



Python连续多年占据TIOBE编程语言排行榜榜首,其简洁的语法、强大的生态和跨领域适用性使其成为编程初学者的首选,也是专业开发者的必备工具。从人工智能、数据分析到Web开发、自动化运维,Python几乎无处不在。本教程将带你从环境搭建开始,逐步掌握Python核心语法、数据结构、面向对象编程,最终通过实战项目感受Python的强大魅力。每个章节都配有代码示例、流程图解和学习Prompt,帮你构建完整的Python知识体系。
一、Python环境搭建:从安装到第一个程序
1.1 为什么选择Python?
Python的设计哲学是“优雅”“明确”“简单”,这体现在其强制缩进的语法规则和可读性极强的代码中。根据JetBrains 2023开发者调查,71%的数据科学家和65%的机器学习工程师将Python作为主要开发语言。其应用领域包括:
-
数据科学:Pandas、NumPy、Matplotlib构成数据分析铁三角
-
人工智能:TensorFlow、PyTorch等框架基于Python开发
-
Web开发:Django、Flask快速构建高性能网站
-
自动化脚本:替代Shell脚本处理文件、网络等自动化任务
1.2 安装Python环境
Windows系统安装
-
访问Python官网下载对应版本(推荐3.10+)
-
运行安装程序,勾选"Add Python to PATH"(关键步骤)
-
点击"Install Now"完成安装
-
验证安装:打开命令提示符,输入python --version,显示Python 3.10.12等版本信息即为成功
macOS/Linux系统安装
macOS通常预装Python,但可能不是最新版本:
# 检查系统Python版本 python3 --version # 使用Homebrew安装(macOS) brew install python@3.11 # Ubuntu/Debian系统 sudo apt update && sudo apt install python3 python3-pip
虚拟环境配置
为避免项目依赖冲突,建议使用虚拟环境:
# 创建虚拟环境 python -m venv myenv # 激活虚拟环境(Windows) myenv\Scripts\activate # 激活虚拟环境(macOS/Linux) source myenv/bin/activate # 激活后命令行前缀会显示(myenv),表示当前处于虚拟环境中 # 退出虚拟环境 deactivate
1.3 第一个Python程序
使用文本编辑器(VS Code、PyCharm或记事本)编写以下代码,保存为hello.py:
# 这是单行注释,用于解释代码功能 """ 这是多行注释 可以跨越多行 """ # 打印输出 print("Hello, Python!") # 输出:Hello, Python! # 变量定义与运算 name = "Python学习者" # 字符串变量 age = 1 # 整数变量 print(f"我是{name},学习Python已经{age}天了!") # 格式化字符串,输出:我是Python学习者,学习Python已经1天了!
在命令行中运行:
python hello.py
代码解释:print()是Python内置函数,用于输出信息;f-string(以f开头的字符串)允许在{}中直接嵌入变量,是Python 3.6+引入的便捷语法。
二、Python核心语法:变量、数据类型与运算符
2.1 变量与数据类型
变量命名规则
-
只能包含字母、数字和下划线(_)
-
不能以数字开头
-
区分大小写(age和Age是不同变量)
-
