







最近项目中需要做一个统一身份与认证平台,其中有用户可以自定义扩展字段的需求,目前在设计阶段,记录一下当前的实现方式。
一.整体实现:
由于使用Django orm的原因,比较难对表的结构进行改变,所以需要方便的进行动态扩展。主要通过数据字典的方式记录自定义扩展的字段,然后将需要扩展数据存储到json字段或者扩展数据表中。
数据字典的设计都比较规范,主要是记录对象ID,字段名称,数据类型,是否唯一,是否必填,是否可修改,是否启用。根据业务需要,也可以设置字段精度或者是否索引和是否查询。
二.存储方式参考:
(1) 插槽存储
之前参考了一些云厂商产品在自定义字段中的实现方式,其中做的自由度最高的是salsforce的产品。通过插槽的方式实现自定义数据的存储。salesforce的多租户架构完全实现了用户自定义对象,自定义对象属性,自定义对象之间的关系。通过以下几张表完成了数据定义和数据存储。
MT_Objects:存储对象的定义,通过ORGID字段实现多租户隔离。
MT_Fields:存储自定义字段,包括唯一标识符,字段对象,字段名称,数据类型,是否索引,字段位置。
MT_Data:存储数据。value0-value500个fex列(插槽),存储分别映射到MT_Objects和MT_Fields中声明的表和字段的应用程序数据。每个插槽都存储的是字符串数据,在应用程序读取数据的时候转换为对应的数据类型。
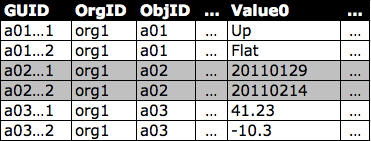
优点:映射关系简单,索引方便
缺点:预留插槽少了不够用,多了又浪费
(2)version+ext
即在表后面增加version,ext字段,version用来描述对应的版本,ext存放map的json数据,如{key1:value1,key2:value2……}
| uid | ... | version | ext |
| 1xxxxx | ... | 0 | {"name": "Bob"} |
| 2xxxxx | ... | 0 | {"name": "Joly"} |
| 2xxxxx | ... | 1 | {"name": "Joly", "gender": "F"} |
优点:可动态扩展字段,不造成空间浪费,查询速度较快,可支持多版本数据
缺点:ext不支持索引,key名称大量冗余,所以key命名尽量短,可使用编码
(3)key+value
通过一张key_value表实现扩展字段数据的存储。
| uid | key | value |
| 1xxxxx | name | Bob |
| 2xxxxx | name | Joly |
| 2xxxxx | gender | F |
优点:每个字段都方便进行查询,可以自由的扩展字段
缺点:一条数据会产生多行记录,Key值冗余过多。
三.项目具体实现:
根据业务的特性,我们业务场景下基础数据量较小,并且根据扩展字段进行查询的需求极小,基本只做存储和展现,所以选择了方案二(version+ext)。
由于项目使用的是Django框架,所以分为模型,序列化,API过滤器三部分分别实现。
(1) 模型设计
首先需要一个扩展字段表记录用户自定义的扩展字段,其中字段包括扩展字段的名称,key值,字段数据类型,扩展的模型,以及是否查询,是否唯一等一些业务设置。
需要注意的是(company_id,key,model)需要是关联唯一的。这样保证了扩展字段的系统唯一。
业务模型需要增加一个json字段用来记录扩展字段的值。
class FieldType(object):
"""字段类型枚举"""
STRING = 1
DATE = 2
BOOL = 3
INT = 4
FLOAT = 5
MESSAGE = {
STRING: _("字符串"),
DATE: _("日期"),
BOOL: _("布尔值"),
INT: _("整数"),
FLOAT: _("浮点值"),
}
class ExpandField(object):
"""扩展字段表"""
name = models.CharField(max_length=32, help_text=_("字段名称"))
key = models.CharField(db_index=True, max_length=32, help_text=_("字段编码"))
description = models.TextField(blank=True, null=True, help_text=_("描述"))
field_type = models.SmallIntegerField(choices=FieldType.choices(), help_text=_("字段类型"))
model = models.IntegerField(help_text=_("所属分类"))
is_built_in = models.BooleanField(default=False, help_text=_("是否内置"))
is_required = models.BooleanField(default=False, help_text=_("是否必填"))
is_modified = models.BooleanField(default=True, help_text=_("是否可修改"))
is_unique = models.BooleanField(default=False, help_text=_("是否唯一"))
is_query = models.BooleanField(default=False, help_text=_("是否可查询"))
enabled = models.BooleanField(default=True, help_text=_("是否启用"))
company_id = models.CharField(max_length=32, help_text=_("公司ID"))(2) 序列化
因为和前端约定好扩展字段不和系统字段放在同一级,所以序列化实现和常规的序列化差别不大,只是需要重载一下init方法,转换一下数值的类型为字符串。不过我在这边也实现了把扩展字段外放到第一层级。
class BaseExpandSerializer(serializers.ModelSerializer):
def __init__(self, instance=None, data=empty, **kwargs):
data = self._extract_expand_data(data)
