






近年来,张量分解技术在数据挖掘领域得到了很好的应用,但关于张量的一些计算却与我们所熟悉的线性代数大相径庭,同时,张量计算相比以向量和矩阵计算为主导的线性代数更为抽象,这使得大量读者可能会觉得关于张量的内容很“难啃”。当然,就线性代数和多重线性代数而言,主流的观点将涉及到张量计算的内容归为“多重线性代数”(multilinear algebra,维基百科链接为:Multilinear algebra),并认为多重线性代数实际上是线性代数的延伸。
为了便于认识张量计算,这里将系统地介绍张量分解所需要的一些数学基础,该部分内容主要包括常见的Kronecker积、Khatri-Rao积、向量的外积、内积、F-范数、模态积的运算规则以及高阶奇异值分解。
1 Kronecker积
Kronecker积在张量计算中非常常见,是衔接矩阵计算和张量计算的桥梁,实际上,Kronecker积的运算规则是很简单的,给定一个大小为的矩阵
和一个大小为
的矩阵
,则矩阵
和矩阵
的Kronecker积为
很明显,矩阵的大小为
,即行数为
,列数为
。举一个简单的例子,给定
,
,则
即,且行数为
,列数为
,其中,符号“
”表示Kronecker积。
那么,试想一下:与
是否相同呢?
即,显然,
.
以为例,也可以考虑另外一个问题,即
是否成立呢?
由于,
即,显然,
.
2 Khatri-Rao积
给定大小为的矩阵
和大小为
的矩阵
,则矩阵
和矩阵
的Khatri-Rao积为
举一个例子,给定矩阵,
,则
即,由于
,故
.
需要注意的是,运算符号“”不只是用来表示Khatri-Rao积,有时候也可以表示两个相同大小的矩阵的点乘(element-wise product),如给定矩阵
,
,则
.
3 向量的外积(vector outer product)
给定向量,向量
,则
,运算符号“
”表示外积。另给定向量
,若
,则
,
,
,
其中,是一个三维数组(有三个索引),对于任意索引
上的值为
,在这里,向量
,
,
的外积即可得到一个第三阶张量(third-order tensor),如图1所示。
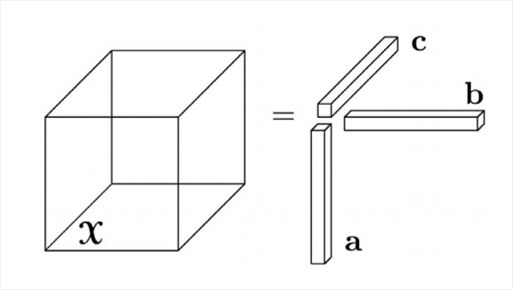
图1 向量,
,
的外积
在大量的文献中,Kronecker积的符号“”有时也用来表示向量的外积。
4 内积(inner product)
众所周知,向量的内积是一个标量,如给定向量,向量
,则向量
,
的内积为
当给定两个大小相同的第三阶张量和
,如
,
,
,
,则
.
即两个大小相同的张量其内积是一个标量,这可能也是内积有时候被称为标量积(scalar product)的原因。
5 F-范数(Frobenius norm)
给定张量为
,
,则该张量的F-范数为
即张量F-范数的平方等于其所有元素的平方和,正是这样,很多涉及到矩阵分解或张量分解的优化问题中常常会出现残差矩阵的平方和最小化或是残差张量的平方和最小化,目标函数也多以相应的残差矩阵或残差张量的F-范数的平方形式进行书写。
6 张量的展开(unfolding)
在实际应用中,由于高阶张量比向量、矩阵都抽象,最简单地,向量和矩阵可以很轻松地书写出来并进行运算,而高阶张量则不那么直观,如何将高阶张量转换成二维空间的矩阵呢?这就是张量的展开,有时,也将张量的展开称为张量的矩阵化(Matricization: transforming a tensor into a matrix)。
给定大小为的张量
,其中,矩阵
,矩阵
,按照模态1(mode-1, 即对应着张量的第一阶)展开可以得到,
即矩阵,其大小为
.
按照模态2(mode-2, 即对应着张量的第二阶)展开可以得到,
即矩阵,其大小为
.
按照模态3(mode-3, 即对应着张量的第三阶)展开可以得到,
即矩阵,其大小为
.
类似地,如果给定一个大小为的第四阶张量
,则在各个模态下的展开分别为
,
,
,
.
举一个例子,若,
,
,
,则
,
,
,
.