不能使用Python关键字(如if、for、class等)
推荐命名方式:使用小写字母和下划线组合(snake_case),如user_name、student_score。
基本数据类型
| 数据类型 | 描述 | 示例 | 可变/不可变 |
|---|---|---|---|
| 整数(int) | 无小数部分的数字 | 42、-7、0 | 不可变 |
| 浮点数(float) | 带小数部分的数字 | 3.14、-0.001 | 不可变 |
| 字符串(str) | 文本数据,单/双引号包围 | "hello"、'Python' | 不可变 |
| 布尔值(bool) | 表示真/假 | True、False | 不可变 |
| 列表(list) | 有序集合,可包含多种类型 | [1, "a", True] | 可变 |
| 元组(tuple) | 有序集合,不可修改 | (1, "a", True) | 不可变 |
| 字典(dict) | 键值对集合 | {"name": "Tom", "age": 18} | 可变 |
| 集合(set) | 无序唯一元素集合 | {1, 2, 3} | 可变 |
代码示例:
# 查看数据类型 a = 42 print(type(a)) # 输出:<class 'int'> b = "42" print(type(b)) # 输出:<class 'str'> # 类型转换 c = int(b) # 将字符串"42"转换为整数42 print(a + c) # 输出:84
2.2 运算符与表达式
算术运算符
a, b = 10, 3 # 同时为多个变量赋值 print(a + b) # 加法:13 print(a - b) # 减法:7 print(a * b) # 乘法:30 print(a / b) # 除法(结果为float):3.333... print(a // b) # 整除(向下取整):3 print(a % b) # 取余(模运算):1 print(a ** b) # 幂运算(10^3):1000
比较运算符
比较结果为布尔值(True或False):
x, y = 5, 10 print(x > y) # False print(x < y) # True print(x == y) # False(注意是双等号,单等号是赋值) print(x != y) # True print(x >= 5) # True print(y <= 9) # False
逻辑运算符
用于组合多个条件:
a, b = 10, 20 # and:两边都为True才返回True print(a > 5 and b > 15) # True # or:至少一边为True就返回True print(a > 15 or b > 15) # True # not:取反 print(not a > 5) # False
身份运算符
判断两个变量是否引用同一对象:
list1 = [1, 2, 3] list2 = list1 # 引用同一列表 list3 = [1, 2, 3] # 新列表,内容相同但对象不同 print(list1 is list2) # True(同一对象) print(list1 is list3) # False(不同对象) print(list1 == list3) # True(内容相同)
2.3 字符串操作详解
字符串是Python中最常用的数据类型之一,提供丰富的内置方法:
s = " Hello Python Programming " # 去除空白字符 print(s.strip()) # "Hello Python Programming"(去除两端空白) print(s.lstrip()) # "Hello Python Programming "(去除左端空白) # 大小写转换 print(s.upper()) # " HELLO PYTHON PROGRAMMING " print(s.lower()) # " hello python programming " print(s.title()) # " Hello Python Programming "(每个单词首字母大写) # 查找与替换 print(s.find("Python")) # 7(返回子串起始索引,未找到返回-1) print(s.replace("Python", "Java")) # " Hello Java Programming " # 分割与连接 words = s.strip().split(" ") # 按空格分割为列表:["Hello", "Python", "Programming"] print("-".join(words)) # "Hello-Python-Programming"(用"-"连接列表元素) # 字符串切片(左闭右开区间) print(s[7:13]) # "Python"(从索引7到12的字符) print(s[:5]) # " Hel"(从开头到索引4) print(s[-11:]) # "Programming "(从倒数第11个字符到结尾)
Prompt示例:如何用Python判断一个字符串是否是回文(正读反读都一样)?
提示:使用字符串切片[::-1]可以反转字符串,比较原字符串与反转字符串是否相等。
三、控制流:条件语句与循环结构
3.1 条件语句(if-elif-else)
条件语句用于根据不同条件执行不同代码块,其执行流程可用流程图表示:
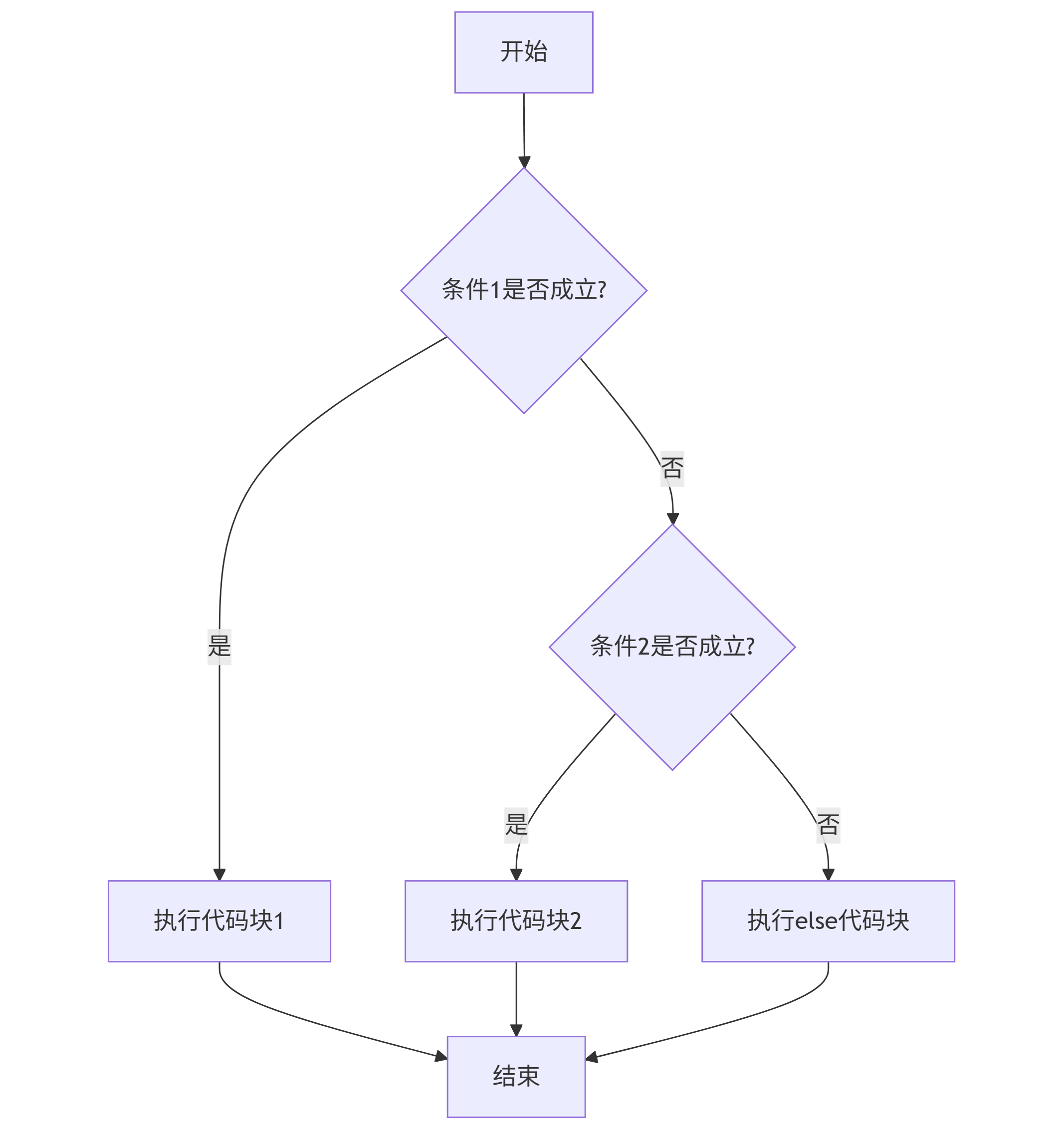
flowchart TD A[开始] --> B{条件1是否成立?} B -- 是 --> C[执行代码块1] --> E[结束] B -- 否 --> D{条件2是否成立?} D -- 是 --> F[执行代码块2] --> E D -- 否 --> G[执行else代码块] --> E
代码示例:根据分数判断等级
score = 85 if score >= 90: # 缩进(通常4个空格)定义代码块范围 print("优秀") elif score >= 80: print("良好") elif score >= 60: print("及格") else: print("不及格") # 输出:良好
嵌套条件语句:
age = 20 has_id = True if age >= 18: print("年龄符合要求") if has_id: print("允许进入") else: print("请出示身份证") else: print("年龄不符合要求") # 输出: # 年龄符合要求 # 允许进入
3.2 循环结构:for循环与while循环
for循环:遍历序列
用于遍历字符串、列表、元组等可迭代对象:
# 遍历字符串 for char in "Python": print(char, end=" ") # end=" "指定结尾字符为空格,输出:P y t h o n # 遍历列表 fruits = ["apple", "banana", "cherry"] for fruit in fruits: print(f"I like {fruit}") # 使用range()生成数字序列 for i in range(5): # range(5)生成0-4的整数 print(i) # 输出0,1,2,3,4 for i in range(2, 10, 2): # 从2开始,到10结束(不包含10),步长2 print(i) # 输出2,4,6,8
while循环:条件满足时重复执行
