









目录
1 什么是Elasticsearch?
Elasticsearch是一个面向文档的实时的分布式搜索分析引擎。关于Elasticsearch与另一个搜索引擎Solr的比较看这里。
2 Elasticsearch的特点
- 反向索引又叫倒排索引,是根据文章内容中的关键字建立索引。
- 搜索引擎原理就是建立反向索引。
- Elasticsearch 在 Lucene 的基础上进行封装,实现了分布式搜索引擎。
- Elasticsearch 中的索引、类型和文档的概念比较重要,类似于 MySQL 中的数据库、表和行。
- Elasticsearch 也是 Master-slave 架构,也实现了数据的分片Shard和备份Replia。
- Elasticsearch 一个典型应用就是 ELK 日志分析系统。
关于Elasticsearch相关的系统版本和JVM版本支持(看这里)
3 Elasticsearch基础概念
- 索引(index)对应数据库
- 类型(type)对应数据库中的数据表(注意:ES6.0以后就不支持一个索引指定多个类型了,默认一个类型且不能修改)
- 文档(Document)文档是存储在ES中的一个JSON字符串,相当于数据库中表的具体数据行。
- 字段(Field)对应数据库中每一行数据的具体的列
- ID序列:ID是一个未接的唯一标识,如果在库中没有提供ID,系统会自动生成一个ID
- 映射(Mapping)代表索引的结构,类似于数据库表结构。动态映射和静态映射
- 索引模板(template): 使用索引模板
- 路由:当存储一个文档的时候,它会存储在唯一的主分片中。内部routing算法将数据路由到各个分片:shard = hash(routing) % number_of_primary_shards,
routing是一个可变值,默认是文档的_id,也可以设置成一个自定义的值,number_of_primary_shards主分片的数量
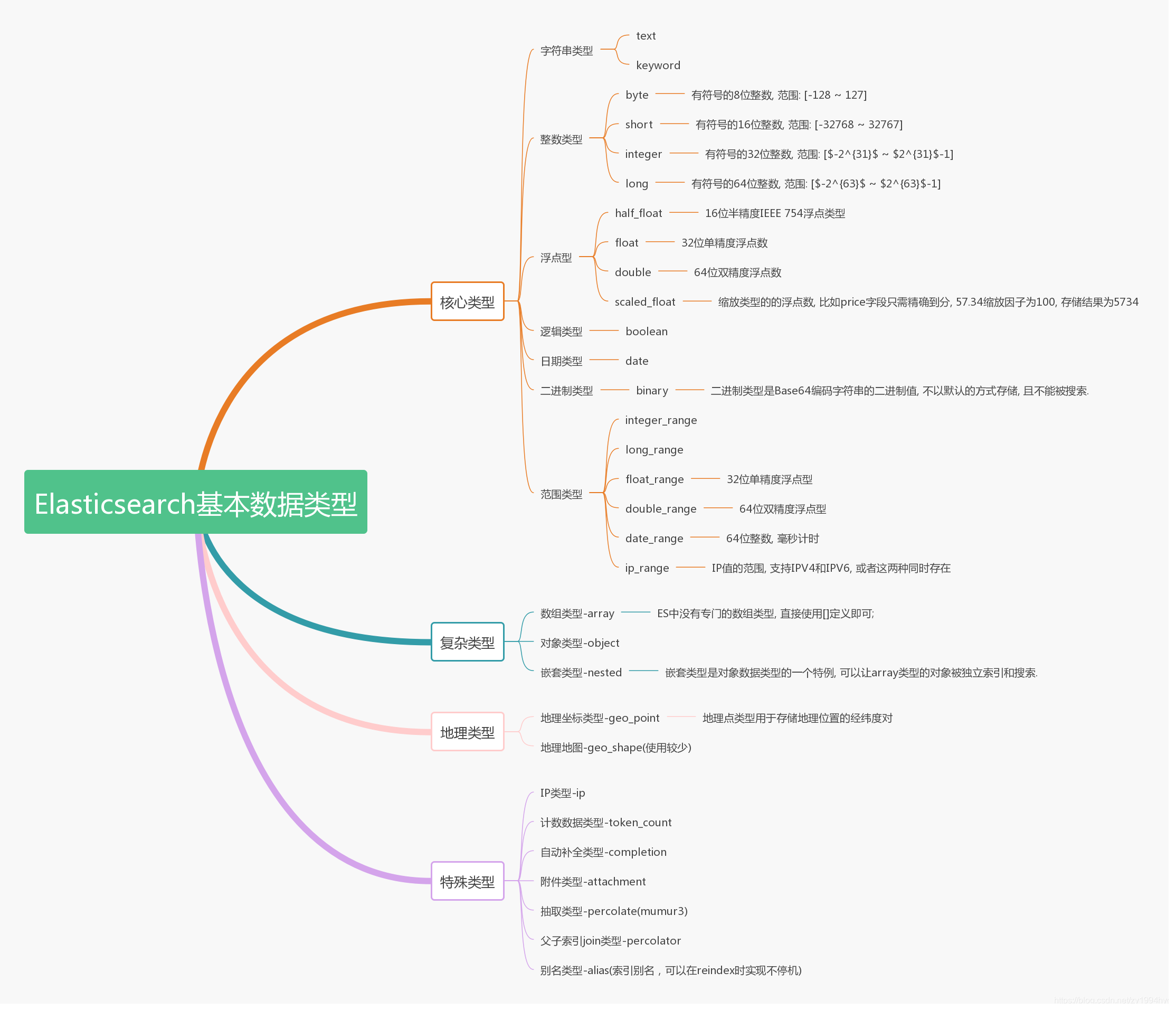
4 Elasticsearch基本数据类型(看这里)
5 Elasticsearch基本检索类型
5.1 检索和过滤
- 检索和过滤的区别(看这里)
- 检索和过滤的适用场景,针对他们的区别可以确定各自的使用场景
5.2 结构化检索
- 精确匹配检索:term查询单值精确匹配、terms查询多值精确匹配,terms_set多值匹配并且可以定义返回文档所需的匹配术语数
- 范围检索:range query(低版本用 range filter)
- 存在与否检索:exists query
- 前缀查询:prefix query
- 通配符检索:wildcard query
- 正则检索:regexp query
- 类型检索:type query
- id检索:ids query
- 模糊查询:fuzzy query,与通配符查询类似,但是fuzzy查询,当搜索条件是个不准确的单词或词时,可以自动帮助纠正后查询
5.3 全文检索
- 分词全文检索:match
- 布尔前缀检索:match_bool_prefix
- 短语检索:match_phrase
- 短语前缀检索:match_phrase_prefix
- 多字段匹配检索:multi_match
- 支持与或非的字符串检索:query_string
- 简化的字符串检索:simple_query_string
- 间隔检索:intervals
