






延迟任务有固定周期有明确出发时间,而延迟队列没有固定的开始时间它常常是由一个事件触发的,而在这个事件触发之后的一段时间内触发另一个事件,任务可以立即执行,也可以延迟。

延迟任务的应用场景:
场景一:订单下单之后30分钟后,如果用户没有付钱,则系统自动取消订单;如果期间下单成功,任务取消
场景二:接口对接出现网络问题,1分钟后重试,如果失败,2分钟重试,直到出现阈值终止
实现延迟任务的两种任务
1)DelayQueue
JDK自带DelayQueue 是一个支持延时获取元素的阻塞队列, 内部采用优先队列 PriorityQueue 存储元素,同时元素必须实现 Delayed 接口;在创建元素时可以指定多久才可以从队列中获取当前元素,只有在延迟期满时才能从队列中提取元素

DelayQueue属于排序队列,它的特殊之处在于队列的元素必须实现Delayed接口,该接口需要实现compareTo和getDelay方法
getDelay方法:获取元素在队列中的剩余时间,只有当剩余时间为0时元素才可以出队列。
compareTo方法:用于排序,确定元素出队列的顺序。
实现:
1:在测试包jdk下创建延迟任务元素对象DelayedTask,实现compareTo和getDelay方法,
2:在main方法中创建DelayQueue并向延迟队列中添加三个延迟任务,
3:循环的从延迟队列中拉取任务
public class DelayedTask implements Delayed{
// 任务的执行时间
private int executeTime = 0;
public DelayedTask(int delay){
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.SECOND,delay);
this.executeTime = (int)(calendar.getTimeInMillis() /1000 );
}
/**
* 元素在队列中的剩余时间
* @param unit
* @return
*/
@Override
public long getDelay(TimeUnit unit) {
Calendar calendar = Calendar.getInstance();
return executeTime - (calendar.getTimeInMillis()/1000);
}
/**
* 元素排序
* @param o
* @return
*/
@Override
public int compareTo(Delayed o) {
long val = this.getDelay(TimeUnit.NANOSECONDS) - o.getDelay(TimeUnit.NANOSECONDS);
return val == 0 ? 0 : ( val < 0 ? -1: 1 );
}
public static void main(String[] args) {
DelayQueue<DelayedTask> queue = new DelayQueue<DelayedTask>();
queue.add(new DelayedTask(5));
queue.add(new DelayedTask(10));
queue.add(new DelayedTask(15));
System.out.println(System.currentTimeMillis()/1000+" start consume ");
while(queue.size() != 0){
DelayedTask delayedTask = queue.poll();
