







1.Overview
有关dzd文档基本信息及dzd格式转换程序Txt2Dzd参看这里.
查找有关dzd文档的资料,首先想到的就是官方网站.www.englishto.com上有很多dzd文档和英语通客户端软件,我下载了for PPC和for JAVA两个版本.首先在IDA里面反汇编了for PPC的客户端,被那些ARM指令搞得一头雾水后决定试一下JAVA版本.
我以前没有接触过java只是听说java字节码可以反编译地很好,就到网上找到了小颖Java反编译器,确实不错几乎还原了源代码,想不到碟中碟原来是另类开源啊,顿时肃然起敬.这些代码比那些ARM指令可爱多了,其中最可爱的一句代码是private boolean IS_ZM(char n);( IS_字母!),作者居然还煞有其事地实现了一把.难到J2ME里连isalpha这样的函数都没有提供么?不说废话了,开始我们的逆向之旅.
有关软件反编译的法律问题参看这里.
2.Start
工具
十六进制编辑器UltraEdit
小颖Java反编译器
Windows calculator
代码
拿到java客户端的源代码,我们最关心的就是它的文件I/O,只需要知道文档的大致结构就行.
下面是BookView类的构造函数的代码片段,读入一些文档基本信息:
InputStream Input = getClass().getResourceAsStream("ebook.jeb");
DataInputStream eBookFileHandle = new DataInputStream(Input);
程序只读取ebook.jeb文件,显然不是我们所要研究的dzd文档,但我猜想既然同出于碟中碟门下文档结构肯定是大同小异的,很可能是出于同一工程师手中,后面证明我的猜想没错.
m_byBookCount = eBookFileHandle.readByte();读取章节数目chapcount,作者用byBookCount为变量名不知何意.
int nMaxCount = eBookFileHandle.readInt();
m_cBookData = new char[eBookFileHandle.readInt()];读取文档数据大小BookDatacount
m_nFilesNameLen = eBookFileHandle.readInt();读取文档标题字符个数NameLen
m_pnBookNameInfo = new int[nMaxCount + 20];
for(int i = 0; i < nMaxCount; i++) m_pnBookNameInfo[i] = eBookFileHandle.readInt(); 读取文档信息bookinfo
m_pBookLineInfo = new byte[2 * m_byBookCount + 2 * nMaxCount];分配行信息lineinfo存储空间
eBookFileHandle.read(m_pBookLineInfo, 0, 2 * m_byBookCount);读取部分行信息
接下来是ShowBook函数的代码片段:
InputStream Input = getClass().getResourceAsStream("ebook.jeb");
DataInputStream eBookFileHandle = new DataInputStream(Input);依然读取这个文件
eBookFileHandle.skip(m_pnBookNameInfo[m_byUserCfgData[9]]); BookNameInfo[m_byUserCfgData[9]]中存储文件偏移plineinfo
eBookFileHandle.read(m_pBookLineInfo, 2 * m_byBookCount, m_pnBookNameInfo[m_byBookCount + m_byUserCfgData[9]] * 2);读取部分行信息
m_nECharNum = m_pnBookNameInfo[m_byBookCount * 2 + m_byUserCfgData[9]]; BookLineInfo中有英文字符数
m_nCCharNum = m_pnBookNameInfo[m_byBookCount * 3 + m_byUserCfgData[9]]; BookLineInfo中有中文字符数
for(int k = 0; k < m_nECharNum;){
m_cBookData[i] = (char)eBookFileHandle.readByte();读取文档英文数据,ASCII字符
k++;
i++;
}
for(int k = 0; k < m_nCCharNum;){
m_cBookData[i] = eBookFileHandle.readChar();读取文档中文数据,Unicode字符串
k++;
i++;
}
再研究一下其他函数,我们差不多了解了jeb文档大致结构.推测dzd文档结构大致相似也分成若干章节.阅读时中英文行与中文行间隔分开,可知它是行结构的,而非txt文档的松散无结构.dzd文档有一段行信息控制行中断,其中一个字节代表一行英文字符数下一字节代表一行中文字符数这样交替.
对比
知道大致结构后可以用UltraEdit进一步分析以上的数据在文档中的位置.到英语通网站上找几篇标准dzd文档, 在UltraEdit中对比.只要找出几篇标准文档中控制信息不同的地方,有的软件提供文件比较这个功能,不过我还是只用UltraEdit,外加肉眼观察.可以发现英文字符以前的全是控制数据,共有十几处不同,分别对应上文中提到的变量.大部分都是数值数据(心算不好的话可以用计算器进行十六进制与十进制间的转换),你可以根据文档大小、标题字符个数等等相关信息进行猜测和验证.这种猜测是逆向工程中最重要的一步. 当所有字节的意义都明白以后就可以写出一个生成dzd文档的程序了.
由于操作dzd文档的java源代码已经给出,这里的猜测很简单.但是如果给出的是反汇编代码就真的需要费一些心思了,需要你对编译器生成的汇编代码很熟悉,因为现在的反汇编器的抽象能力是极其有限的.要时刻把自己想象成开发者,想象他遇到这个问题怎么解决.在这种猜测的过程中有可能几个字节的意义使你苦思冥想数天而不得其解,你却在不经意之间灵光闪现,那种感觉恐怕正是逆向的魅力所在.从某种意义上来说,逆向工程是与自然科学研究有着微妙的联系.科学家们对物质世界进行研究进而改造世界不也正是一种逆向么?