适用于循环次数不确定的场景:
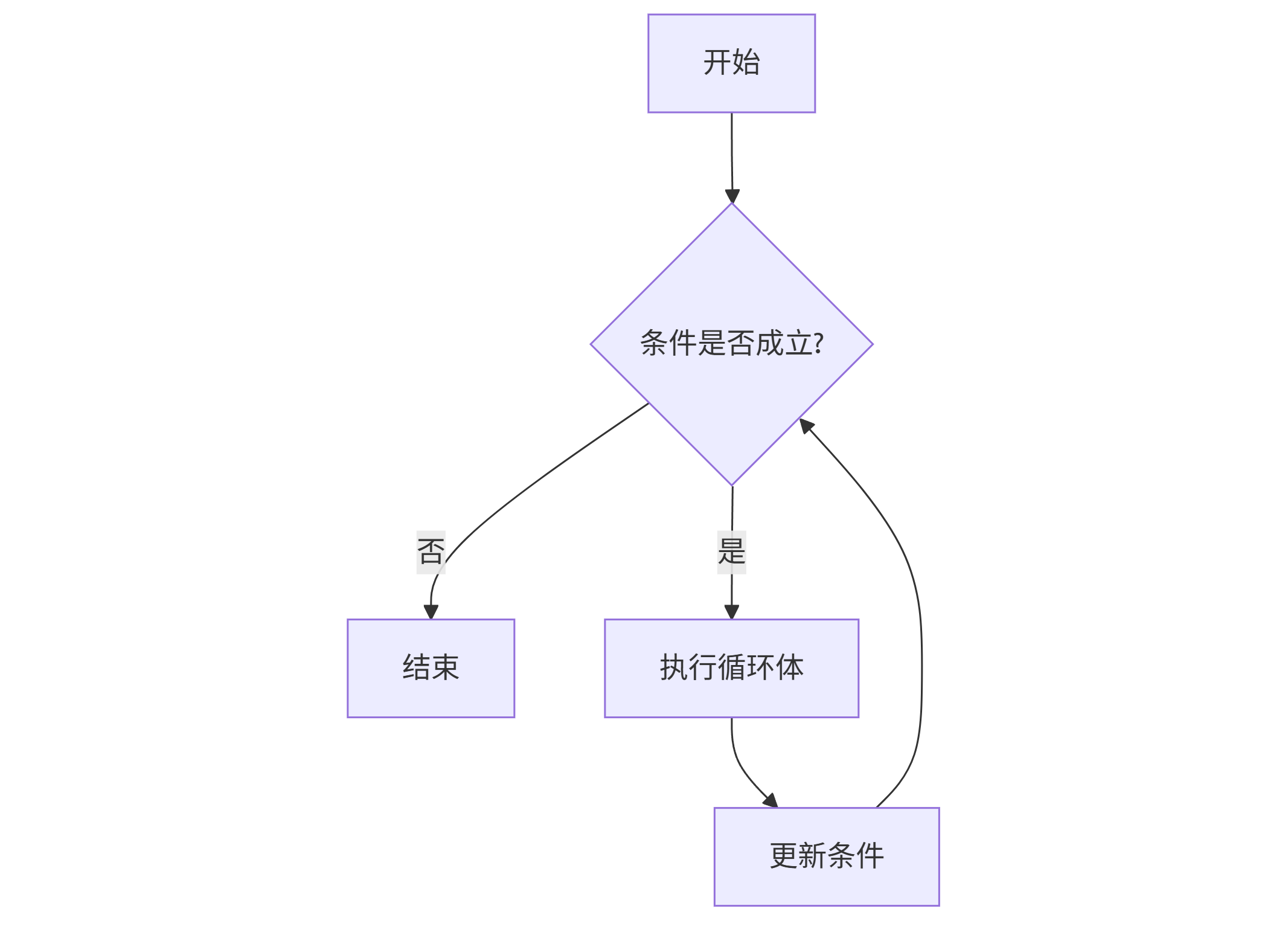
flowchart TD A[开始] --> B{条件是否成立?} B -- 否 --> C[结束] B -- 是 --> D[执行循环体] D --> E[更新条件] --> B
代码示例:猜数字游戏
import random # 导入随机数模块 secret_number = random.randint(1, 100) # 生成1-100的随机数 guess = 0 attempts = 0 while guess != secret_number: attempts += 1 guess = int(input("猜一个1-100之间的数字:")) # 获取用户输入并转换为整数 if guess < secret_number: print("猜小了!") elif guess > secret_number: print("猜大了!") else: print(f"恭喜猜对了!用了{attempts}次")
循环控制:break与continue
-
break:立即退出整个循环
-
continue:跳过当前循环剩余部分,直接进入下一次循环
# break示例 for i in range(10): if i == 5: break # 当i=5时退出循环 print(i) # 输出0,1,2,3,4 # continue示例 for i in range(10): if i % 2 == 0: continue # 偶数时跳过打印 print(i) # 输出1,3,5,7,9
循环中的else子句
Python的循环支持else子句,当循环正常结束(未被break中断)时执行:
for i in range(3): guess = int(input("输入密码:")) if guess == 123: print("密码正确") break else: # 3次都猜错时执行 print("3次错误,账户锁定")
3.3 列表推导式:循环的优雅写法
列表推导式提供简洁的方式创建列表,将for循环和条件判断合并为一行代码:
# 传统方式:创建1-10的平方列表 squares = [] for i in range(1, 11): squares.append(i **2) print(squares) # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100] # 列表推导式等价实现 squares = [i** 2 for i in range(1, 11)] print(squares) # 同上 # 带条件的列表推导式:筛选偶数的平方 even_squares = [i **2 for i in range(1, 11) if i % 2 == 0] print(even_squares) # [4, 16, 36, 64, 100] # 嵌套列表推导式:转置矩阵 matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] transposed = [[row[i] for row in matrix] for i in range(3)] print(transposed) # [[1, 4, 7], [2, 5, 8], [3, 6, 9]]
Prompt示例:如何用列表推导式将一个列表中的字符串转换为小写并去除长度小于3的字符串?