if(delayedTask !=null ){
System.out.println(System.currentTimeMillis()/1000+" cosume task");
}
//每隔一秒消费一次
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}DelayQueue实现完成之后思考一个问题:
使用线程池或者原生DelayQueue程序挂掉之后,任务都是放在内存,需要考虑未处理消息的丢失带来的影响,如何保证数据不丢失,需要持久化(磁盘)
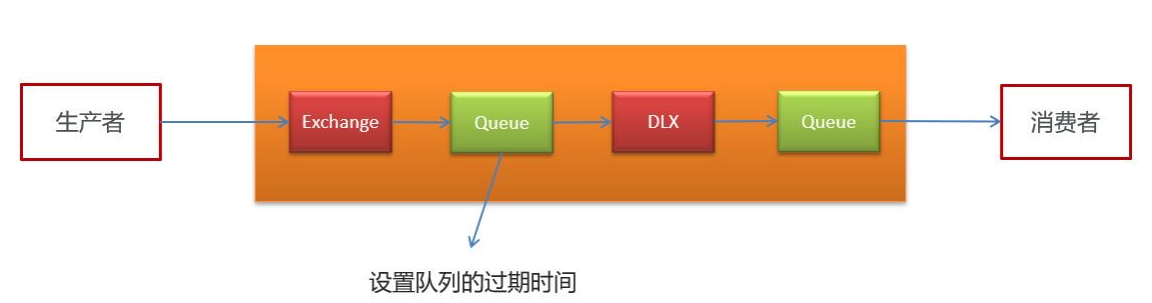
2)RabbitMQ实现延迟任务
TTL:Time To Live (消息存活时间)
死信队列:Dead Letter Exchange(死信交换机),当消息成为Dead message后,可以重新发送另一个交换机(死信交换机)。
3)redis实现
zset数据类型的去重有序(分数排序)特点进行延迟。例如:时间戳作为score进行排序。
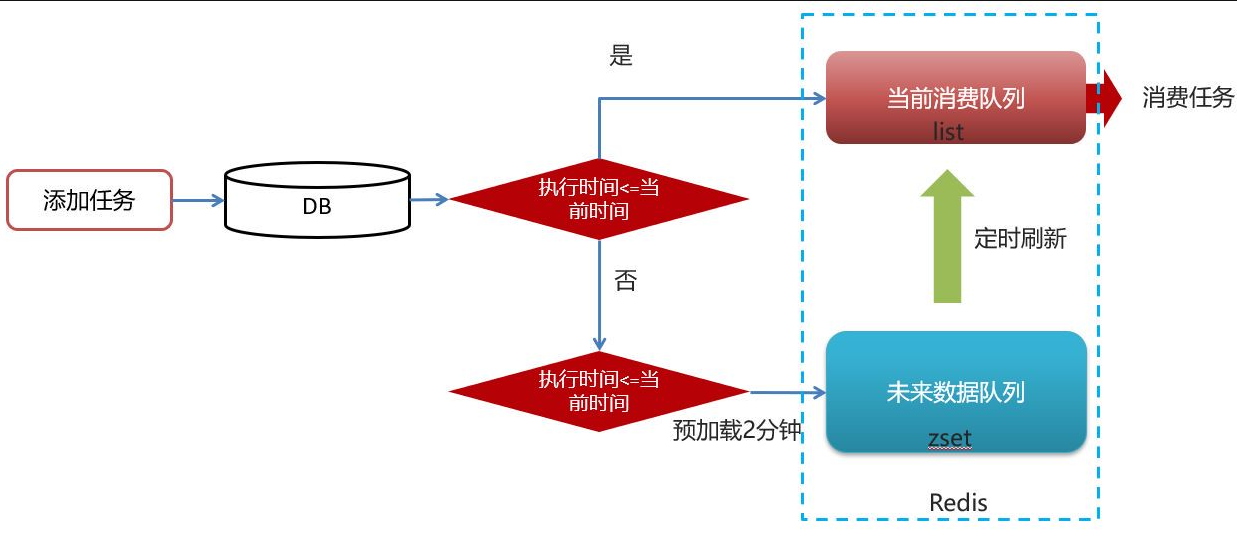
redis实现延迟任务的思路
1.为什么任务需要存储在数据库中?
延迟任务是一个通用的服务,任何需要延迟得任务都可以调用该服务,需要考虑数据持久化的问题,存储数据库中是一种数据安全的考虑。
2.为什么redis中使用两种数据类型,list和zset?
效率问题,算法的时间复杂度
3.在添加zset数据的时候,为什么不需要预加载?
任务模块是一个通用的模块,项目中任何需要延迟队列的地方,都可以调用这个接口,要考虑到数据量的问题,如果数据量特别大,为了防止阻塞,只需要把未来几分钟要执行的数据存入缓存即可。
4)延迟任务服务实现
搭建heima-leadnews-schedule模块
leadnews-schedule是一个通用的服务,单独创建模块来管理任何类型的延迟任务
①:导入资料文件夹下的heima-leadnews-schedule模块到heima-leadnews-service下,如下图所示:

②:添加bootstrap.yml
server:
port: 51701
spring:
application:
name: leadnews-schedule
cloud:
nacos:
discovery:
server-addr: 192.168.200.130:8848
config:
server-addr: 192.168.200.130:8848
file-extension: yml③:在nacos中添加对应配置,并添加数据库及mybatis-plus的配置
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/leadnews_schedule?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: root
# 设置Mapper接口所对应的XML文件位置,如果你在Mapper接口中有自定义方法,需要进行该配置
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
# 设置别名包扫描路径,通过该属性可以给包中的类注册别名
type-aliases-package: com.heima.model.schedule.pojos















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









