







目录
- 第一题:顺时针打印矩阵
- 第二题:包含min函数的栈
- 第三题:栈的压入、弹出序列
- 第四题:从上往下打印二叉树
- 第五题:二叉搜索树的后序遍历序列
- 第六题:二叉树中和为某一值的路径
第一题:顺时针打印矩阵
原题链接
题目:
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如,如果输入如下矩阵: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 则依次打印出数字1,2,3,4,8,12,16,15,14,13,9,5,6,7,11,10.
解析:
这个题目解析可以看这篇博客,那篇博客我画了一个图。
这个题目考察的是我们从宏观上面看待问题的想法,每次打印一个矩阵,然后缩小矩阵的范围,代码如下:
//考察的是一个从宏观上看问题的角度
public ArrayList<Integer> printMatrix(int [][] matrix) {
if(matrix == null || matrix.length == 0 || matrix[0].length == 0)
return null;
ArrayList<Integer>res = new ArrayList<>();
int ar = 0,ac = 0,br = matrix.length - 1,bc = matrix[0].length - 1;
while(ar <= br && ac <= bc)
print(ar++,ac++,br--,bc--,matrix,res);
return res;
}
private void print(int ar,int ac,int br,int bc,int[][] matrix,ArrayList<Integer>res){
if(ar == br){
for(int j = ac; j <= bc; j++)
res.add(matrix[ar][j]);
}else if(ac == bc){
for(int i = ar; i <= br; i++)
res.add(matrix[i][ac]);
}else {
for(int j = ac; j < bc; j++)
res.add(matrix[ar][j]);
for(int i = ar; i < br; i++)
res.add(matrix[i][bc]);
for(int j = bc; j > ac; j--)
res.add(matrix[br][j]);
for(int i = br; i > ar; i--)
res.add(matrix[i][ac]);
}
}
第二题:包含min函数的栈
题目链接
题目:
定义栈的数据结构,请在该类型中实现一个能够得到栈最小元素的min函数。
解析:
准备两个栈,stackData存储数据,stackMin存储每一步的最小值。
下面看压入和弹出元素的操作:
思路一:
压入数据的规则
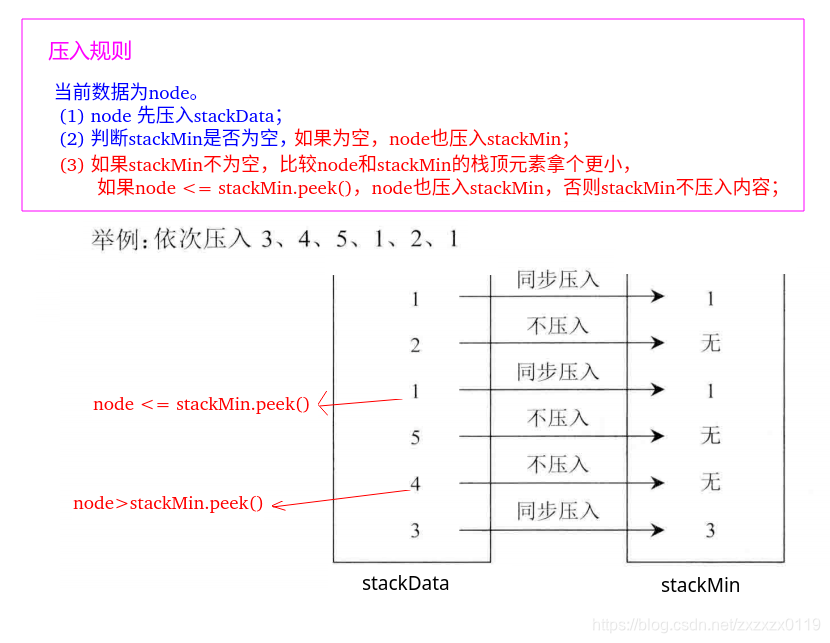
弹出数据规则
- 先在stackData中弹出栈顶元素,记为top,然后比较top和stackMin的栈顶元素,看哪个更小;
- 因为stackMin中存的是从栈底到栈顶逐渐变小的,stackMin栈顶的元素既是stackMin中的最小值,也是stackData中的最小值,所以top 只可能 >= stackMin.peek();
- 当top = stackMin.peek()的时候,stackMin弹出栈顶元素; top > stcakMin.peek()的时候,不做任何操作;最后返回top;
- 上面那样做的目的就是对应压入的时候,因为当node > stackMin.peek()的时候我们没有压入stackMin任何东西,所以当top>stackMin.peek()的时候也不要弹出;
import java.util.Stack;
public class Solution {
Stack<Integer>stackData = new Stack<>();// 数据栈
