







 本文深入探讨了Docker中名称空间技术的实现原理及其在进程ID、进程间通信、主机名称、用户、挂载点、网络等方面的隔离机制。通过具体的C程序示例,详细展示了如何利用clone()系统调用来创建具有不同名称空间的子进程。
本文深入探讨了Docker中名称空间技术的实现原理及其在进程ID、进程间通信、主机名称、用户、挂载点、网络等方面的隔离机制。通过具体的C程序示例,详细展示了如何利用clone()系统调用来创建具有不同名称空间的子进程。
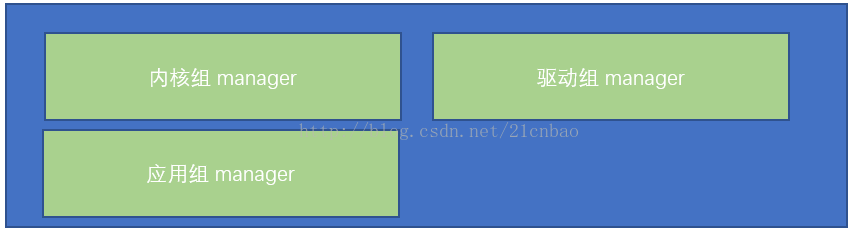
名称空间是在OS之上实现容器与主机隔离,以及容器之间互相隔离的Linux内核核心技术。根据《Docker 最初的2小时(Docker从入门到入门)》一文,名称空间本质上就是在不同的工作组里面封官许愿,让大家在各自的部门里面都是manager,而且彼此不冲突。本文接下来从细节做一些讨论。
由于本文敲的命令既有可能位于主机,又有可能位于新的名称空间(模拟容器),为了避免搞乱你的脑子,下面主机命令一概采用本颜色,而模拟容器类的命令一概采用本颜色。色盲读者,敬请谅解。
名称空间是什么?
名称空间(Namespace),它表示着一个标识符(identifier)的可见范围。一个标识符可在多个名称空间中定义,它在不同命名空间中的含义是互不相干的。这样,在一个新的名称空间中可定义任何标识符,它们不会与任何已有的标识符发生冲突,只要已有的定义都处于其他命名空间中。再次回忆一下这个封官许愿图,大家都是官:
名称空间是C++、Java里面常见的概念。比如下面最简单的程序,在2个独立的名称空间里面各自的函数都是叫func(),func就是一个标识符(identifier),可以并存于多个名称空间。
#include <iostream>
using namespace std;
// 第一个命名空间
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
// 第二个命名空间
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
int main ()
{
// 调用第一个命名空间中的函数
first_space::func();
// 调用第二个命名空间中的函数
second_space::func();
return 0;
}

所以,内核需要提供某种意义上的抽象,让各个容器感觉自己拥有独立的OS,让它们自己运行的时候觉得不是在一个整体的OS里面运行,而是各个容器感觉自己独有一个OS,这个OS最好和底层实际的主机资源隔离,才能实现容器运行的平台无关性。这个抽象可以从这几个角度展开:
进程的ID(PID)
现在每个容器内部的进程应该拥有独立的PID,不能在同一个OS的一个大池子里面(尽管实际上是,但是在容器内部要意识不到)。典型的,在Linux里面,init进程的PID是1,容器化后,应该每个容器都有一个1以及由1衍生的子进程和子进程的子进程(子子孙孙无穷匮)。但是这个容器内部的1进程,在容器内部它是1,但是最终它肯定是属于底下那个同一个OS大池子里面的某一个PID。
类似你在上海呼叫电话号码88888888,和在武汉呼叫电话号码88888888,在各自的城市都觉得是88888888,但是在全国(底下唯一的kernel)范围内则分别是021-88888888和027-88888888。
这种映射关系类似于:
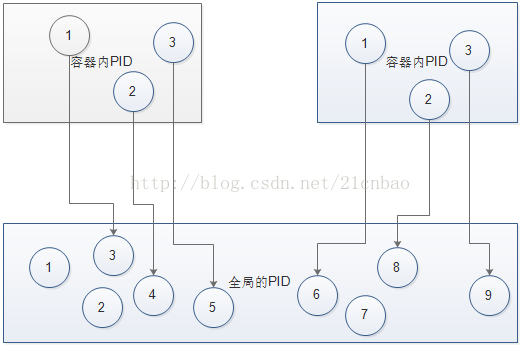
进程间通信(IPC)
与PID类似,在容器内部的进程间通信应该被从全局的Linux的进程间通信隔离开来。在没有名称空间的情况下,Linux System V IPC都会有各自的ID。譬如:
$ ipcs
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
0x00000000 524288 baohua 600 524288 2 dest
0x00000000 327681 baohua 600 1048576 2 dest
0x00000000 425986 baohua 600 524288 2 dest
…
------ Semaphore Arrays --------
key semid owner perms nsems
0x002fa327 0 root 666 2
------ Message Queues --------
key msqid owner perms used-bytes messages
但是在各个容器内部,ID与ID之间应该互相隔离。容器内部应该看不到主机的IPC,而一个容器也看不到另外一个容器的IPC。譬如在这台主机上跑Ubuntu 14.04的bash,目前还没有发现IPC:
baohua@baohua-VirtualBox:~$ docker run -it --rm ubuntu:14.04 bash
root@0c7951083f70:/# ipcs
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems
