









引言
爬虫已经有很多了,我在网上找了很多,但是都不能执行,于是敲了一份新鲜的,拿出来分享,应该可以直接运行,执行前请查看python版本。
版权所有:CSND_Ayo,转载请注明出处:http://blog.csdn.net/csnd_ayo
文章最后更新时间:2017年4月2日 22:13:45
简介
编程IDE:Pycharm 2016.1.2
开发环境:Python 3.6.1
操作系统:Window 7
赏析
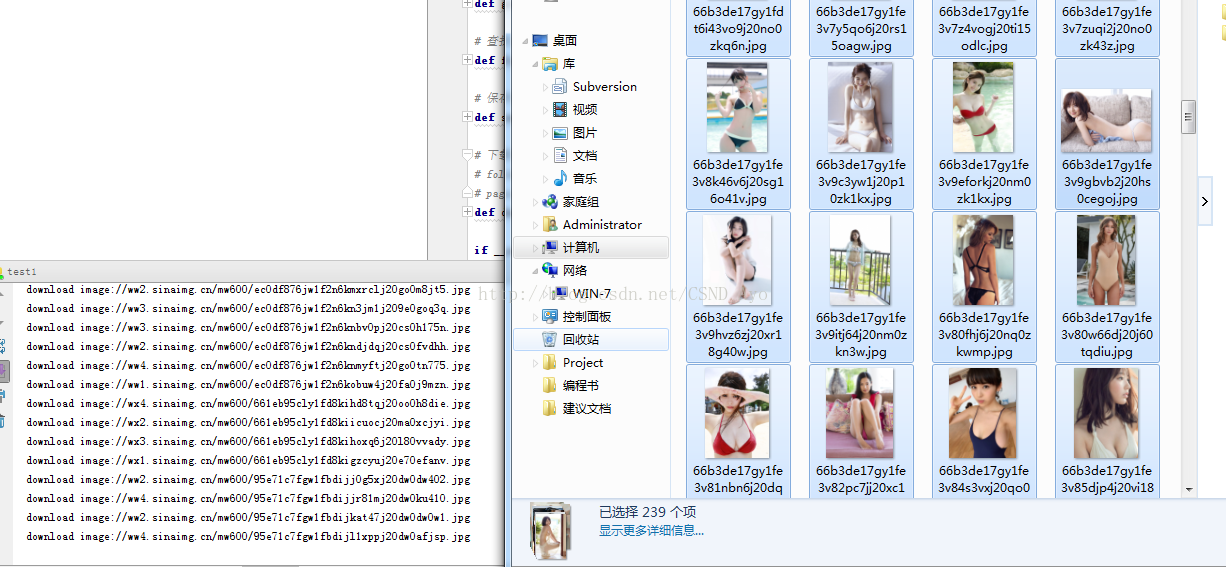
源码
代码注释已经无比清晰,就不再过多赘述了。
# -*- coding:utf-8 -*-
#
# 爬虫系列 - http://jandan.net/ooxx/
# 作者:陈鲁勇
# 邮箱:727057301@qq.com
# 撰写时间:2017年4月2日 22:06:54
# Python版本:3.6.1
# CSDN:http://blog.csdn.net/csnd_ayo
#
import urllib.request
import os
import time
# 打开URL,返回HTML信息
def open_url(url):
# 根据当前URL创建请求包
req = urllib.request.Request(url)
# 添加头信息,伪装成浏览器访问
req.add_header('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36')
# 发起请求
response = urllib.request.urlopen(req)
# 返回请求到的HTML信息
return response.read()
# 查找URL中的下一页页码
def get_page(url):
# 请求网页,并解码
html=open_url(url).decode('utf-8')
# 在html页面中找页码
a=html.find('current-comment-page')+23
b=html.find(']',a)
# 返回页码
return html[a:b]
# 查找当前页面所有图片的URL
def find_imgs(url):
# 请求网页
html=open_url(url).decode('utf-8')
img_addrs=[]
# 找图片
a = html.find('img src=')
#不带停,如果没找到则退出循环
while a != -1:
# 以a的位置为起点,找以jpg结尾的图片
b = html.find('.jpg',a, a+255)
# 如果找到就添加到图片列表中
if b != -1:
img_addrs.append(html[a+9:b+4])
# 否则偏移下标
else:
b=a+9
# 继续找
a=html.find('img src=',b)
return img_addrs
# 保存图片
def save_imgs(img_addrs):
for each in img_addrs:
print('download image:%s'%each)
filename=each.split('/')[-1]
with open(filename,'wb') as f:
img=open_url("http:"+each)
f.write(img)
# 下载图片
# folder 文件夹前缀名
# pages 爬多少页的资源,默认只爬10页
def download_mm(folder='woman',pages=10):
folder+= str(time.time())
# 创建文件夹
os.mkdir(folder)
# 将脚本的工作环境移动到创建的文件夹下
os.chdir(folder)
# 本次脚本要爬的网站
url='http://jandan.net/ooxx/'
# 获得当前页面的页码
page_num=int(get_page(url))
for i in range(pages):
page_num -= i
# 建立新的爬虫页
page_url=url+'page-'+str(page_num-1)+'#comments'
# 爬完当前页面下所有图片
img_addrs=find_imgs(page_url)
# 将爬到的页面保存起来
save_imgs(img_addrs)
if __name__ == '__main__':
download_mm()














 398
398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









