









什么是二叉排序树
它表示一棵二叉树,并且包含以下性质:
1)可能是一棵空树
2)若不为空,那么其左子树结点的值都是小于根结点的值,右子树结点的值都是大于根结点的值
3)左右子树都是二叉树。对于二叉排序树功能的介绍
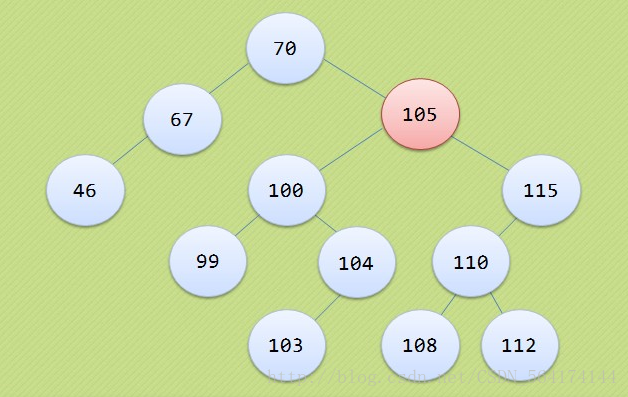
本文主要介绍的是二叉排序树的几种基本操作,包括查找、插入和删除操作。用到的二叉排序树如下图所示:
- 二叉排序树的建立
- 二叉树结点的创建:
typedef struct BiTNode
{
int data;
struct BiTNode *lchild,*rchild,*parent;
}BiTNode,*BiTree;- 二叉排序树的创建过程
二叉排序树的创建过程。主要包含两个部分:二叉排序树的创建和插入每个结点的过程。主要就是利用递归操作插入结点。具体过程如下:
- 申请一个结点p的空间,存储数据和左右子树的指针。
- 几种情况的判断:
- 1.判断是否为空树,空树时,插入的节点直接为根结点
- 2.插入结点的值>根结点的值,插入结点直接设置为右孩子。设置方式:根结点的右孩子子针直接连接插入结点。
- 3.插入结点的值<根结点的值,插入结点直接设置为左孩子。设置方式 : 根结点的左孩子子针直接连接插入结点。
- 4.进行递归操作。继续插入下个结点,此时的根结点就是刚刚插入的结点。
//创建一棵二叉排序树
void create(BiTree* root,int* keyArray,int length )
{
int i;
for(i=0;i<length;i++)
insert(root,keyArray[i]);
}
//插入每个结点
void insert(BiTree* root,int data)
{
//初始化插入的节点
BiTree p=(BiTree)malloc(sizeof(BiTNode));
p->data=data;
p->lchild=p->rchild=NULL;
//空树时,直接最为根结点
if((*root)=NULL)
{
*root=p;
return;
}
//插入到当前结点的左孩子
if((*root)->lchild==NULL&&(*root)->data>data)
{
p->parent=(*root);
(*root)->lchild=p;
return;
}
if((*root)->rchild==NULL&&(*root)->data<data)
{
p->parent=(*root);
(*root)->rchild=p;
return;
}
if((*root)->data>data)
insert(&(*root)->lchild,data);
else if((*root)->data<data)
insert(&(*root)->rchild,data);
else
return;
}-二叉排序树的搜索和插入操作
二叉排序树的搜索过程:
- 二叉树是否存在
- 搜索结点的值是否等于T的值
- 如果搜索结点的值小于T的值,那就进行递归操作继续搜索T的左子树。
- 如果搜索结点的值大于T的值,那就进行递归操作继续搜索T的右子树。
二叉排序树的插入操作主要包括以下几个过程:
- 1.首先判断插入结点,和树中结点是否存在重复,这时候用到的是结点的搜索操作,若没有重复的节点,就进行后面的插入操作。
- 2.创建一个新结点,存储插入结点的值。
- 3.如果是空树,插入结点直接插入进去。
- 4.如果树不为空,插入结点的值小于最后一个结点的值,插入结点连接最后一个结点的左子树;插入结点的值大于最后一个结点的值,插入结点连接最后一个结点的右子树。
/*
当二叉排序树T中不存在关键字key的数据元素时,插入key并返回true,否则返回false.
*/
BiTree SearchBST(BiTree T,int key,BiTree f,BiTree * p)
{
if(!T)
{
*p=f;
return NULL;
}
else if(key==T->data)
{
*p=T;
return *p;
}
else if(key<T->data)
{
return SearchBST(T->lchild,key,T,p);
}
else
return SearchBST(T->rchild,key,T,p);
}
BiTree InsertBTS(BiTree *T ,int key)
{
BiTree p,s;
//判断经过二叉树的查找,是否找得到所需结点
if(!SearchBST(*T,key,NULL,&p))
{
//找不到结点,那首先生成一个结点(不存在重复结点)
s=(BiTree)malloc(sizeof(BiTNode));
s->data=key;
s->lchild=NULL;
s->rchild=NULL;
if(!p)//最后一个结点是否在树里面,进入循环表示树不为空,进入查找。
{
*T=s;
}
if(key<p->data)
{
s=p->lchild;
}
else
{
s=p->rchild;
}
return s;
}
else
{
return NULL;
}
}
.
查找删除结点操作
- 判断键值是否等于当前结点的值,等于直接调用删除函数。
- 如果键值小于当前结点的值,则递归调用查找删除结点,若值小于此结点的值,递归传入左子树,若大于递归传入右子树。
删除操作主要包含三种情况:
定义删除结点为p结点,q指针用于传递。
- 删除结点的右子树为空的情况下
把p结点的地址传给q指针,再把p的左子树的值传递给p,最后释放q。 - 删除结点的左子树为空的情况下
把p结点的地址传给q指针,再把p的右子树的值传递给p,最后释放q。 - 删除结点的左右子树都不为空
这种情况的主要思想是用删除结点的直接前驱去替换这个结点的值,最后只需要释放直接前驱的结点即可,框架结构是不需要调整的。(下面的删除方式是以找到左子树的直接前驱结点为例)
1.q指针指向删除结点的位置,s指针指向删除结点的左子树。
2.然后循环搜索直接前驱结点,并用s指针指向这个前驱结点,q指向前驱结点的双亲节点。
3.进行判断,如果删除的结点就是前驱结点的双亲节点,那么直接就把双亲节点替换到前驱结点的位置。如把99替换到100的位置。如果存在前驱结点的子树,那么就把删除结点的左子树连接前驱结点的左子树。例如103放到100的位置上。
4。最后释放前驱结点。
BiTree Delete(BiTree *p)
{
BiTree q,s;
//右子树为空的情况下
if((*p)->rchild==NULL)
{
q=*p;
*p=(*p)->lchild;
free(q);
}
else if((*p)->lchild==NULL)
{
q=*p;
*p=(*p)->rchild;
free(q);
}
//以直接前驱做替换
else
{
q=*p;
s=(*p)->lchild;
while(s->rchild)
{
q=s;
s=s->rchild;
}
(*p)->data=s->data;
if(q!=*p)
{
q->rchild=s->lchild;
}
else
{
q->lchild=s->lchild;
}
free(s);
}
return s;
}
//删除二叉树模块
BiTree DeleteBST(BiTree *T ,int key)
{
if(!*T)
{
return NULL;
}
else
{
if(key==(*T)->data)
return Delete(T);
else if(key<(*T)->data)
{
return DeleteBST(&((*T)->lchild),key);
}
else
{
return DeleteBST(&(*T)->rchild,key);
}
}
}













 5545
5545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