------ Message Queues --------
key msqid owner perms used-bytes messages
主机名称(UTS)
要让容器各自感觉独立,那么从底层的主机名独立也是很重要的。比如,我的主机名现在可以通过hostname命令获取:
baohua@baohua-VirtualBox:~/develop/linux$ hostname
baohua-VirtualBox
baohua@baohua-VirtualBox:~/develop/linux$ docker run -h container -it --rm ubuntu:14.04 bash
root@container:/# hostname
container
这样容器内部的进程,就不觉得自己在“baohua-VirtualBox”这个机器上面跑。
如果我们docker run中不指定hostname,会有一个随机分配的数值做hostname:
baohua@baohua-VirtualBox:~$ docker run -it --rm ubuntu:14.04 bash
root@0c7951083f70:/# hostname
0c7951083f70
用户(User )
比如我用我的电脑,我是用baohua这个用户名。但是在Docker的容器里面,为了体现虚拟化的概念,容器肯定要和实际的主机分离,这个时候,容器里面应该有自己的用户名。
baohua@baohua-VirtualBox:~/develop/linux$ docker run -h container -it --rm ubuntu:14.04 bash
root@container:/#
看到这个root,我们会疑惑?它是否会拥有类似主机的root权限,比如甚至都可以跑到sysfs里面卸掉一个CPU?这个显然是不可能的:
root@container:/sys/devices/system/cpu/cpu1# sh -c 'echo 0 > online'
sh: 1: cannot create online: Read-only file system
因为在容器里面,sysfs都是只读的。实际上,我们并不太希望容器里面控制真实的主机。这个root权限发挥的作用,更多的是在容器内部,它针对虚拟化后的资源,拥有的root权限,比如可以在容器内部执行mount。
下面我们验证容器内部的root权限的作用:容器启动后,我们在根目录下创建文件1,并且在其中写入hello,之后在容器内创建用户名baohua,以baohua这个用户,再在1里面写入hello就不会有权限:
$ docker run -h container -it --rm ubuntu:14.04 bash
root@container:/# touch 1
root@container:/# echo hello > 1
root@container:/# useradd baohua
root@container:/# su baohua
baohua@container:/$ echo hello > 1
bash: 1: Permission denied
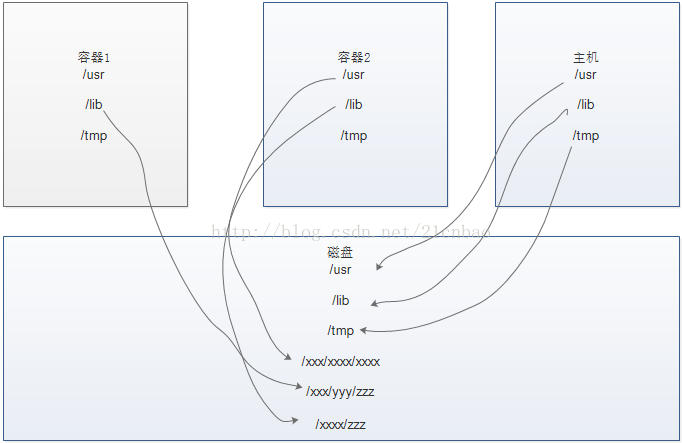
挂载(mount)
既然我们强调容器与主机的剥离,我们显然不应该把主机的文件系统暴露给容器内部。众所周知,Linux应用的运行不能没有根文件系统以及proc,sys,dev等特殊的文件系统。所以容器内部也不能不拥有自己的这些文件。但是另外一方面,容器内部看到的东西和主机看到的应该不一样,否则主机就直接暴露给了容器,不能体现虚拟化概念。Linux的mount名称空间可以实现不同mount 命名空间的进程看到的文件系统层次不一样。也就是说,不同的容器,以及容器与主机之间,可以出现不同目录结构;当然也可以出现相同的目录结构,但是他们在磁盘的位置可以不一样。
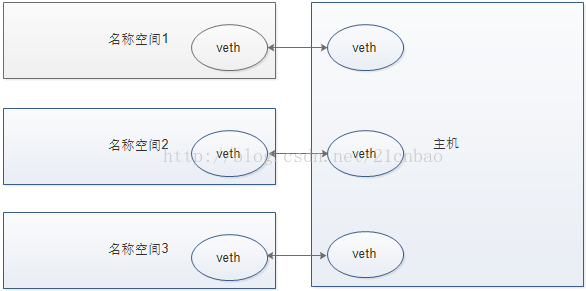
网络(network)
Linux如何支持名称空间
地球人都知道,Linux创建一个新的进程可以用fork()、vfork()和clone(),而它们在Linux内核的最底层都九九归一到do_fork()这个函数。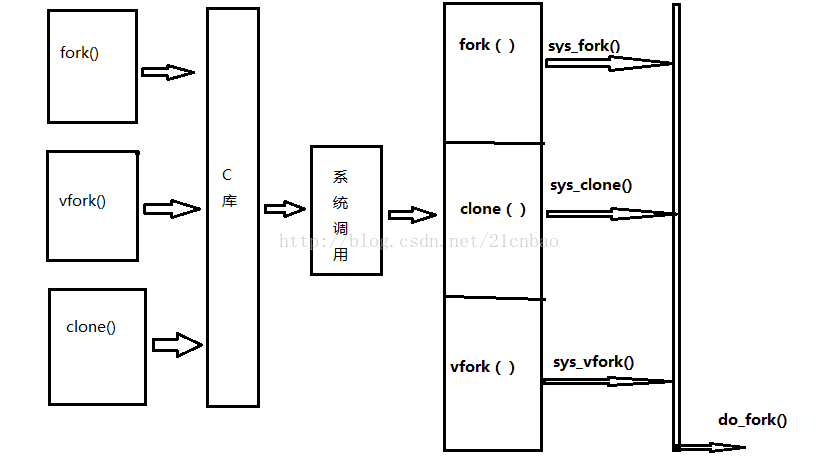
clone(child_stack=0xb6cf1424, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, …)下面我们在一个简单的C程序中逐步增加各种名称空间的支持,这个C程序中,我们用clone()创建一个子进程,并在子进程中调用exec()执行bash shell。在透过clone()创建子进程时,我们通过不同的clone FLAGS来使得子进程拥有独特名称空间。
第一步,无新名称空间
#define _GNU_SOURCE
#include <sched.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <signal.h>