5.4 复合检索
- 固定得分检索 看这里
- bool组合检索:must、should(通过minimum_should_match指定匹配的个数)、must_not、filter 看这里
- 改变评分检索:boosting、function score、dis max query
5.5 特定检索
- 嵌套检索:nested query
- 父子检索:has_child query、has_parent query、parent_id query
- 地理检索:geo 查询 和 distance_feature query(查询更接近提供的
origin日期或时间点的数据。或者查询来查找某个位置最近的邻居) - 相似文档检索:more_like_this
- 脚本检索:script query
6 Elasticsearch基本基本聚合类型
6.1 Metric聚合
6.2 Buckting聚合
- terms按字段分组统计:terms
- 根据字段值统计:histogram
- 根据时间值统计:datehistogram
- 根据时间段统计:daterange(可以指定时间段格式和具体查询的时间区间)
- 过滤Filter聚合:filter 和 filters
- 嵌套聚合:nested
- 更多
6.3 Pipeline聚合
- bucked script聚合:bucket script
- bucked selector聚合:bucket selector
- bucked sort聚合:bucket sort
- Avg/Max/Min/Sum bucked聚合
- 更多
7 Elasticsearch基本操作类型
7.1 Elasticsearch集群基本操作
- 集群健康状态分类:green健康,yellow亚健康,red病态,集群健康可以使用 health api 查看情况
- 集群状态监控API:集群状态state、集群统计stats、集群任务管理_tasks、集群待处理任务pending_tasks、节点信息_nodes、活跃线程信息_nodes/hot_threads、更多集群api
- 集群备份:_snapshot、_restore
7.2 Elasticsearch索引基本操作
- 增:put index
- 删:delete index
- 索引数据迁移:
reindex
第三方工具:elasticsearch-dump、Elasticsearch-Exporter、logstash、elasticsearch-migration - 修改副本数,注意索引一旦创建,分片数不可更改,除非reindex
- 索引压缩:shrink
- 查:Get index、 get/index/_settings
7.3 Elasticsearch文档基本操作
- 单个文档写入:put document
批量写入:bulk写入
第三方导入:1.通过logstash导入多种数据源的数据(关系型数据库,非关系型数据库,大数据存储),2.kafka推送,3.利用flume - 单个删除:delete document
批量删除:delete-by-query - 单个修改:update 结合 script
批量修改:update-by-query - 单个检索:get
批量检索:mult get、scroll游标
- 分页:from+size
- 高亮:Unified Highlighter(默认)、plain ighlighter、fvh highlighter(适合大文件)