Stack<Integer>stackMin = new Stack<>();// 辅助栈
public void push(int node) {
stackData.push(node);
if(stackMin.isEmpty()){
stackMin.push(node);
}else {
if(node <= stackMin.peek()){
stackMin.push(node);
}
}
}
public void pop() {
int top = stackData.pop();
if(top == stackMin.peek())
stackMin.pop();
}
public int top() {
if(stackData.isEmpty())
throw new RuntimeException("stack is empty!");
return stackData.peek();
}
public int min() {
if(stackMin.isEmpty())
throw new RuntimeException("stack is empty!");
return stackMin.peek();
}
}
思路二;
压入规则:
弹出规则:
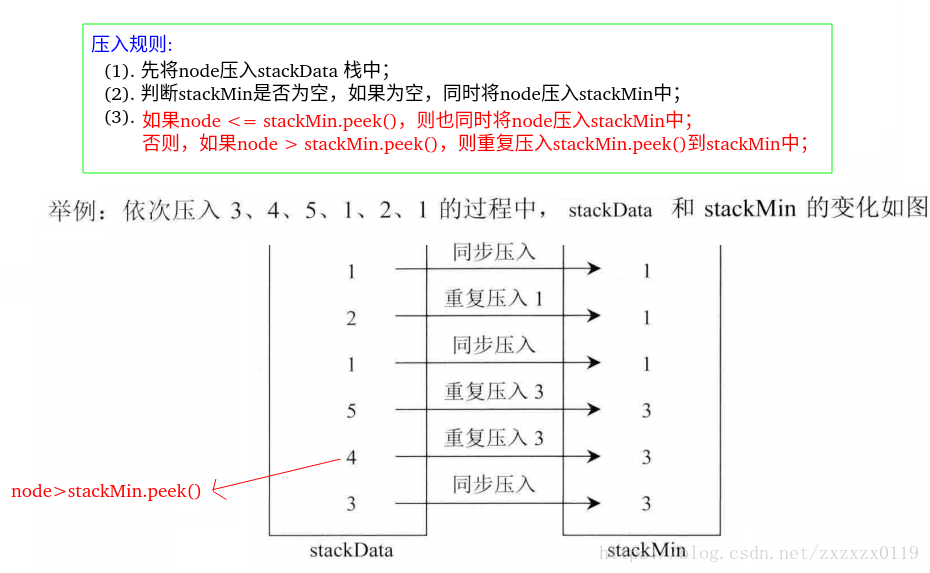
- 这个比思路一更加方便,两个栈都弹出即可;
import java.util.Stack;
public class Solution {
Stack<Integer>stackData = new Stack<>();// 数据栈
Stack<Integer>stackMin = new Stack<>();// 辅助栈
public void push(int node) {
stackData.push(node);
if(stackMin.isEmpty()){
stackMin.push(node);
}else {
if(node <= stackMin.peek()){
stackMin.push(node);
}else {//压入时候唯一的改动
stackMin.push(stackMin.peek());
}
}
}
public void pop() {
stackData.pop();
stackMin.pop();
}
public int top() {
if(stackData.isEmpty())
throw new RuntimeException("stack is empty!");
return stackData.peek();
}
public int min() {
if(stackMin.isEmpty())
throw new RuntimeException("stack is empty!");
return stackMin.peek();
}
}
第三题:栈的压入、弹出序列
题目链接
题目:
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)
解析:
- 思路一: 遍历pushA,使用一个索引popIndex下标记录popA走到的位置,如果pushA[i] = popA[popIndex],则不做处理popIndex++,如果不相等,就入栈pushA[i],最后全部弹栈,每弹一个,就看stack.pop() == popA[popIndex],如果不等,就返回false,否则返回true;
- 思路二: 还是使用一个栈,首先不管,遍历pushA[i] 的时候先入栈,然后判断栈中元素的栈顶和pop[popIndex]是否相等,如果一直相等就一直弹栈,且popIndex++,最后看栈是否为空。
思路二例子:
两种思路如果不能理解就画一个简单的例子即可。

import java.util.Stack;
public class Solution {
public boolean IsPopOrder(int[] pushA,int[] popA) {
Stack<Integer>stack = new Stack<>();
int popIndex = 0;
for(int i = 0; i < pushA.length; i++){