#include <stdio.h>
#define STACK_SIZE (1024 * 1024)
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE); \
} while (0)
static char child_stack[STACK_SIZE];
int child_main(void *arg)
{
printf("child\n");
execlp("/bin/bash","bash",NULL,NULL);
return 1;
}
int main()
{
pid_t child_pid;
child_pid = clone(child_main,child_stack+STACK_SIZE,SIGCHLD,NULL);
if (child_pid == -1)
errExit("clone");
wait(NULL);
return 0;
}
baohua@baohua-VirtualBox:~/develop/training/namespace$ ./a.out
child
baohua@baohua-VirtualBox:~/develop/training/namespace$ echo $$
18374
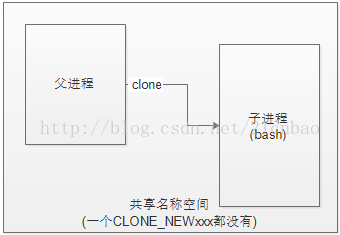
第二步,添加PID名称空间:
@@ -23,7 +23,7 @@ int child_main(void *arg)
int main()
{
pid_t child_pid;
- child_pid = clone(child_main,child_stack+STACK_SIZE,SIGCHLD,NULL);
+ child_pid = clone(child_main,child_stack+STACK_SIZE,SIGCHLD | CLONE_NEWPID,NULL);
if (child_pid == -1)
errExit("clone");
编译后运行:
$ sudo setcap all+eip ./a.out
[sudo] password for baohua:
baohua@baohua-VirtualBox:~/develop/training/namespace$./a.out
child
baohua@baohua-VirtualBox:~/develop/training/namespace$echo $$
1
前面一步setcap的目的是为了给程序执行CLONE_NEWPID的能力。后面echo $$显示的结果是1,子进程的bash shell是新的PID名称空间的init进程。但是在主机环节中,bash的PID是多少呢?运行命令ps --ppid:
$ ps --ppid `pidof a.out`
PIDTTY TIME CMD
19094 pts/8 00:00:00 bash
第三步,mount名称空间:
我们现在增加CLONE_NEWNS,然后mount proc等。修改2行代码:@@ -16,6 +16,7 @@ static char child_stack[STACK_SIZE];
int child_main(void *arg)
{
printf("child\n");
+ system("mount -t proc proc /proc");
execlp("/bin/bash","bash",NULL,NULL);
return 1;
}
@@ -23,7 +24,7 @@ int child_main(void *arg)
int main()
{
pid_t child_pid;
- child_pid = clone(child_main,child_stack+STACK_SIZE,SIGCHLD | CLONE_NEWPID,NULL);
+ child_pid = clone(child_main,child_stack+STACK_SIZE,SIGCHLD | CLONE_NEWPID | CLONE_NEWNS,NULL);
if (child_pid == -1)
errExit("clone");


$ touch ~/test-dir/1
$ echo hello > ~/test-file
只需要在child_main()函数里面增加一行代码:
mount("/home/baohua/test-dir","/mnt", "none", MS_BIND, NULL);sudo ./a.out
child
root@baohua-VirtualBox:~/develop/training/namespace# cd /mnt/
root@baohua-VirtualBox:/mnt# ls
1
root@baohua-VirtualBox:/mnt# cat 1
hello
baohua@baohua-VirtualBox:/mnt$ ls
hgfs
第四步:网络名称空间
现在在前面程序中clone()的flags增加CLONE_NEWNET,修改1行代码:
@@ -27,7 +26,8 @@ int child_main(void *arg)
int main()
{
pid_t child_pid;
- child_pid = clone(child_main,child_stack+STACK_SIZE,SIGCHLD |CLONE_NEWPID | CLONE_NEWNS,NULL);
+ child_pid = clone(child_main,child_stack+STACK_SIZE,SIGCHLD |CLONE_NEWPID |
+ CLONE_NEWNS |CLONE_NEWNET,NULL);root@baohua-VirtualBox:~/develop/training/namespace#ip link list
1: lo: <LOOPBACK> mtu 65536 qdiscnoop state DOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
而主机里面由于存在真实网卡等,内容十分丰富:
baohua@baohua-VirtualBox:~/develop/training/namespace$ifconfig
docker0 Link encap:Ethernet HWaddr00:00:00:00:00:00
inet addr:172.17.42.1 Bcast:0.0.0.0 Mask:255.255.0.0
…
eth0 Link encap:Ethernet HWaddr00:0c:29:ef:11:2f
inet addr:192.168.47.128 Bcast:192.168.47.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:feef:112f/64 Scope:Link
…
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
…
baohua@baohua-VirtualBox:~/develop/training/namespace$ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu65536 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP>mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:ef:11:2f brd ff:ff:ff:ff:ff:ff
3: docker0:<NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWNmode DEFAULT group default
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
root@baohua-VirtualBox:~/develop/training/namespace#ping 127.0.0.1
connect: Network is unreachable
root@baohua-VirtualBox:~/develop/training/namespace#ip link set dev lo up
root@baohua-VirtualBox:~/develop/training/namespace#ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes ofdata.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64time=0.035 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64time=0.022 ms
^C
--- 127.0.0.1 ping statistics ---
2 packets transmitted, 2 received, 0%packet loss, time 999ms
rtt min/avg/max/mdev =0.022/0.028/0.035/0.008 ms
下面查看a.out子进程bash在主机中的PID是21405(接下来添加虚拟网卡的时候需要这个数值):
$ ps --ppid `pidof a.out`
PIDTTY STAT TIME COMMAND
19093 pts/8 S 0:00 ./a.out
21405 pts/8 S+ 0:00 bash
$ sudo ip link add name veth0 type vethpeer name veth1 netns 21405
上述命令设置了连接的一对虚拟网络设备,它是这么工作的:发送给veth0的数据包将会被veth1收到,发送给veth1数据包将会被veth0收到。
我们进入新的名称空间的bash,敲如下命令,发现新的名称空间里面真的多出来veth1虚拟网卡!
