







 Bloom Filter是一种用于检索元素是否存在于大规模集合中的数据结构,它使用位数组和多个哈希函数来减少空间占用并降低误判率。在Java中,可以使用BitSet实现位数组操作。虽然可能会有误判,但绝不会漏判,适用于处理海量数据的场景,如垃圾邮件过滤。
Bloom Filter是一种用于检索元素是否存在于大规模集合中的数据结构,它使用位数组和多个哈希函数来减少空间占用并降低误判率。在Java中,可以使用BitSet实现位数组操作。虽然可能会有误判,但绝不会漏判,适用于处理海量数据的场景,如垃圾邮件过滤。
算法介绍
Bloom Filter的中文名称叫做布隆过滤器,因为他最早的提出者叫做布隆(Bloom),因而而得此名。布隆过滤器简单的说就是为了检索一个元素是否存在于某个集合当中,以此实现数据的过滤。也许你会想,这还不简单,判断元素是否存在某集合中,遍历集合,一个个去比较不就能得出结果,当然这没有任何的问题,但是当你面对的是海量数据的时候,在空间和时间上的代价是非常恐怖的,显然需要更好的办法来解决这个问题,而Bloom Filter就是一个不错的算法。具体怎么实现,接着往下看。
Bloom Filter
先来说说传统的元素检索的办法,比如说事先在内存中存储了一堆的url字符数组,然后给定一个指定的url,判断是否存在于之前的集合中,我们肯定是加载整个数组到内存中,然后一个个去比较,假设每条url字符平均所占的量只有几个字节,但是当数据变为海量的时候,也足以撑爆整个内存,这是空间上的一个局限。再者,逐次遍历的方式本身就是一种暴力搜索,搜索的时间将会随着集合容量的本身而线性扩展,一旦数据量变大,查询时间上的开销也是非常恐怖的。针对时间和空间上的问题,Bloom Filter都给出了完美的解决办法。首先第一个空间的问题,原本的数据占用的是字符,在这里我们用1个位占据,也就是说1个元素我用1/8的字节表示,不管你的url长度是10个字符,100字符,统统用一个位表示,所以在这里我们需要能够保证每个字符所代表的位不能冲突。因为用到了位的存储,我们需要对数据进行一个hash映射,以此得到他的位置,然后将此位置上的位置标为1(默认都是为0)。所以说白了,Bloom Filter就是由一个很长的位数组和一些随机的哈希函数构成。位数组你可以想象成下面的这种形式:

你可以想象这个长度非常长,反正1个单位就占据1个位,1k的空间就已经能够表示1024*8=8192位了。所以说内存空间得到了巨大的节约。现在一个问题来了,为什么我刚刚用了一些随机的哈希函数这个词而不是说一个呢,因为会有哈希碰撞,再好的哈希函数也不能保证不会发生哈希冲突,所以这里需要采用多个哈希函数,所以元素是否存在的判断条件就变为了只有所有的哈希函数映射的位置的值都是true的情况下,此元素才是存在于集合中的,这样判断的准确率就会大大提升了,哈希映射之后的效果图如下:
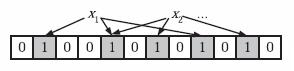
假设我们的程序采用了如上图所示的3个随机独立的哈希函数,1个元素需要进行3次不同的哈希函数的映射算法,对3个位置进行标记,对此元素的误判概率我们做个计算,要使此元素误判,就是说,他的这3个位置都有人占据了,就是说都与别的哈希函数有冲突,这最糟糕的情况就是他的3个映射位置与某个其他的元素通过哈希函数计算完全重叠,假设位空间长度1W位。每个位置被映射的概率就为1/1w,所以最糟糕的情况的冲突概率就是1/1w*1/1w*1/1w=1/10的12次方,如果最大的冲突概率的可能性呢,就是每个位置都与其中的某个哈希函数映射冲突,那误差概率就是叠加的情况1/1w+1/1w+1/1w=0.0003。结果已经非常明显了,通过3个哈希函数就已经能够保证足够低的误判率了,更别说当你用4个,5个哈希函数做映射的情况。下面问
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