- 搜索推荐:Term suggester、Phrase suggester、Completion suggester、Context Suggester
- 分词:中英文分词的区别,
中文分词插件有:ik、jieba、ansj
动态更新词典策略 - 同义词词典配置
- 分析调试:profile:true
7.4 Elasticsearch常用的工具
- kibana工具:xpack提升安全
- Head浏览器插件
- cerebro监控工具
8 Elasticsearch进阶
8.1 Elasticsearch集群规划
- 节点数规划:Master主节点、Client路由节点、data数据节点
- 分片、副本规划:每个分片支持的数据量、业务数据分类梳理
- 堆内存核心原理
- 部署优化:堆内存部署优化、线程数/队列优化设置、候选主节点设置、更新中文分词词典
8.2 Elasticsearch数据建模
- 数据建模的重要性
- 数据建模的流程
8.3 Elasticsearch生命周期管理
- 基于时间轴动态创建索引(利用滚动索引和索引模板)
- 定时清理索引:curator
- 冷热数据分离
8.4 Elasticsearch写入性能优化
- Elasticsearch写入慢的原因:1.没有使用批量操作,2.使用批量操作,但值设置不合理,3.ES队列线程池设置不合理
- Elasticsearch写入提速:1. 采用bulk批量写入 2. 使用多线程写入 3. 增加refesh间隔,默认1s,每秒都会将内存的数据刷新到磁盘,如果设为30S,表示30S的数据是写入内存缓存的,30秒才将内存的数据刷新到磁盘 4. 如果搭建ES集群,禁止refresh和replica,当批量导入大数据时可以禁止副本复制操作 5. 采用自增ID
8.5 Elasticsearch检索性能优化
- Elasticsearch检索慢的原因:
1)索引设置不合理(如所有数据写入一个固定索引)
2)Mapping映射字段设置不合理
3)DSL设置不合理,有优化空间,如:wildcard
4)返回字段非常多,如:cont/html_cont
5)慢日志查询
6)监控集群状态:cpu、内存、磁盘使用情况判断是否是硬件原因,确认是否有并行写入等 - Elasticsearch检索提速:
1)先确认哪里慢了?利用 profile:true 分析
通过在query部分上方提供“profile: true”来启用Profile API。
2)如果是硬件层面,直接扩展硬件GET /ljjtest/book/_search { "profile":"true", "query":{ "match":{ "author":"鲁迅" } } }
3)数据层面:提前数据建模、减少检索字段、Mapping优化、避免使用script、使用近似日期、只读数据force_merge、范围检索使用keyword而非range
4)缓存方面:使用独立缓存系统,preference优化缓存使用率
8.6 Elasticsearch磁盘读写优化
8.7 Elasticsearch插件开发
9 Elasticsearch实践
- Elasticsearch日志分析:借助ELK可视化分析
- Elasticsearch全文检索,做搜索引擎














 1286
1286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









