







这篇博客主要是讲爬虫的一点基础知识,为后面的爬虫实战做准备。
Python访问互联网主要是使用urllib包中的几个模块,我们可以打开Python的文档来查看一下这个urllib包。

我们主要是使用urllib.request模块中的urlopen方法。

这个函数中除了第一个参数url——即我们要抓取的网页的网页的地址,其余参数都可以使用默认的参数。
简单说一下URL:
URL的一般格式:(带方括号[]为可选项)
protocol://hostname[:port]/path/[;parameters][?query]#fragment
URL由三部分组成:
第一部分是协议:http,https,ftp,file,edk2
第二部分是存放资源的服务器的域名系统或IP地址
(有时候包含端口号,各种传输协议都有默认的端口号)
第三部分是资源的具体地址
我们通过一个简单的例子来体会一下爬虫是怎么工作的。
加入我们要从网页上抓取一张图片。

我们找到图片后可以在图片上右键单击图片,然后选择检查,在网页的源代码中找到图片的地址。
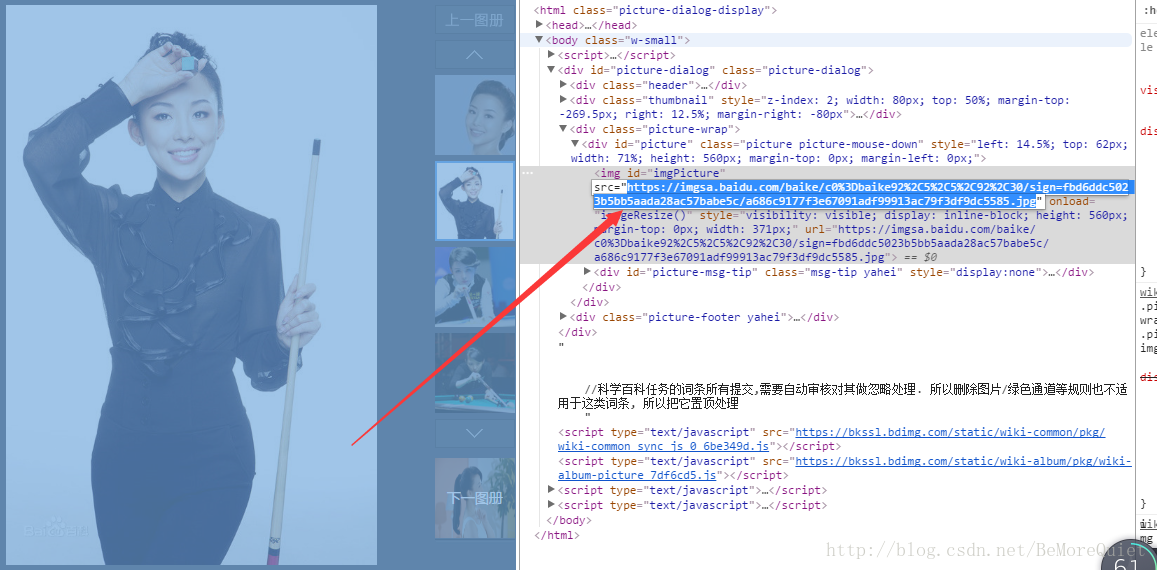
这样抓取之前的准备工作就做好了,下面开始写代码:
#导入所需要的模块
import urllib.request
#调用模块中的urlopen方法,该方法返回的是一个文件
response=urllib.request.urlopen('https://imgsa.baidu.com/baike/c0%3Dbaike92%2C5%2C5%2C92%2C30/sign=fbd6ddc5023b5bb5aada28ac57babe5c/a686c9177f3e67091adf99913ac79f3df9dc5585.jpg')
#使用read()方法读取文件中的内容,二进制的形式
girl_img=response.read()
#以二进制的形式将文件写入本地
with open('E:\\panxiaoting.jpg','wb') as f:
f.write(girl_img)上述代码执行后,在E盘便会生成panxiaoting.jpg的图片
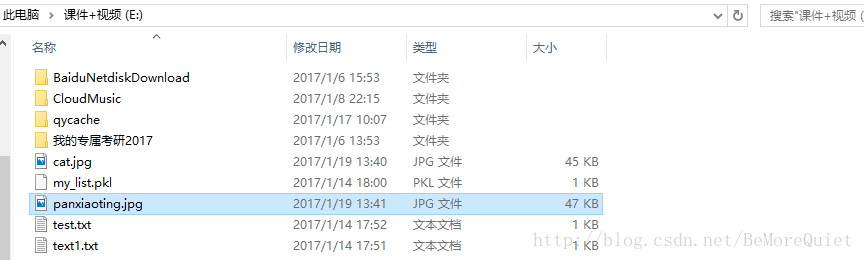
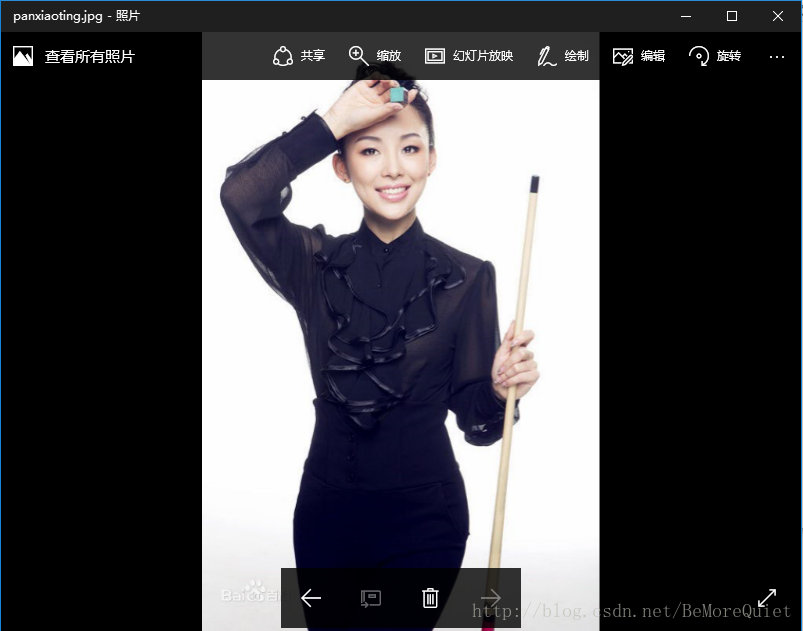
这样这张照片就被抓取下来了,可能你会说,右键另存为不更快吗?的确,一张两张图片可能右键另存为会更快,如果要批量下载,代码就会更快一些,这个简单的例子只是用来介绍一下urillib的用法,下一篇博客将通过有道词典的例子进一步学习爬虫的相关知识。
本例中图片为网上随意抓取,如有侵权,请您告知。














 3607
3607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