root@baohua-VirtualBox:~/develop/training/namespace#ip link list
1: lo: <LOOPBACK> mtu 65536 qdiscnoop state DOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: veth1: <BROADCAST,MULTICAST> mtu 1500 qdisc noopstate DOWN mode DEFAULT group default qlen 1000
link/ether 3e:7a:86:a3:8b:9d brdff:ff:ff:ff:ff:ff
而主机上面则涌现出了新的veth0网卡:
$ ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu65536 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0:<BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP modeDEFAULT group default qlen 1000
link/ether 00:0c:29:ef:11:2f brd ff:ff:ff:ff:ff:ff
3: docker0:<NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWNmode DEFAULT group default
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
24: veth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noopstate DOWN mode DEFAULT group default qlen 1000
link/etherb2:80:d7:36:b5:84 brd ff:ff:ff:ff:ff:ff
在新名称空间内执行如下命令:
root@baohua-VirtualBox:~/develop/training/namespace#ifconfig veth1 10.1.1.1/24 up
主机上执行如下命令:
$ sudo ifconfig veth0 10.1.1.2/24 up
而后我们会发现在新名称空间可以ping通10.1.1.2,而主机可以ping通10.1.1.1,这样就实现了双向通信。
第五步:UTS名称空间
下面我们继续安置CLONE_NEWUTS 标记,来实现主机名的分裂。修改2行代码
@@ -19,6 +19,7 @@ int child_main(void *arg)
printf("child\n");
system("mount -t proc none /proc");
mount("/home/baohua/test-dir", "/mnt","none", MS_BIND, NULL);
+ sethostname("container",10);
execlp("/bin/bash","bash",NULL,NULL);
return 1;
}
@@ -27,7 +28,7 @@ int main()
{
pid_t child_pid;
child_pid = clone(child_main,child_stack+STACK_SIZE,SIGCHLD |CLONE_NEWPID |
- CLONE_NEWNS |CLONE_NEWNET,NULL);
+ CLONE_NEWNS | CLONE_NEWNET |CLONE_NEWUTS, NULL);
if (child_pid == -1)
errExit("clone");编译运行后,在bash中敲hostname命令,获取主机名,发现变为了“container”。
baohua@baohua-VirtualBox:~/develop/training/namespace$sudo ./a.out
[sudo] password forbaohua:
child
root@container:~/develop/training/namespace#hostname
container
第六步:USER名称空间
先看如下最简单的程序,只在clone()时候使用CLONE_NEWUSER:
#define _GNU_SOURCE
