










烽驿2009开源实时通信平台 源码获取:svn checkout http://fy2009.googlecode.com/svn/trunk/ fy2009-read-only
笔者在博文《系统localtime性能评测》
(http://blog.csdn.net/DreamFreeLancer/archive/2009/05/06/4155180.aspx)中曾提及日志对于大型服务
器软件的重要性。从工程支持的角度,日志当然是越多越详细越好,但这往往意味着高的内存及CPU消耗,
另外,如果大量日志组织不当,也会给技术人员的日志查阅带来严重挑战。方便,高效,组织良好的日志
服务是软件架构设计的重要内容之一。
下面将讨论本项目所采用的一种高性能日志服务。日志服务通常应满足以下几点要求:应尽量不影响或少
影响系统主要功能的完成品质,作为实现,应尽量不阻塞执行主要功能的线程; 其次,日志输出主要供工程
技术人员查阅,因此,日志输出应被良好地格式化; 另外,日志应被良好的分类组织,以利于查阅。为满足
上述要求,本项目的日志服务整合了在先前的博文中陆续讨论过的若干特色技术: 为加快格式化日志信息
,使用了string_builder_t(相关博文:
http://blog.csdn.net/DreamFreeLancer/archive/2009/05/14/4184014.aspx); 为了尽量不影响系统功能
性线程的流畅运行,实际的日志输出被放到后台独立线程中完成,即采用异步日志服务,凡功能性线程需
输出日志,都只是将格式化好的日志信息通过极有特色的高性能线程间通信手段oneway_pipe_t(相关博
文:http://blog.csdn.net/DreamFreeLancer/archive/2009/06/01/4231151.aspx)传给后台日志线程; 另
外,为提高时间戳的生成效率,采用了高效的用户空间时间服务user_clock_t(相关博文:
http://blog.csdn.net/DreamFreeLancer/archive/2009/05/12/4169710.aspx)。该日志服务统一由实现
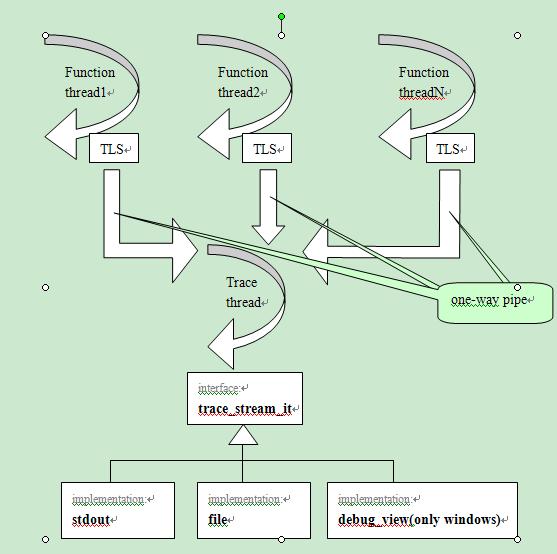
为Singleton的trace_provider_t提供,日志服务在使用前需调用其open()函数以启动后台日志线程,结束
使用时应调用相应的close()函数以关闭日志线程,这两项工作通常由主线程完成,另外,每个需要写日志
的线程还需要调用register_tracer()函数为其分配一个专用的oneway_pipe_t,并注册到其线程局部存储
(TLS)中,其后,来自该线程的日志信息都将通过该oneway_pipe_t传送到日志线程。日志线程则遍历所有
将其注册为读线程的oneway_pipe_t,读取其中的日志信息,并按指定的日志分类策略写到指定的
trace_stream_it介质中。
为体现日志的重要程度,可以对日志进行为类,其中预定义的分类有以下几类:
TRACE_LEVEL_ERROR //表示系统发生了错误
TRACE_LEVEL_WARNI //表示系统发生了通常不应发生的情况,但不确定是错误
TRACE_LEVEL_INFOI //重要的提示信息
TRACE_LEVEL_INFOD //详细的提示信息
TRACE_LEVEL_FUNC //用于跟踪函数的调用栈
使用者可自定义其它的分类,但缺省情况下,分类总数不能超过MAX_TRACE_LEVEL_COUNT(32)。
日志的格式如下:
<ts=2009-06-08 08:59:50.858><tid=16384><I><f=fyt_stream.cpp><l=1123>--hello, from trace provider test
ts:日志时间戳,由日志服务自动生成
tid:线程ID,由日志服务自动生成
I: 为日志级别代号,其中E为Error; W为Warning; I为INFOI; D为INFOD;F为FUNC;自定义类型为X#,#代表级别号
f: 产生日志的源代码文件
l: 产生日志的源代码行数
“--”号后面部分为调用者格式化输出的部分。
调用 register_trace_stream()函数可为指定的日志分类定义输出介质,根据输出策略的不同, 一条日志
信息可被输出到一至多个trace_stream_it介质上。通过对trace_stream_it的不同实现,可将日志输出到
stderr, stdout,文件,DebugView(windows)下,或通过Socket在网络上传输。其中输出到文件时允许指定每个文件的最大尺寸,每天允许最多生成多少个日志文件,当前日志文件尺寸到达上限时,将生成另一个新的日志文件,当天日志文件数到达上限时,最初生成的文件将被覆盖,文件名将包含进程名,年月日,进程ID,日志级别,和每日文件序号。
例如:fy2009test.exe_1544_20090608_d_0.log--<进程名>_<进程ID>_YYYYMMDD_<trace level token>_<index>.log.
实际的日志输出通过形如FY_ERROR(exp),FY_XERROR(exp);FY_WARNING(exp);FY_XWARNING(exp)
宏输出,它们的参数都支持"<<"流运算符以格式化输出。
另外,既可通过预编译宏禁用或启用某级别的日志,也可通过调用set_enable_flag()函数动态禁用或启用
某级别的日志。
总之,该日志服务方便,高效且灵活,但存在以下问题值得注意:
1.来自不同线程中的日志,即使写在同一个日志文件中,其先后顺序也不意味着任何时序假设。即比较同一
日志文件中来自不同线程的日志的先后顺序是没有意义的
2.日志时间戳的精度受user_clock_t的限制,通常在10ms在右,即日志时间戳中10ms以下的时间显示通常
是不准确的
3.如果后台日志线程太忙,或写日志介质时被阻塞,或写的日志过多,导致日志线程不能及时将日志写入介
质时,部分日志可能会被丢弃,通过访问日志服务,你可以知道总共被丢弃的日志条数,但没法知道具体内容,因为笔者认为为
了写日志而阻塞功能性服务无论如何都是不能接受的。
如果只是偶然出现丢日志的情况,可通过适当调大:
tracer_t *trace_provider_t::register_tracer(uint32 pipe_size=TRACE_DEF_NLP_SIZE,
uint32 max_queued_size=TRACE_DEF_MAX_QUEUED_SIZE,
...);
中的pipe_sizet和/或max_queued_size参数来调节。前者指在源线程和Trace线程间传递日志的oneway_pipe_size的尺寸,对应日志条数,缺省值为256;后者指源线程端尚未提交到oneway_pipe_t上的日志数量,缺省值为1024。
该日志服务的简单原理示意图参:https://p-blog.csdn.net/images/p_blog_csdn_net/dreamfreelancer/EntryImages/20090610/trace-provider.JPG














 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}