







最大熵模型
最大熵模型是运用了最大熵思想的多分类模型,那就先理解什么叫最大熵!
熵
熵代表随机变量的不确定性,熵越大代表随便变量越不确定。
最大熵的思想
当我们猜测一个概率分布,如果对其分布一无所知,则选择熵最大的均匀分布,如果有一定的先验知识,那么就选择满足这些条件的熵最大的分布.
核心思想:保留全部不确定性,将风险降到最小
模型的推导
从训练集T中抽取特征,然后求这些特征在训练集中的经验分布 P ~ ( X , Y ) \widetilde P(X,Y) P (X,Y)的期望,等于模型P(Y|X)与经验分布 P ~ ( X ) \widetilde P(X) P (X)的期望值. 特征函数 f ( x , y ) f(x,y) f(x,y)描述x与y之间的某一事实。
- 特征函数在训练集上关于
P
~
(
X
,
Y
)
\widetilde P(X,Y)
P
(X,Y)的期望:
E p ~ ( f ) = ∑ x , y P ~ ( x , y ) f ( x , y ) (2-2) E_{\tilde p}(f) = \sum_{x,y} \tilde P(x, y) f(x, y) \tag{2-2} Ep~(f)=x,y∑P~(x,y)f(x,y)(2-2) - 特征函数关于模型P(X,Y)的期望:
E p ( f ) = ∑ x , y P ( x , y ) f ( x , y ) E_{p}(f) = \sum_{x,y}P(x, y) f(x, y) Ep(f)=x,y∑P(x,y)f(x,y)
我们对模型P(X,Y)是未知的,并且我们想求解的是P(Y|X),所以用贝叶斯定理转换,即P(X,Y)=P(X)P(Y|X),并且我们希望特征
f
f
f的期望与训练集中得到的期望一样:
E
p
(
f
)
=
E
p
~
(
f
)
E_{p}(f) = E_{\tilde p}(f)
Ep(f)=Ep~(f)
∑ x , y P ~ ( x , y ) f ( x , y ) = ∑ x , y P ~ ( x ) P ( y ∣ x ) f ( x , y ) \sum_{x,y} \tilde P(x, y)f(x, y) = \sum_{x,y}\tilde P(x)P(y|x)f(x, y) x,y∑P~(x,y)f(x,y)=x,y∑P~(x)P(y∣x)f(x,y)
上面只是一个特征f,那么如果有D个特征函数,就有D个约束条件,会有多个符合条件的模型,我们要找到条件熵最大的那个,使用熵的计算公式,并且满足约束条件,转化成求解最小值问题:
熵
公
式
:
m
a
x
H
(
P
)
=
−
∑
x
,
y
P
~
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
熵公式:max H(P) = -\sum_{x,y}\tilde P(x)P(y|x) \log P(y |x )
熵公式:maxH(P)=−x,y∑P~(x)P(y∣x)logP(y∣x)
min
P
∈
C
∑
x
,
y
P
~
(
x
)
P
(
y
∣
x
)
log
P
(
y
∣
x
)
s
.
t
.
E
p
~
(
f
i
)
–
E
p
(
f
i
)
=
0
,
i
=
1
,
2
,
⋯
,
d
1
–
∑
y
P
(
y
∣
x
)
=
0
\min_{P \in C}\hspace{3ex} \sum_{x,y}\tilde P(x)P(y|x) \log P(y |x ) \\{\rm s.t.}\hspace{3ex} E_{\tilde p}(f_i) – E_{p}(f_i) = 0,i=1,2,\cdots , d \\ 1 – \sum_y P(y|x) = 0
P∈Cminx,y∑P~(x)P(y∣x)logP(y∣x)s.t.Ep~(fi)–Ep(fi)=0,i=1,2,⋯,d1–y∑P(y∣x)=0
后续引入拉格朗日乘子法转化为对偶问题,

得到损失函数
L
(
P
,
λ
)
L(P,\lambda)
L(P,λ),先求minL(w,p),对P(Y|X)求偏导,一轮求解,数学公式不展示了 - -!
P
λ
=
P
(
y
∣
x
)
=
1
Z
λ
(
x
)
e
∑
i
=
1
d
λ
i
f
i
(
x
,
y
)
其
中
,
Z
λ
(
x
)
=
∑
y
e
∑
i
=
1
d
λ
i
f
i
(
x
,
y
)
P_\lambda = P(y|x) = \frac{1}{Z_\lambda(x)}e^{\sum_{i=1}^d \lambda_if_i(x, y)} \\ 其中 , Z_\lambda(x) =\sum_y e^{\sum_{i=1}^d \lambda_if_i(x, y) }
Pλ=P(y∣x)=Zλ(x)1e∑i=1dλifi(x,y)其中,Zλ(x)=y∑e∑i=1dλifi(x,y)
P λ P_{\lambda} Pλ是最大熵模型的解, λ \lambda λ是特征权值,越大说明特征越重要, Z λ Z_{\lambda} Zλ叫规范化因子
最大熵模型学习中的对偶函数极大化等价于最大熵模型的极大似然估计,最大熵模型的学习问题就转换为具体求解对数似然函数极大化或对偶函数极大化的问题
Softmax与sigmoid可由最大熵模型得来
 .截了一部分图下来,推导就不做了,与上文类似,最后得到softmax
.截了一部分图下来,推导就不做了,与上文类似,最后得到softmax
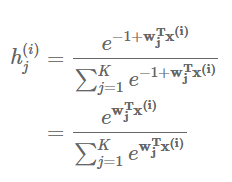
K=2时,就是Sigmoid
逻辑回归其实就是最大熵模型在y=1时抽取x的特征的一种情况
总结
可以看到其实最大熵模型的推导颇为复杂,我在中间省略了一段计算过程,因为我认为过多的数学推导反而会令人产生一种学完跟没学一样的错觉,细节有时候会影响你对这个模型的理解。现在我把几个重要的点总结一下:
- 最大熵模型是一个多分类模型
- 遵循最大熵思想,即保留不确定性,只参考已知的条件,对于未知的条件还是认为其是相等概率的。
- 根据数据集,可以定义多个不同的特征函数,令概率分布与训练数据一致,构成约束条件,组成满足约束条件的f特征函数集合,求解令熵H(y|x)取最大值的f(x,y)














 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