if(pushA[i] == popA[popIndex])
popIndex++;
else {
stack.push(pushA[i]);
}
}
while(!stack.isEmpty()){
if(stack.pop() != popA[popIndex++])
return false;
}
return true;
}
}
思路二:
import java.util.Stack;
public class Solution {
public boolean IsPopOrder(int[] pushA,int[] popA) {
Stack<Integer>stack = new Stack<>();
int popIndex = 0;
for(int i = 0; i < pushA.length; i++){
stack.push(pushA[i]); //先入栈
while( !stack.isEmpty() && stack.peek() == popA[popIndex]){
stack.pop();
popIndex++;
}
}
return stack.isEmpty();
}
}
第四题:从上往下打印二叉树
题目链接
题目:
从上往下打印出二叉树的每个节点,同层节点从左至右打印。
解析:
简单的层次遍历,不过要注意空指针异常,不要返回一个null。
public ArrayList<Integer> PrintFromTopToBottom(TreeNode root) {
ArrayList<Integer>res = new ArrayList<>();
if(root != null){
Queue<TreeNode>queue = new LinkedList<>();
queue.add(root);
TreeNode cur = null;
while(!queue.isEmpty()){
cur = queue.poll();
res.add(cur.val);
if(cur.left != null)
queue.add(cur.left);
if(cur.right != null)
queue.add(cur.right);
}
}
return res;
}
第五题:二叉搜索树的后序遍历序列
题目链接
题目:
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则输出Yes,否则输出No。假设输入的数组的任意两个数字都互不相同。
解析:
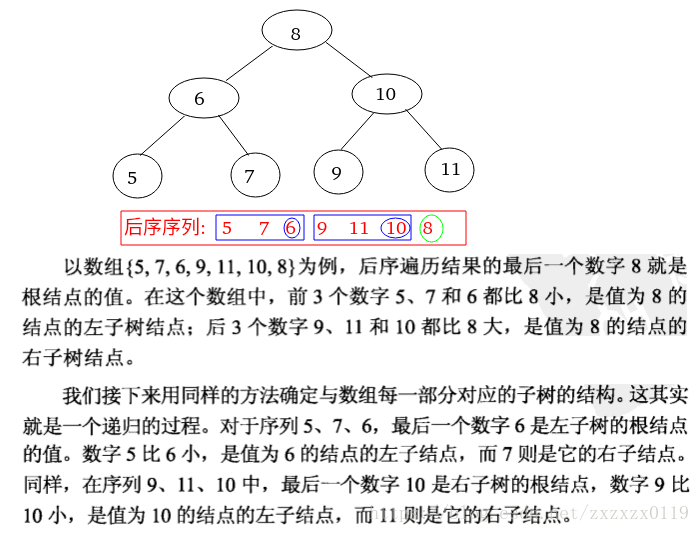
- 在后序遍历得到的序列中,最后一个数字是树的根节点的值: root;
- 二叉搜索树的后序遍历数组可以划分为两部分;
- 第一部分是左子树结点的值,它们都比根节点的值小;
- 第二部分是右子树结点的值,它们都比根节点的值大;
- 所以按照上面的方法,递归的时候,每次先确定根root,然后在[L,R]范围内每次先找到mid(第一个>root的位置,后面的就是右子树,必须要全部>root);
反例:

public boolean VerifySquenceOfBST(int[] sequence) {
if(sequence == null || sequence.length == 0)
return false;
return process(sequence,0,sequence.length - 1);
}
private boolean process(int[] seq,int L,int R){
if( L >= R )// 前面的已经满足条件
return true;
int root = seq[R];
int i = L;
// 找到左子树 --> 左右子树的分界
while(i <= R-1 && seq[i] < root)
i++;
int mid = i; // seq[mid] > root 从mid开始是右子树,必须都>root
while(i <= R-1){
if(seq[i] < root)
return false;
i++;
}