如图: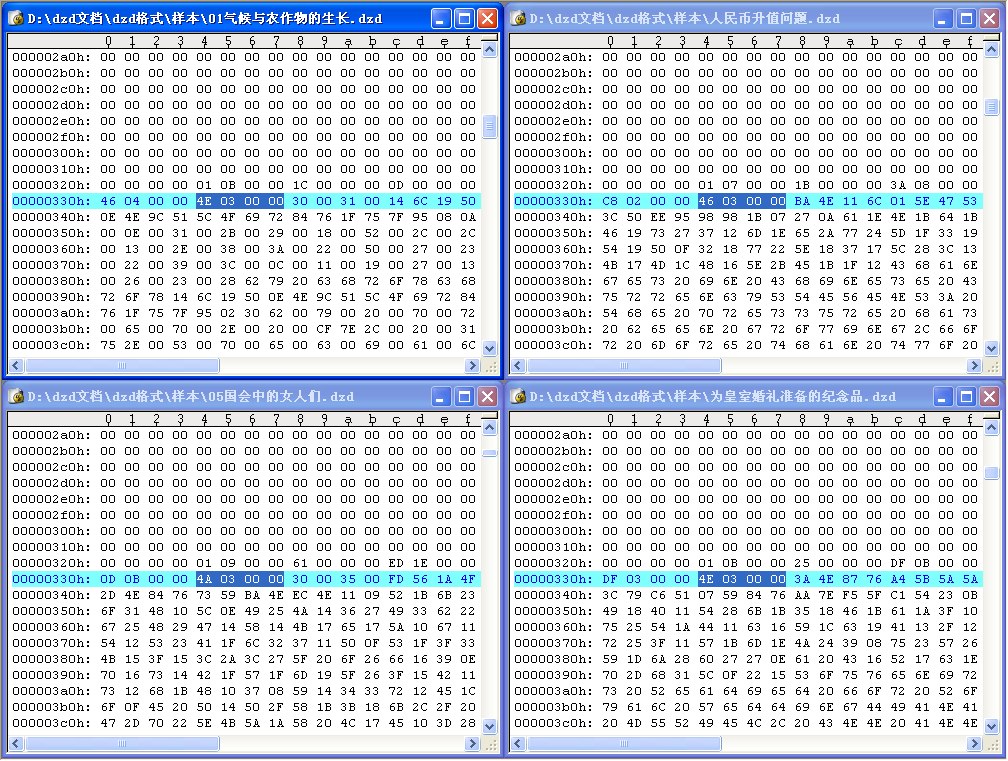
附dzd文档结构:
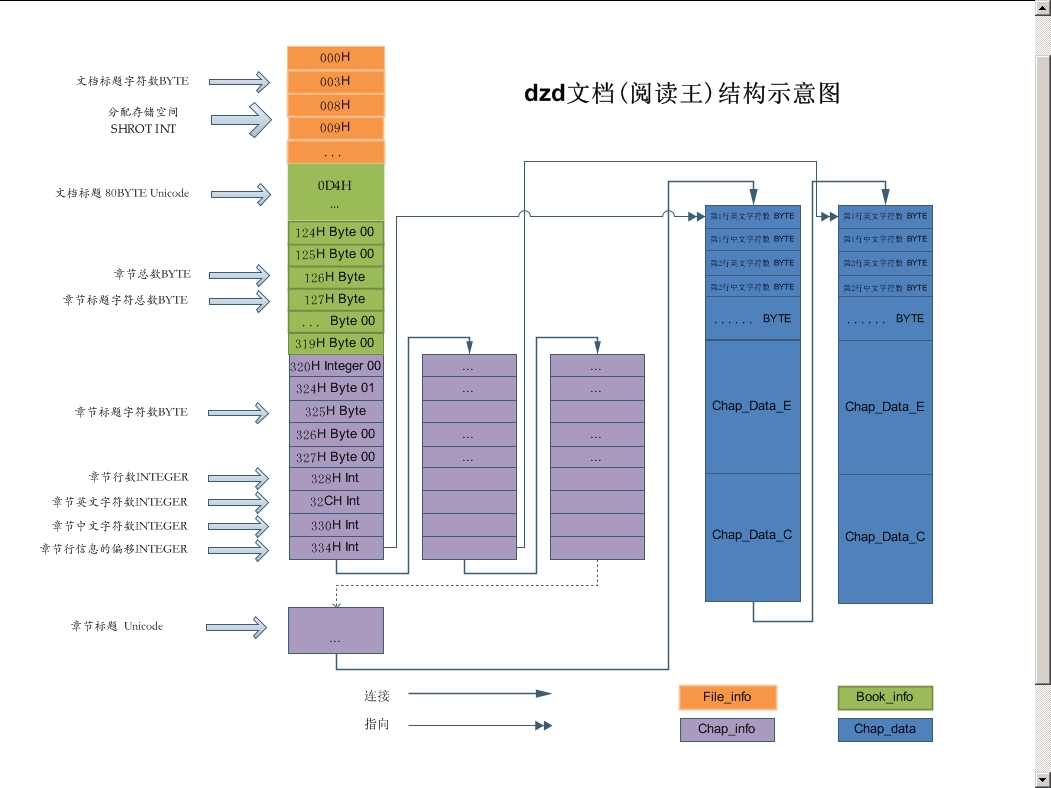















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









