







传统蒙古文的书写形式是从上到下,从左到有的形式。所以跟其他语言的OCR不一。不过流程都差不多,灰度化,然后查找文字图片,然后进一步识别比对或机器学习,然后识别出相应文字。
1.灰度化

首先打开测试图片。放大两倍,然后二值化(灰度化)。灰度化很简单,代码如下:
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
base_dir = "C:/Users/AyonA333/Desktop/"
path_test_image = os.path.join(base_dir, "data.png")
image_color = cv2.imread(path_test_image)
new_shape = (image_color.shape[1], image_color.shape[0])
image_color = cv2.resize(image_color, new_shape)
image = cv2.cvtColor(image_color, cv2.COLOR_BGR2GRAY)
adaptive_threshold = cv2.adaptiveThreshold(
image,
255,
cv2.ADAPTIVE_THRESH_GAUSSIAN_C,\
cv2.THRESH_BINARY_INV, 11, 2)
cv2.imshow('binary image', adaptive_threshold)
cv2.waitKey(0)

2.垂直分割
horizontal_sum = np.sum(adaptive_threshold, axis=0)
plt.plot(horizontal_sum, range(horizontal_sum.shape[0]))
plt.gca().invert_yaxis()
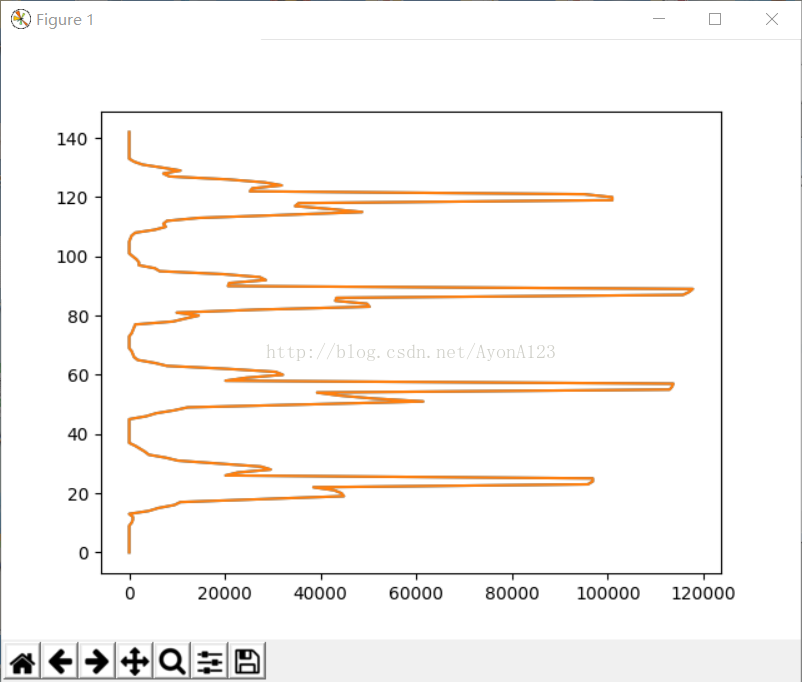
plt.show()二值化以后图片成为一个矩阵,所以每列相加以后可以大概的能知道每列的具体范围,方便于切割每列文字。python的num的有关矩阵的相加如下:
计算出来的值用matplotlib显示出来后:
3.垂直每列文字切割
def extract_peek_ranges_from_array(array_vals, minimun_val=1000, minimun_range=2):
start_i = None
end_i = None
peek_ranges = []
for i, val in enumerate(array_vals):
if val > minimun_val and start_i is None:
start_i = i
elif val > minimun_val and start_i is not None:
pass
elif val < minimun_val and start_i is not None:
end_i = i
if end_i - start_i >= minimun_range:
peek_ranges.append((start_i, end_i))
start_i = None
end_i = None
elif val < minimun_val and start_i is None:
pass
else:
raise ValueError("cannot parse this case...")
return peek_ranges
peek_ranges = extract_peek_ranges_from_array(horizontal_sum)
line_seg_adaptive_threshold = np.copy(adaptive_threshold)
for i, peek_range in enumerate(peek_ranges):
x = peek_range[0]
y = 0
w = peek_range[1]
h = line_seg_adaptive_threshold.shape[0]
pt1 = (x, y)
pt2 = (x + w, y + h)
cv2.rectangle(line_seg_adaptive_threshold, pt1, pt2, 255)
cv2.imshow('line image', line_seg_adaptive_threshold)
cv2.waitKey(0)
vertical_peek_ranges2d = []
for peek_range in peek_ranges:
start_x = 0
end_x = line_seg_adaptive_threshold.shape[0]
line_img = adaptive_threshold[start_x:end_x,peek_range[0]:peek_range[1]]
#cv2.imshow('binary image', line_img)
vertical_sum = np.sum(line_img, axis=1)
#plt.plot(vertical_sum, range(vertical_sum.shape[0]))
#plt.gca().invert_yaxis()
#plt.show()
vertical_peek_ranges = extract_peek_ranges_from_array(vertical_sum,minimun_val=2,minimun_range=1)
vertical_peek_ranges2d.append(vertical_peek_ranges)
print(vertical_peek_ranges2d)