提示:结合str.lower()方法和长度判断条件,如[s.lower() for s in strings if len(s)>=3]。
四、数据结构:从列表到集合的实战应用
4.1 列表(List):有序可变集合
列表是Python中最常用的数据结构,支持动态添加、删除元素:
# 创建列表 numbers = [1, 2, 3, 4, 5] mixed = [1, "hello", True, 3.14] # 可包含不同类型元素 # 访问元素(索引从0开始) print(numbers[0]) # 1(第一个元素) print(numbers[-1]) # 5(最后一个元素) # 修改元素 numbers[2] = 30 print(numbers) # [1, 2, 30, 4, 5] # 添加元素 numbers.append(6) # 末尾添加:[1, 2, 30, 4, 5, 6] numbers.insert(1, 1.5) # 指定位置插入:[1, 1.5, 2, 30, 4, 5, 6] numbers.extend([7, 8]) # 扩展列表:[1, 1.5, 2, 30, 4, 5, 6, 7, 8] # 删除元素 numbers.remove(30) # 删除指定值:[1, 1.5, 2, 4, 5, 6, 7, 8] popped = numbers.pop(1) # 删除指定索引元素并返回:1.5,列表变为[1, 2, 4, 5, 6, 7, 8] del numbers[0] # 删除指定索引:[2, 4, 5, 6, 7, 8] # 列表排序 numbers.sort() # 原地排序(升序):[2, 4, 5, 6, 7, 8] numbers.sort(reverse=True) # 降序:[8, 7, 6, 5, 4, 2] sorted_numbers = sorted(numbers) # 返回新列表,原列表不变
常用列表方法总结:
| 方法 | 功能 | 示例 |
|---|---|---|
| append(x) | 在末尾添加元素x | [1,2].append(3) → [1,2,3] |
| extend(iter) | 扩展列表,添加可迭代对象元素 | [1,2].extend([3,4]) → [1,2,3,4] |
| insert(i,x) | 在索引i处插入x | [1,3].insert(1,2) → [1,2,3] |
| remove(x) | 删除第一个值为x的元素 | [1,2,2].remove(2) → [1,2] |
| pop([i]) | 删除索引i的元素并返回,默认最后一个 | [1,2,3].pop(1) → 2,列表变为[1,3] |
| index(x) | 返回第一个值为x的索引 | [1,2,3].index(2) → 1 |
| count(x) | 统计x出现的次数 | [1,2,2,3].count(2) → 2 |
| sort() | 原地排序 | [3,1,2].sort() → [1,2,3] |
| reverse() | 原地反转列表 | [1,2,3].reverse() → [3,2,1] |
4.2 元组(Tuple):不可变序列
元组与列表类似,但创建后不能修改元素,适合存储不可变数据:
# 创建元组(小括号可省略) point = (3, 4) colors = "red", "green", "blue" # 省略括号的元组 # 访问元素(同列表) print(point[0]) # 3 # 尝试修改元素会报错 # point[0] = 5 # TypeError: 'tuple' object does not support item assignment # 元组拆包 x, y = point print(f"x={x}, y={y}") # x=3, y=4 # 单元素元组(需加逗号) single = (5,) # 注意逗号,否则会被视为整数5 # 元组的不可变性指元素引用不可变,若元素是可变对象(如列表),其内容可修改 mixed_tuple = (1, [2, 3], 4) mixed_tuple[1].append(5) print(mixed_tuple) # (1, [2, 3, 5], 4)
元组的应用场景:
-
函数返回多个值(本质是返回元组)
-
保护数据不被修改(如配置信息)
-
作为字典的键(列表不可作为字典键)
-
格式化字符串时传递参数:"坐标:({}, {})".format(*point)
4.3 字典(Dictionary):键值对集合
字典通过键值对存储数据,支持快速查找(平均时间复杂度O(1)):
# 创建字典 student = { "name": "小明", "age": 18, "major": "计算机科学", "grades": [90, 85, 95] # 值可以是列表等复杂类型 } # 访问值(通过键) print(student["name"]) # 小明 print(student.get("age")) # 18(get方法,键不存在返回None) print(student.get("address", "未知")) # 未知(指定默认值) # 修改值 student["age"] = 19 print(student["age"]) # 19 # 添加新键值对 student["address"] = "北京市" print(student) # 包含address的新字典 # 删除键值对 del student["address"] # 或使用pop方法 age = student.pop("age") print(age) # 19 # 遍历字典 for key in student: print(f"{key}: {student[key]}") # 遍历键并获取值 for key, value in student.items(): print(f"{key}: {value}") # 同时遍历键和值
字典推导式:快速创建字典
# 从列表创建字典:键为元素,值为元素长度 words = ["apple", "banana", "cherry"] word_lengths = {word: len(word) for word in words} print(word_lengths) # {'apple': 5, 'banana': 6, 'cherry': 6} # 过滤字典:保留长度大于5的单词 long_words = {k: v for k, v in word_lengths.items() if v > 5} print(long_words) # {'banana': 6, 'cherry': 6}
4.4 集合(Set):无序唯一元素集合
集合自动去重,支持数学集合运算(交集、并集等):