return process(seq,L,mid-1) && process(seq,mid,R-1); //左右两边都是满足条件的
}
第六题:二叉树中和为某一值的路径
题目链接
题目:
输入一颗二叉树的跟节点和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。(注意: 在返回值的list中,数组长度大的数组靠前)
解析:
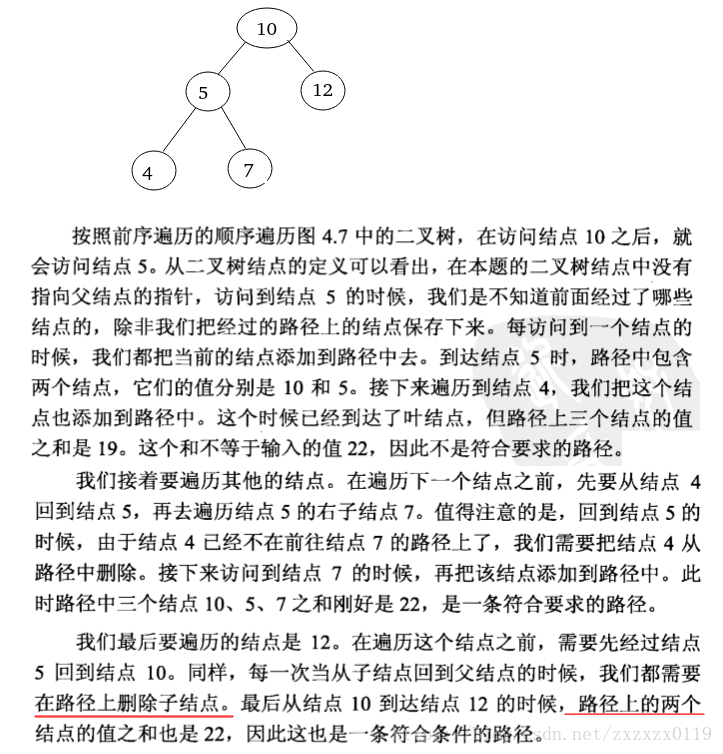
- 从根节点开始,每次先把当前结点加入path中,然后判断记录当前的总和,如果没有达到目标,就依次遍历自己的左子树和右子树;
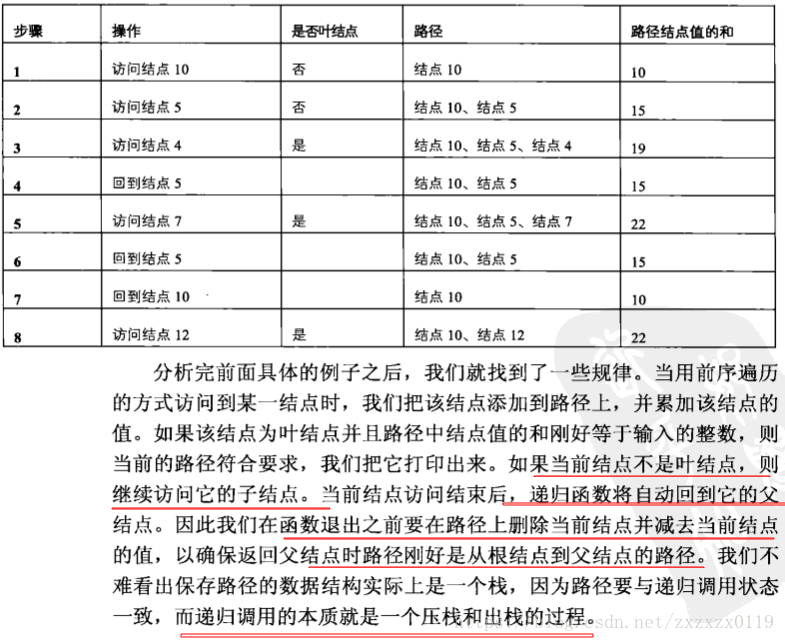
- 否则就得到一条路径,这里要注意,每次判断完这个结点之后如果没有满足条件就要把这个结点remove出去,因为当前结点访问结束后,递归函数将自动回到它的父结点。因此我们在函数退出之前要在路径上删除当前结点,以确保返回父结点时路径刚好是从根结点到父结点的路径;
例子:
具体过程以及分析:
public ArrayList<ArrayList<Integer>> FindPath(TreeNode root,int target) {
ArrayList<ArrayList<Integer>> res = new ArrayList<ArrayList<Integer>>();
if(root == null)
return res;
ArrayList<Integer>path = new ArrayList<Integer>();
process(root,0,target,path,res);
return res;
}
//前序求解
private void process(TreeNode node,int curSum,int target,ArrayList<Integer>path,ArrayList<ArrayList<Integer>> res){
if(node == null)
return ;
path.add(node.val);
if(curSum+node.val == target && node.left == null && node.right == null){//叶子结点且和 = target
//res.add(path); //这个是不对的
res.add(new ArrayList<Integer>(path));
}
process(node.left,curSum + node.val,target,path,res);
process(node.right,curSum + node.val,target,path,res);
//回溯
path.remove(path.size()-1);
}
process也可以写成这样,注意递归回溯的时候要维护curSum,减去 node.val;
//前序求解
private void process(TreeNode node,int curSum,int target,ArrayList<Integer>path,ArrayList<ArrayList<Integer>> res){
if(node == null)
return ;
curSum += node.val;
path.add(node.val);
if(curSum == target && node.left == null && node.right == null){//叶子结点且和 = target
//res.add(path); //这个是不对的
res.add(new ArrayList<Integer>(path));
}
process(node.left,curSum,target,path,res);
process(node.right,curSum,target,path,res);
//回溯
curSum -= node.val;
path.remove(path.size()-1);
}














 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