显示切割出来的一列如下:

4.切割每个列的文字
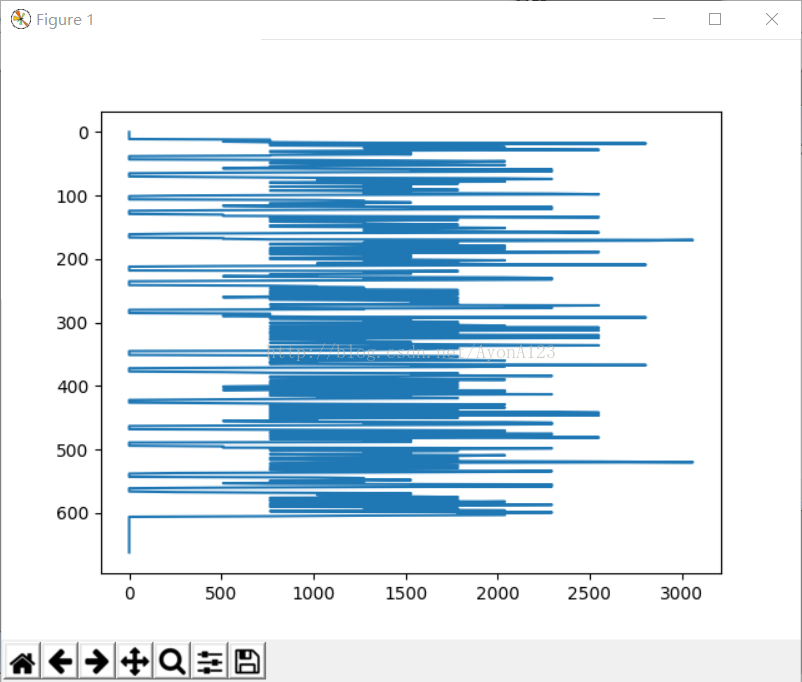
显示一个列的矩阵值如上,按矩阵的横向最小值来分割出每列的文字。
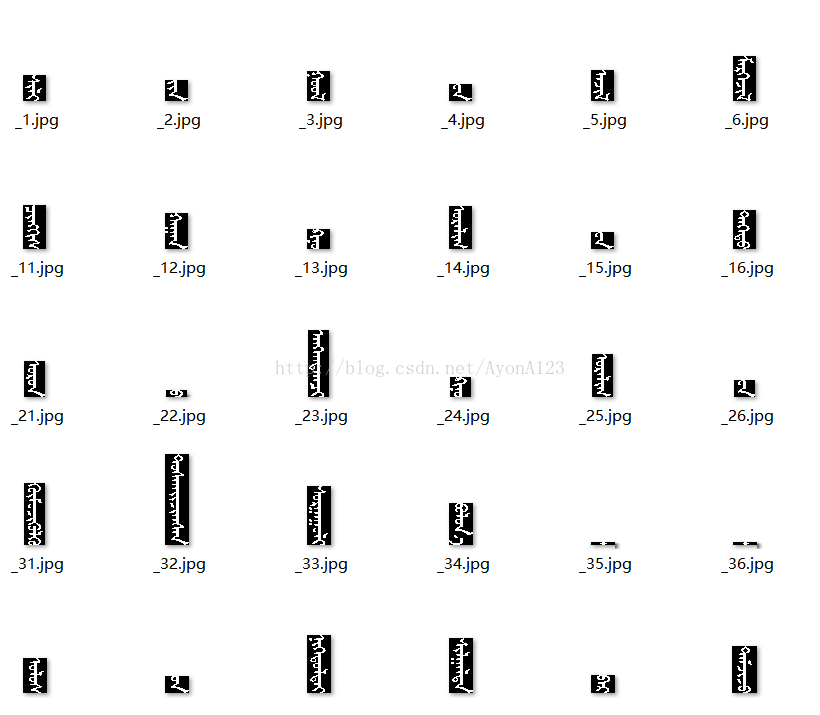
cnt = 1
color = (0, 0, 255)
for i, peek_range in enumerate(peek_ranges):
for vertical_range in vertical_peek_ranges2d[i]:
x = peek_range[0]
y = vertical_range[0]
w = peek_range[1] - x
h = vertical_range[1] - y
#print(str(x)+'-'+str(y)+'-'+str(w)+'-'+str(h))
patch = adaptive_threshold[y:y+h,x:x+w]
cv2.imwrite('C:/Users/AyonA333/Desktop/testpic/'+'_%d' %cnt+'.jpg', patch)
cnt += 1
pt1 = (x, y)
pt2 = (x + w, y + h)
cv2.rectangle(image_color, pt1, pt2, color)
cv2.imshow('char image', image_color)
cv2.waitKey(0)
这样第二部可以做深度学习训练了。
学习交流QQ/Wechat:286436416














 4680
4680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