super(BaseExpandSerializer, self).__init__(instance=instance, data=data, **kwargs)
def _extract_expand_data(self, data):
if data == empty:
return data
current_model = getattr(self.Meta, "model")
model_category = {} # 模型类型映射表
if current_model in model_category:
expand = data.pop("expand", {})
for key in list(expand.keys()):
expand[key] = str(expand[key])
data["expand"] = expand
return data
def update(self, instance, validated_data):
new_expand = deepcopy(instance.expand)
new_expand.update(validated_data.get("expand", {}))
validated_data["expand"] = new_expand
return super().update(instance, validated_data)
def get_expand(self, obj):
current_model = getattr(self.Meta, "model")
model_category = {} # 模型类型映射表
if current_model in model_category:
expand = obj.expand or {}
fields = get_model_expand_field(school_id=obj.company_id, model=model_category[current_model])
for field in fields:
key, field_type = field["key"], field["type"]
value = expand.get(key, None) # 未设置的字段置None
if value: # 转换数据类型
if field_type == FieldType.STRING:
value = value
elif field_type == FieldType.INT:
value = int(value)
elif field_type == FieldType.FLOAT:
value = float(value)
elif field_type == FieldType.BOOL:
value = bool(value)
elif field_type == FieldType.DATE:
value = value
expand[key] = value
return expand
return
@property
def data(self):
data = super().data
expand_data = self.get_expand(self.instance)
data.update(expand_data)
return data(3) API过滤器
这里也是继承了django_filters,这里的查询因为业务比较简单,所以没有支持根据字段类型进行不同功能的查询,比如日期进行范围查询,数字的大小查询等。我这边只实现了字符串精确查询。大家可以后面自行补充。
未解决的问题:在FilterSet的这个环节,没有想到比较好的方法把视图层的company_id穿透过来,所以使用了hasattr这个笨办法来判别是否是扩展字段,而且这样会和分页等参数冲突。如果大家有比较好的方法,欢迎评论和指导。
class BaseExpandFilter(django_filters.FilterSet):
system_key = ["page", "page_size"]
def filter_queryset(self, queryset):
queryset = super().filter_queryset(queryset)
return queryset.filter(**self.expand_data)
def extract_expand_data(self, data):
model_str_list, expand_data = [], {}
current_model = self._meta.model
clare_fields = self._meta.fields
keys = list(data.keys())
for key in keys:
if not hasattr(current_model, key) and key not in self.system_key and key not in clare_fields:
expand_key = "expand__{}".format(key)
expand_data[expand_key] = data.get(key)
else:
query_str = "{}={}".format(key, data.get(key))
model_str_list.append(query_str)
model_str = "&".join(model_str_list)
model_data = QueryDict(model_str)
setattr(self, "expand_data", expand_data)
return model_data
def __init__(self, *args, **kwargs):
model_data = self.extract_expand_data(kwargs["data"])
kwargs["data"] = model_data
super(BaseExpandFilter, self).__init__(*args, **kwargs)关于扩展字段的方案归纳和基于django框架的实现到这里就差不多了,虽然还有些未解决的问题,后期如果找到比较好的方法再更新上来。也许有很多实现不太好的地方,欢迎大家讨论和指导,共同进步。














 4879
4879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









