







Improving Multiview Face Detection with Multi-Task Deep Convolutional Neural Networks
概述:这是一篇基于深度卷积神经网络的人脸检测论文,达到了很好的效果,同时速度相比起其他深度学习系的方法也有所提高。
算法流程:
1. 作者先使用几个级联的 Multiview detector来对输入图片进行初步鉴别,以此来剔除掉大量的非人脸图片。
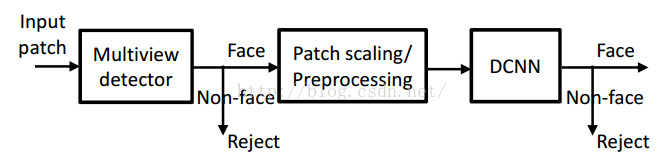
2. 接着再将通过第一步的图片进行一些pre-processed,然后输入到作者自己训练的一个DCNN里面去,得到最终的结果(包括是否是face,face pose,face landmarks)。
算法具体实现过程:
1. 构造训练集(略,有兴趣的读者请自行阅读论文)。
2. 使用boosting-based的集成学习方法(参考 C. Zhang and Z. Zhang. Winner-take-all multiple category boosting for multi-view face detection. In ECCV Workshop on Face Detection: Where are we, and what next, 2009. 1, 2),训练得到级联多视角人脸检测model。事实上,其他多视角人脸检测model也是可以应用到这里的,因此我就不特地讲解这个boosting-based算法了。特别注意的是,我们应该慎重地选择该级联检测器的阈值,以达到True Positive Rate和False Positive Rate的平衡。
3. 图像预处理,第一步使用standard histogram equalization来增强图像的对比度,第二步使用一个线性变换来再次修改图片光强,该线性变换如下:
ax+by+c=I
其中(x,y)代表像素坐标,使用最小二乘法来计算获得参数a,b,c,进而用I-ax-by-c来作为该坐标点新的光强。
第三步再进行归一化处理,至此图像预处理完成。
其主要效果是增强对比度以及移除阴影(或者说使得阴影更加容易辨识)。
4. 训练DCNN
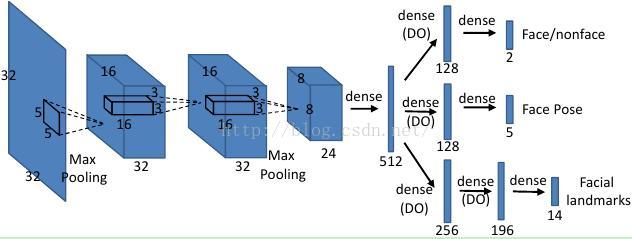
作者构建的DCNN结构如图所示:
值得注意的是,作者的模型的输出包括三者:face/non-face,face pose,facial landmarks
针对输出的不同,在训练过程中使用的loss函数也是不通的,如下:
1. face/non-face输出2个值,其loss函数为交叉熵函数:
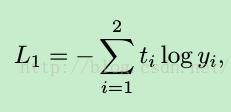
2. face pose输出5个值,分别代表不同的脸部朝向,loss函数也是交叉熵函数:
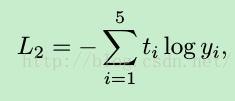
3. facial landmark输出14个值,分别对应7个landmarks的坐标,其loss函数是一个weighted mean square error:
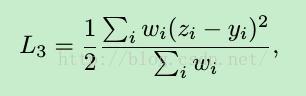
结合三者,总的loss函数为三者的线性组合:
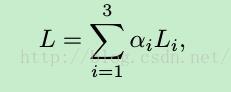
训练细节以及参数我在此就不一一贴出,有兴趣的读者请自行学习。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