# 创建集合(注意:空集合必须用set(),{}创建空字典) fruits = {"apple", "banana", "cherry", "apple"} # 自动去重 print(fruits) # {'banana', 'apple', 'cherry'}(顺序不固定) # 添加元素 fruits.add("orange") print(fruits) # {'banana', 'apple', 'orange', 'cherry'} # 删除元素 fruits.remove("banana") # 元素不存在会报错 fruits.discard("grape") # 元素不存在不报错 # 集合运算 a = {1, 2, 3, 4} b = {3, 4, 5, 6} print(a & b) # {3, 4}(交集,a.intersection(b)) print(a | b) # {1, 2, 3, 4, 5, 6}(并集,a.union(b)) print(a - b) # {1, 2}(差集,a.difference(b)) print(a ^ b) # {1, 2, 5, 6}(对称差集,a.symmetric_difference(b)) print(a <= b) # False(a是否是b的子集)
集合的典型应用:
-
快速去重:list(set(duplicate_list))
-
判断元素是否存在:if x in my_set(平均O(1)时间复杂度,比列表的O(n)更快)
-
数据清洗:去除重复记录
五、函数编程:模块化代码设计
5.1 函数定义与调用
函数将代码块封装为可重用单元,提高代码可读性和复用性:
# 基本函数结构 def greet(name): """显示问候语(函数文档字符串)""" return f"Hello, {name}!" # 返回值 # 调用函数 message = greet("Alice") print(message) # Hello, Alice! # 查看函数文档 print(greet.__doc__) # 显示问候语(函数文档字符串) help(greet) # 更详细的文档查看
参数类型
Python函数支持多种参数形式,灵活应对不同调用场景:
# 位置参数(必须按顺序传递) def add(a, b): return a + b print(add(2, 3)) # 5 # 默认参数(指定默认值,可省略传递) def power(base, exponent=2): # exponent默认值为2 return base ** exponent print(power(3)) # 9(使用默认指数2) print(power(2, 3)) # 8(指定指数3) # 关键字参数(通过参数名传递,可改变顺序) print(add(b=5, a=3)) # 8(显式指定参数名) # 可变位置参数(接收任意数量位置参数,用*表示) def sum_numbers(*args): # args是元组 total = 0 for num in args: total += num return total print(sum_numbers(1, 2, 3)) # 6 print(sum_numbers(10, 20, 30, 40)) # 100 # 可变关键字参数(接收任意数量关键字参数,用**表示) def print_info(**kwargs): # kwargs是字典 for key, value in kwargs.items(): print(f"{key}: {value}") print_info(name="Bob", age=25, city="New York") # 输出: # name: Bob # age: 25 # city: New York
5.2 函数进阶:作用域与装饰器
变量作用域
变量的作用域决定其可访问范围,分为:
-
局部变量:函数内部定义,仅在函数内有效
-
全局变量:函数外部定义,可在整个模块访问
-
非局部变量:嵌套函数中,用nonlocal声明
x = 10 # 全局变量 def outer(): x = 20 # 外层函数局部变量 def inner(): nonlocal x # 引用外层函数的x,而非全局x x = 30 print("inner x:", x) # inner x: 30 inner() print("outer x:", x) # outer x: 30(被inner修改) outer() print("global x:", x) # global x: 10(未被修改)
装饰器:增强函数功能
装饰器(Decorator)是高阶函数,用于在不修改原函数代码的情况下增强其功能:
# 定义装饰器 def timer(func): """计算函数执行时间的装饰器""" import time def wrapper(*args, **kwargs): start = time.time() result = func(*args, **kwargs) # 调用原函数 end = time.time() print(f"{func.__name__}执行时间:{end - start:.4f}秒") return result # 返回原函数结果 return wrapper # 使用装饰器(@语法糖) @timer def slow_function(seconds): """模拟耗时操作""" time.sleep(seconds) return "完成" # 调用被装饰的函数 result = slow_function(1) print(result) # 输出: # slow_function执行时间:1.0012秒 # 完成
常用装饰器场景:日志记录、性能分析、权限验证、缓存等。Python内置的functools.wraps装饰器可保留原函数元信息,建议在自定义装饰器时使用。
六、面向对象编程:类与实例的实战
6.1 类与对象的基本概念
面向对象编程(OOP)将数据和操作数据的方法封装为"对象",通过类定义对象的模板:

classDiagram class Person { - name: str - age: int + __init__(name: str, age: int) + greet(): str + have_birthday(): None } Person <|-- Student class Student { - major: str + study(course: str): str }
类定义与实例化:
class Person: """人这个类的定义""" # 类属性(所有实例共享) species = "Homo sapiens" def __init__(self, name, age): """初始化方法(构造函数)""" self.name = name # 实例属性 self.age = age def greet(self): """实例方法:返回问候语""" return f"Hello, my name is {self.name}." def have_birthday(self): """实例方法:年龄加1""" self.age += 1 print(f"Happy birthday! Now I'm {self.age}.") # 创建实例(对象) alice = Person("Alice", 25) # 访问属性 print(alice.name) # Alice(实例属性) print(alice.species) # Homo sapiens(类属性) # 调用方法 print(alice.greet()) # Hello, my name is Alice. alice.have_birthday() # Happy birthday! Now I'm 26.