#include <sched.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <signal.h>
#include <stdio.h>
#define STACK_SIZE (1024 * 1024)
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE); \
} while (0)
static char child_stack[STACK_SIZE];
static int child_main(void *arg)
{
printf("child\n");
execlp("/bin/bash","bash",NULL,NULL);
return1;
}
int main()
{
pid_tchild_pid;
child_pid= clone(child_main,child_stack+STACK_SIZE,SIGCHLD | CLONE_NEWUSER, NULL);
if(child_pid == -1)
errExit("clone");
wait(NULL);
return0;
}baohua@baohua-VirtualBox:~/develop/training/namespace$gcc user.c
baohua@baohua-VirtualBox:~/develop/training/namespace$./a.out
child
nobody@baohua-VirtualBox:~/develop/training/namespace$
在子进程对应的shell里面,敲id命令,看一下自身的ID,发现都是65534:
nobody@baohua-VirtualBox:~/develop/training/namespace$id
uid=65534(nobody)gid=65534(nogroup) groups=65534(nogroup)
clone()用了CLONE_NEWUSER的参数后,子进程运行于新的USER名称空间,内部看到的UID和GID已经与外部不同了,在默认情况下以ID 65534运行。
其实我们可以把主机的ID,与新USER名称空间的ID进行一个映射,比如我们启动子进程的时候,实际上是以baohua这个用户启动的,则说明bash子进程,在主机对应的用户是baohua。但是,在新的名称空间内部,它究竟映射到哪个用户呢?这个我们可以通过修改进程的/proc/pid/uid_map和/proc/pid/gid_map这2个文件来进行ID的内外映射。
主机里面baohua的ID是1000:
$ id baohua
uid=1000(baohua)gid=1000(baohua)groups=1000(baohua),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),108(lpadmin),124(sambashare),131(docker)
我们现在把uid 1000对应的baohua映射到新名称空间内部的root用户(uid为0),在主机中运行如下命令:
$ ps --ppid `pidofa.out`
PID TTY TIME CMD
27321 pts/6 00:00:00 bash
我们手动进行映射:
$ sudo sh -c 'echo 01000 1 > /proc/27321/uid_map'
$ sudo sh -c 'echo 01000 1 > /proc/27321/gid_map'
之后在子进程再次敲id命令,发现重大不同。
nobody@baohua-VirtualBox:~/develop/training/namespace$id
uid=0(root)gid=0(root) groups=0(root),65534(nogroup)
发现自身的uid、gid变为了0。接下来,只用su -就可以让shell显示root@。
下面我们用程序实现这个过程:
#define _GNU_SOURCE
#include <sched.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <sys/mount.h>
#include <signal.h>
#include <stdio.h>
#define STACK_SIZE (1024 * 1024)
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE); \
