







转自http://jiayi.space/post/scrapy-phantomjs-seleniumdong-tai-pa-chong#fb_new_comment
很多网页具有动态加载的功能,简单的静态页面爬虫对它就无能为力了。这时候就需要PhantomJS+Selenium两大神器,再加上Scrapy爬虫框架,就可以拼凑成一个动态爬虫。
PhantomJS
简单点说PhantomJS就是一个没有界面的浏览器,提供了JavaScript接口。
在Windows平台,下载好PhantomJS后,将phantomjs.exe放到可执行路径里。就可以通过js与webkit内核交互了。
一个简单的例子:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在cmd中输入:
- 1
- 1
就会打印出得到的html代码。
PhantomJS在linux下的安装
先安装依赖包
- 1
- 1
下载PhantomJS
- 1
- 1
官方链接可能速度很慢,百度云链接, 密码:g5b4.
解压:
- 1
- 2
- 3
- 1
- 2
- 3
Selenium
Selenium是一个自动化的测试工具,这里主要用到了它的Webdriver操作浏览器。Selenium可以操作大多数主流浏览器(可能需要相应的驱动),当然也可以操作无界面的浏览器PhantomJS。
直接pip安装:
- 1
- 1
使用Selenium操作PhantomJS:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
这里的driver.get()方法会等待页面加载完成后才返回,也就是说JS也会加载完毕,有很多ajax的情况除外…
Selenium还可以获取节点,填充表单,选择元素等交互操作,这些用到的时候再提。
Scrapy - Downloader Middleware
Scrapy不再详细介绍,这里主要会用到Downloader Middleware, 下载器中间件。
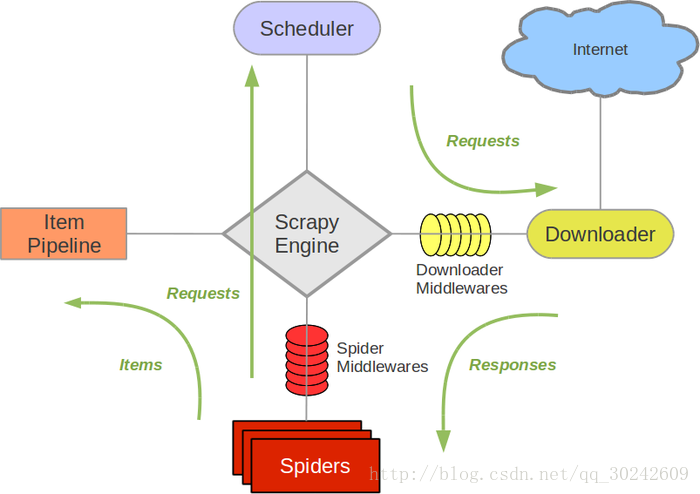
下载器中间件在下载器和Scrapy引擎之间,每一个request和response都会通过中间件进行处理。在中间件中,对request进行处理的函数是process_request(request, spider)
process_request() 必须返回其中之一: 返回 None 、返回一个 Response 对象、返回一个 Request 对象或raise IgnoreRequest 。
如果其返回 None ,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用, 该request被执行(其response被下载)。
如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法,或相应地下载函数; 其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
如果其返回 Request 对象,Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
动态爬虫需要中间件处理request,将加载过特定js的页面作为response返回给spider。
融合
简单说这三者的关系就是:Scrapy通过Selenium使用PhantomJS,爬取加载过JS的页面。
spider.py
在自定义的spider类里,我们要控制何时使用下载器中间件(默认所有请求都会经过中间件)。例如我需要先爬取文章列表页,再获取列表页里的文章页url,再以此爬取文章详情页。在爬取列表页时,不需要经过下载器中间件执行JS,而爬取正文页就需要经过加载过JS的页面。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
对于每一个爬取详情页的request,我们都加上了一个PhantomJS的meta:
- 1
- 1
当请求经过下载器中间件时,检查请求中是否有这个meta,决定这个请求要不要使用中间件。
JSMiddleware.py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
下载器中间件首先判断请求是否需要经过中间件,然后用PhantomJS打开请求的url,将加载好JS的页面装入HtmlResponse,返回给spider继续处理。
注意:如果把爬虫添加到定时任务,需要给phantomjs指定可执行文件的路径,因为crontab不会加载用户自定义的环境变量,比如:
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
改进
现在的web页面内容越来越丰富,多数页面都有滚动加载之类的功能,上述爬虫只能运行加载页面完成时的JS,对其他的JS就无力了。
比如某网站的文章详情页面中,图片只有在当图片区域出现在屏幕显示区域时,才会加载。对于这种情况,我们需要利用JS代码,模仿浏览器的滚动页面行为。让对应的加载图片的代码运行后,再爬取html。
滚动屏幕到底部的JS函数:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
将上述代码放入下载器中间件中执行:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
测试时发现,如果等待JS执行的时间过短
- 1
- 1
会导致爬取的页面靠近底部的图片没能加载,因为滚动函数还未执行到此处。所以需要预留一个稍微长一点的等待时间。















 1028
1028











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