6.2 继承与多态
继承允许创建子类复用父类代码,多态则允许不同子类对象对同一方法作出不同响应:
# 子类Student继承自Person class Student(Person): """学生类,继承Person""" def __init__(self, name, age, major): # 调用父类初始化方法 super().__init__(name, age) self.major = major # 子类特有属性 # 重写父类方法(多态) def greet(self): """学生特有的问候语""" return f"Hello, I'm {self.name}, a {self.major} student." # 子类特有方法 def study(self, course): return f"Studying {course}..." # 创建子类实例 bob = Student("Bob", 20, "Computer Science") # 调用继承的方法 bob.have_birthday() # Happy birthday! Now I'm 21. # 调用重写的方法(多态体现) print(bob.greet()) # Hello, I'm Bob, a Computer Science student. # 调用子类特有方法 print(bob.study("Python Programming")) # Studying Python Programming...
面向对象三大特性:
-
封装:将数据(属性)和操作(方法)捆绑在类中,通过访问控制隐藏内部实现
-
继承:子类继承父类属性和方法,实现代码复用
-
多态:不同对象对同一方法有不同实现,提高代码灵活性
七、数据科学入门:用Python处理和可视化数据
7.1 NumPy:数值计算基础
NumPy提供高效的多维数组操作和数学函数,是数据科学的基础库:
import numpy as np # 导入NumPy并简写为np # 创建数组 arr = np.array([1, 2, 3, 4, 5]) # 一维数组 matrix = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 二维数组(矩阵) # 数组属性 print(arr.shape) # (5,)(形状:一维数组,5个元素) print(matrix.shape) # (3, 3)(3行3列) print(arr.dtype) # int64(数据类型) # 数组运算(元素级操作,无需循环) print(arr + 2) # [3 4 5 6 7] print(arr * 3) # [ 3 6 9 12 15] print(arr **2) # [ 1 4 9 16 25] print(matrix @ matrix) # 矩阵乘法(等价于np.matmul(matrix, matrix)) # 统计函数 print(arr.mean()) # 3.0(平均值) print(arr.sum()) # 15(总和) print(arr.max()) # 5(最大值) print(matrix.sum(axis=0)) # [12 15 18](按列求和)
7.2 Pandas:数据分析利器
Pandas提供DataFrame数据结构,专为表格数据处理设计:
import pandas as pd # 创建DataFrame(类似Excel表格) data = { "Name": ["Alice", "Bob", "Charlie", "David"], "Age": [25, 22, 28, 24], "City": ["New York", "London", "Paris", "Tokyo"], "Salary": [50000, 45000, 60000, 55000] } df = pd.DataFrame(data) # 查看数据 print(df.head(2)) # 前2行 print(df.describe()) # 统计摘要(数值列) # 数据选择 print(df["Name"]) # 选择列 print(df[df["Age"] > 24]) # 筛选年龄>24的行 # 数据处理 df["Salary"] = df["Salary"] * 1.1 # 工资上涨10% df["City"] = df["City"].str.upper() # 城市名转为大写 # 保存数据 df.to_csv("employees.csv", index=False) # 保存为CSV文件
7.3 Matplotlib:数据可视化
Matplotlib用于创建各种静态、动态图表,直观展示数据特征:
import matplotlib.pyplot as plt import numpy as np # 设置中文显示(解决中文乱码问题) plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"] # 生成数据 x = np.linspace(0, 10, 100) # 0-10之间100个均匀点 y1 = np.sin(x) y2 = np.cos(x) # 创建图表 plt.figure(figsize=(10, 4)) # 设置图表大小 # 绘制曲线 plt.plot(x, y1, label="正弦曲线", color="blue", linestyle="-", linewidth=2) plt.plot(x, y2, label="余弦曲线", color="red", linestyle="--", linewidth=2) # 添加标题和标签 plt.title("正弦和余弦曲线", fontsize=15) plt.xlabel("X轴", fontsize=12) plt.ylabel("Y轴", fontsize=12) # 添加网格和图例 plt.grid(True, linestyle="--", alpha=0.7) # alpha控制透明度 plt.legend(fontsize=12) # 显示图例 # 保存图表(需在show()前调用) plt.savefig("sin_cos_plot.png", dpi=300, bbox_inches="tight") # 显示图表 plt.show()
运行以上代码将生成包含正弦和余弦曲线的图表,并保存为PNG图片。图表中包含标题、坐标轴标签、图例和网格线,清晰展示两条曲线的关系。
八、实战项目:天气数据分析与可视化
8.1 项目需求
分析2023年北京天气数据,包括:
-
读取CSV格式的天气数据