} while (0)
static char child_stack[STACK_SIZE];
static void set_map(char* file, intinside_id, int outside_id)
{
FILE*mapfd = fopen(file, "w");
if(NULL == mapfd) {
perror("openfile error");
return;
}
fprintf(mapfd,"%d %d %d", inside_id, outside_id, 1);
fclose(mapfd);
}
static void set_uid_map(pid_t pid, int inside_id,int outside_id)
{
charfile[256];
sprintf(file,"/proc/%d/uid_map", pid);
set_map(file,inside_id, outside_id);
}
static void set_gid_map(pid_t pid, intinside_id, int outside_id)
{
charfile[256];
sprintf(file,"/proc/%d/gid_map", pid);
set_map(file,inside_id, outside_id);
}
static int child_main(void *arg)
{
sleep(1);//wait for 1 second to make certain uid_map and gid_map is written
printf("child\n");
system("mount-t proc none /proc");
mount("/home/baohua/test-dir","/mnt", "none", MS_BIND, NULL);
sethostname("container",10);
execlp("/bin/bash","bash",NULL,NULL);
return1;
}
int main()
{
pid_tchild_pid;
child_pid= clone(child_main,child_stack+STACK_SIZE,SIGCHLD | CLONE_NEWPID |
CLONE_NEWNS| CLONE_NEWNET | CLONE_NEWUTS | CLONE_NEWUSER, NULL);
if(child_pid == -1)
errExit("clone");
set_uid_map(child_pid,0, getuid());
set_gid_map(child_pid,0, getgid());
wait(NULL);
return0;
}上述代码中,父进程会通过set_uid_map()和set_gid_map()这2个函数,进行新名称空间内部的用户0与主机的用户1000的映射。由于子进程执行bash之前延迟了1秒,所以我们在子进程进入shell的时候,它已经直接是root用户了:
$ ./a.out
child
root@container:~/develop/training/namespace#
那么,它针对主机资源的实际权限是不是root呢,实验一下它是否可以访问/dev/sda1:
root@container:~/develop/training/namespace#cat /dev/sda1
cat: /dev/sda1:Permission denied
下面我们在bash里面启动一些stress进程:
root@container:~/develop/training/namespace#stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 100000s&
[1] 46
直接在新名称空间内看ps:
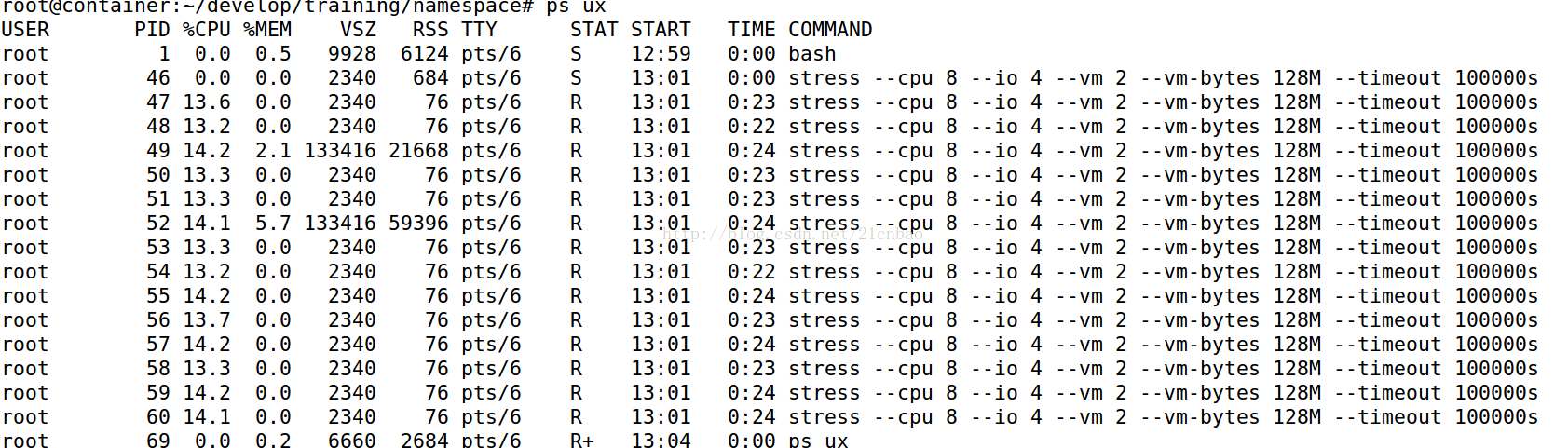
但是我们在主机里面看ps呢?
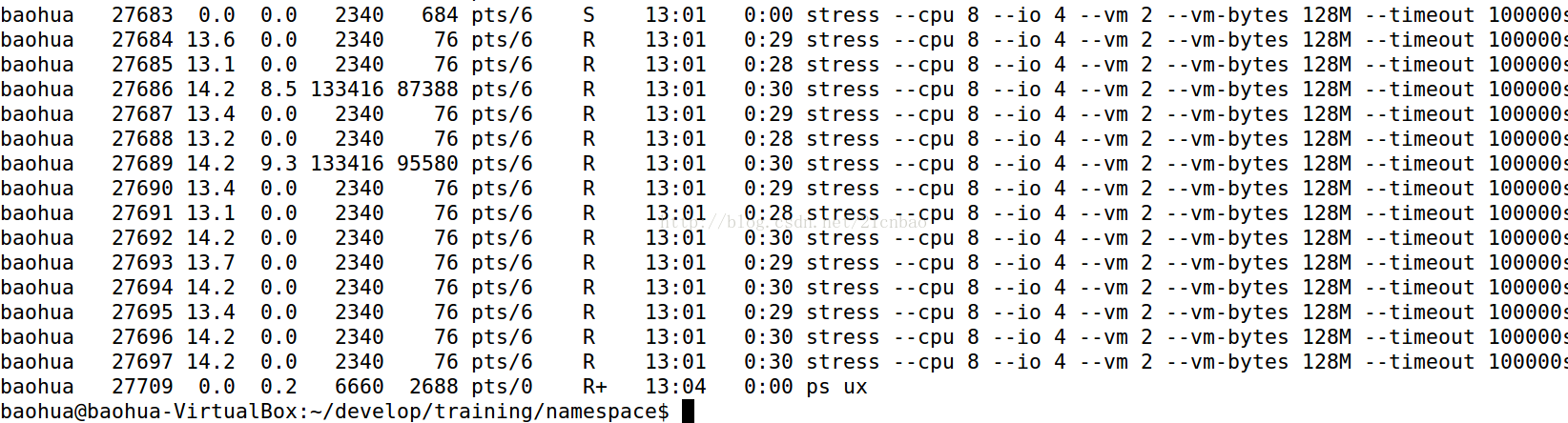
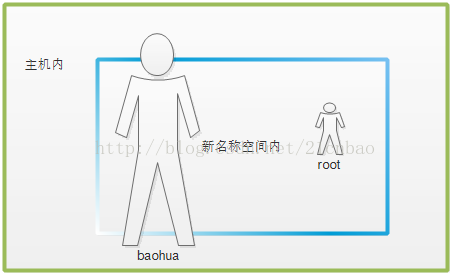
我们则发现,所有的stress进程在主机里面都是对应用户baohua的,而在新的名称空间里面则是root。
所以这个关系类似:


















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