可惜的是,张量的展开虽然有一定的规则,但并没有很强的物理意义,对高阶张量进行展开会方便使用相应的矩阵化运算。除此之外,高阶张量可以展开自然也就可以还原(即将展开后的矩阵还原成高阶张量,这个过程称为folding)。
7 张量与矩阵相乘(modal product, 模态积)
张量与矩阵相乘(又称为模态积)相比矩阵与矩阵之间的相乘更为抽象,如何理解呢?
假设一个大小为的张量
,同时给定一个大小为
的矩阵
,则张量
与矩阵
的
模态积(
-mode product)记为
,其大小为
,对于每个元素而言,有
其中,,我们可以看出,模态积是张量、矩阵和模态(mode)的一种“组合”运算。另外,
与
是等价的,这在接下来的例子里会展现相应的计算过程。
上述给出张量与矩阵相乘的定义,为了方便理解,下面来看一个简单的示例,若给定张量为
,
,其大小为
,另外给定矩阵
,试想一下:张量
和矩阵
相乘会得到什么呢?
假设,则对于张量
在任意索引
上的值为
,这一运算规则也不难发现,张量
的大小为
,以
位置为例,
再以位置为例,
,这样,可以得到张量
为
,
,
即,
.
其中,由于模态积的运算规则不再像Kronecer积和Khatri-Rao积那么“亲民”,所以有兴趣的读者可以自己动手计算一遍。
实际上,(会得到大小为
的张量)或
(会得到大小为
的张量)也可以用上述同样的运算规则进行计算,这里将不再赘述,有兴趣的读者可以自行推导。需要注意的是,
有一个恒等的计算公式,即
,由于
,则
满足,即采用张量矩阵化的形式进行运算可以使问题变得更加简单,从这里也可以看出高阶张量进行矩阵化的优点。
8 延伸阅读:高阶奇异值分解(higher-order singular value decomposition, 简称HOSVD)
矩阵的奇异值分解(singular value decomposition,简称SVD)是线性代数中很重要的内容,通常,给定一个大小为的矩阵
,奇异值分解的形式为
其中,矩阵的大小分别为
,矩阵
是由左奇异向量(left singular vector)构成的,矩阵
是由右奇异向量(right singular vector)构成的,矩阵
对角线上的元素称为奇异值(singular value),这一分解过程很简单,但实际上,关于奇异值分解的应用是非常广泛的。
就高阶奇异值分解而言,著名学者Tucker于1966年给出了计算Tucker分解的三种方法,第一种方法就是我们这里要提到的高阶奇异值分解,其整个分解过程也是由矩阵的奇异值分解泛化得到的。
对于给定一个大小为的张量
,将
模态下的展开记为
,则
模态的矩阵进行奇异值分解,可以写成
这里的是通过矩阵
的奇异值分解得到的,如果取出各个模态下得到的矩阵
,则张量
的高阶奇异值分解可以写成如下形式:
其中,是核心张量,其计算公式为
,在这里,这条计算公式等价于
(
也是恒成立的)。
细心的读者可能会发现,根据奇异值分解的定义,这里的核心张量的大小为
,而矩阵
的大小则分别为
.
我们也知道,对于矩阵的奇异值分解是可以进行降维(dimension reduction)处理的,即取前个最大奇异值以及相应的左奇异向量和右奇异向量,我们可以得到矩阵
的大小分别为
,这也被称为截断的奇异值分解(truncated SVD),对于高阶奇异值分解是否存在类似的“降维”过程(即truncated HOSVD, 截断的高阶奇异值分解)呢?
给定核心张量的大小为
,并且
,
,...,
,则对于
模态的矩阵
进行奇异值分解取前
个最大奇异值对应的左奇异向量,则矩阵
的大小为
,对矩阵
进行奇异值分解,知道了
后,再计算核心张量
,我们就可以最终得到想要的Tucker分解了。
9 相关阅读
本文主要参考了Gene H. Golub和Charles F. Van Loan合著的经典著作《Matrix computations (4th edition)》,有兴趣的读者可以阅读第12章的12.3 Kronecker Product Computations, 12.4 Tensor Unfoldings and Contractions和12.5 Tensor Decompositions and Iterations;另外,Tamara G. Kolda和Brett W. Bader于2009年发表的一篇经典综述论文《Tensor decompositions and Applications》(链接为:http://public.ca.sandia.gov/~tgkolda/pubs/pubfiles/TensorReview.pdf)也是本文的主要参考资料。














 3041
3041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