-
统计每月平均气温、最高/最低气温
-
分析降水分布情况
-
可视化气温变化趋势和降水分布
8.2 数据准备
假设我们有beijing_2023_weather.csv文件,包含以下字段:date(日期)、max_temp(最高气温)、min_temp(最低气温)、precipitation(降水量)。
8.3 完整代码实现
import pandas as pd import matplotlib.pyplot as plt import numpy as np # 设置中文显示 plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"] plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题 def analyze_weather_data(file_path): """分析天气数据并生成可视化结果""" # 1. 读取数据 df = pd.read_csv(file_path) # 数据预处理 df["date"] = pd.to_datetime(df["date"]) # 转换为日期类型 df["month"] = df["date"].dt.month # 提取月份 # 2. 统计每月气温 monthly_temp = df.groupby("month").agg({ "max_temp": "mean", "min_temp": "mean", "precipitation": "sum" }).round(1) # 保留一位小数 print("2023年北京每月平均气温及降水量统计:") print(monthly_temp) # 3. 可视化气温趋势 plt.figure(figsize=(12, 6)) # 绘制气温曲线 months = monthly_temp.index plt.plot(months, monthly_temp["max_temp"], "ro-", label="平均最高气温") plt.plot(months, monthly_temp["min_temp"], "bo-", label="平均最低气温") # 添加数据标签 for x, y in zip(months, monthly_temp["max_temp"]): plt.text(x, y + 0.5, f"{y}°C", ha="center") for x, y in zip(months, monthly_temp["min_temp"]): plt.text(x, y - 1.2, f"{y}°C", ha="center") # 设置图表属性 plt.title("2023年北京每月平均气温趋势", fontsize=16) plt.xlabel("月份", fontsize=14) plt.ylabel("气温 (°C)", fontsize=14) plt.xticks(months) plt.grid(axis="y", linestyle="--", alpha=0.7) plt.legend(fontsize=12) # 保存气温图表 plt.tight_layout() plt.savefig("temperature_trend.png", dpi=300) plt.close() # 4. 可视化降水量 plt.figure(figsize=(12, 6)) # 绘制降水量柱状图 bars = plt.bar(months, monthly_temp["precipitation"], color="skyblue") # 添加数据标签 for bar in bars: height = bar.get_height() plt.text(bar.get_x() + bar.get_width()/2., height, f"{height}mm", ha="center", va="bottom") # 设置图表属性 plt.title("2023年北京每月降水量分布", fontsize=16) plt.xlabel("月份", fontsize=14) plt.ylabel("降水量 (mm)", fontsize=14) plt.xticks(months) plt.grid(axis="y", linestyle="--", alpha=0.7) # 保存降水图表 plt.tight_layout() plt.savefig("precipitation_distribution.png", dpi=300) plt.close() print("\n分析完成!已生成气温趋势图和降水量分布图。") # 运行分析 if __name__ == "__main__": analyze_weather_data("beijing_2023_weather.csv")
8.4 项目解释
-
数据读取与预处理:使用Pandas读取CSV文件,将日期字符串转换为日期类型,提取月份用于分组统计。
-
数据分析:通过groupby和agg方法计算每月平均最高/最低气温和总降水量,使用round(1)保留一位小数。
-
数据可视化:
-
气温趋势图:使用折线图展示每月平均气温变化,添加数据标签显示具体数值
-
降水量分布图:使用柱状图展示每月降水总量,直观比较各月降水差异
-
-
结果输出:打印统计结果并保存图表为PNG文件,方便后续分析和报告使用。
运行该项目需要安装必要的库:pip install pandas matplotlib numpy,然后准备好天气数据CSV文件即可执行。
结语:Python学习路径与未来展望
从语法基础到数据科学应用,Python展现了其作为"胶水语言"的强大能力。学习Python不是一蹴而就的过程,建议按以下路径进阶:
-
夯实基础:掌握变量、数据类型、控制流、函数等核心概念
-
数据结构:深入理解列表、字典等结构的内部实现和适用场景
-
模块化编程:学习函数设计、模块导入和包管理
-
领域深耕:根据兴趣选择方向(数据分析、Web开发、AI等)
-
项目实战:通过真实项目积累经验,解决实际问题
Python的生态系统仍在快速发展,随着AI、大数据技术的普及,掌握Python将为你打开更多职业可能性。无论你是希望转行IT的新手,还是提升技能的专业人士,持续学习Python都将是值得的投资。
思考问题:在AI快速发展的今天,掌握Python编程如何帮助你更好地与人工智能协作?你计划用Python解决生活或工作中的什么问题?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











