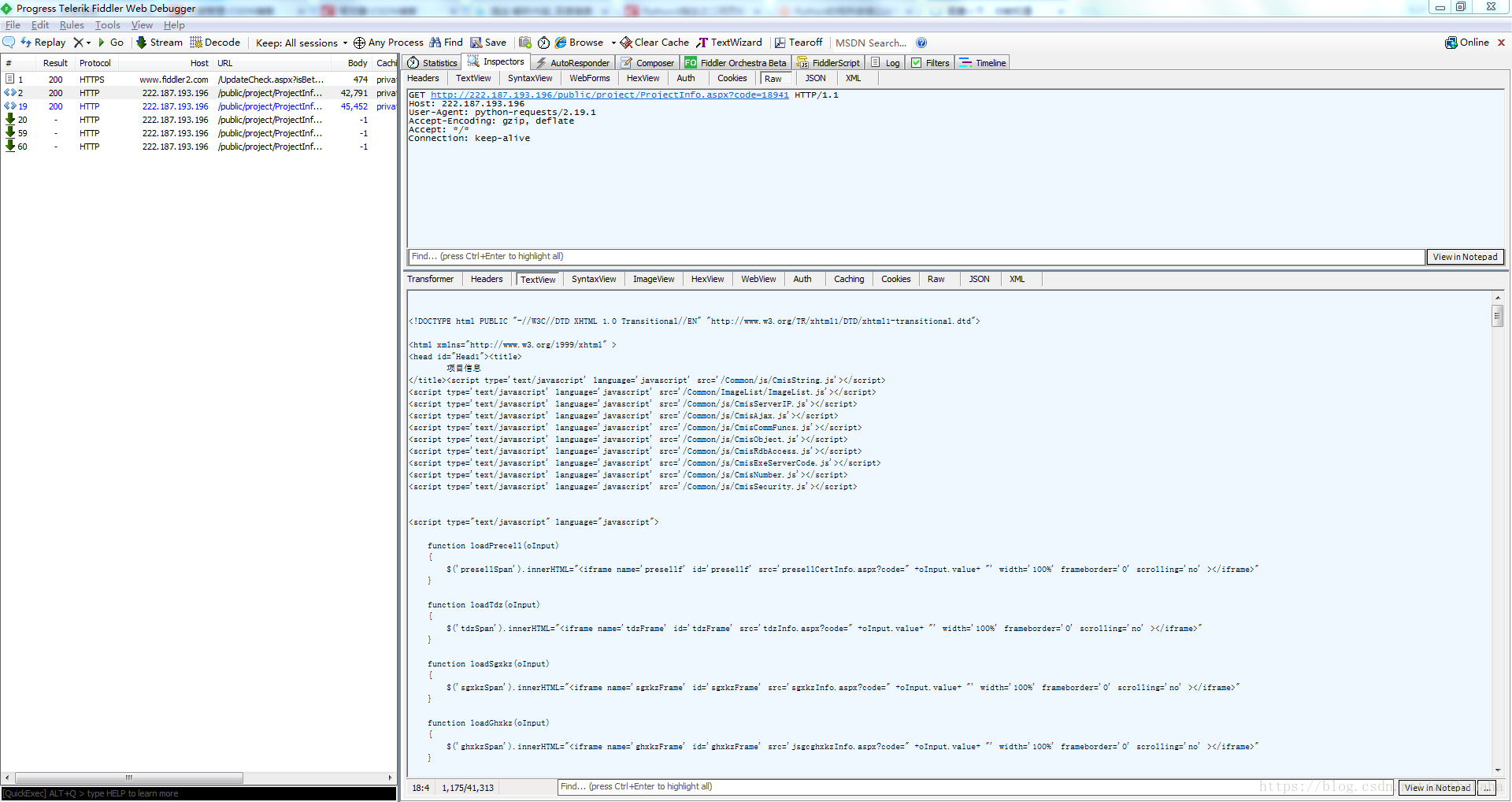
① 我们访问了哪些网站?
fiddler的左侧白色背景那一栏就向我们展示了我们访问了哪些网站,包括用浏览器访问的和我们自己用程序访问的。
当我们点击某一具体网站时,右侧会展示关于访问此网址的具体信息。
②网站的内容在哪里看?
右侧下方的区域就是有此网站的内容,其中我常用到的两个为webview和textview。webview展示的就是你在此网站当前看到的页面,即你用浏览器打开
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2244
2244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









