










前面的博客中,我给大家详细分析了caffe结构层面的抽象概念:
http://blog.csdn.net/errors_in_life/article/details/68948841
但是很多人还是存在很大的疑惑:到底怎么让自己的caffe跑起来,有真正的意义?开始训练数据?——事实上,我们需要caffe做的事情,正是利用他多变的网络结构来训练数据,所以,用caffe而不知道caffe如何训练数据等于白用;
今天我们试图通过一个DL中公认的鼻祖级别的简单例子:训练Lenet手写识别库,来说明这个问题;而这也被成为DL界的“hello world”.
一、caffe/data目录下有一个文件夹:叫mnist
mnist数据训练样本为60000张,测试样本为10000张,每个样本为28*28大小的黑白图片,手写数字为0-9,因此分为10类。
在caffe中是不带练习数据的,因此需要自己去下载。但在caffe根目录下的data文件夹里,作者已经为我们编写好了下载数据的脚本文件,我们只需要联网,运行这些脚本文件就行了。所以我们在命令行输入:
sudo sh data/mnist/get_mnist.sh //to download the data;
输入命令之后,我们可以看到联网的Ubuntu系统开始下载数据:
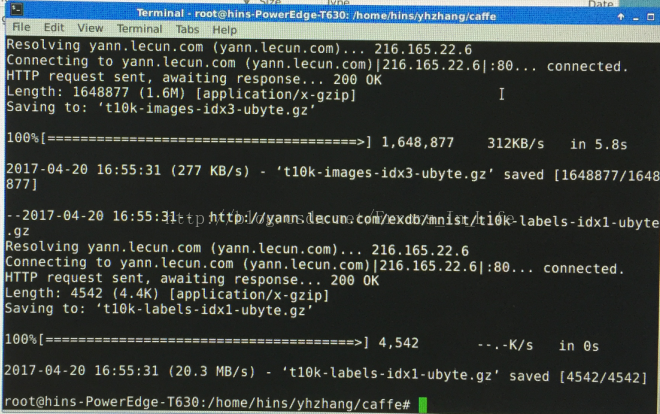
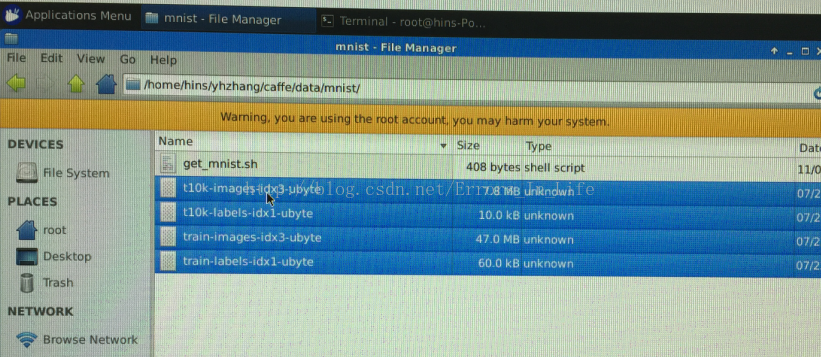
等待下载完成后,我们在文件夹 data/mnist/目录下可以看到四个文件下载完毕:
二、数据转换:
但是有一个比较尴尬的事实——这些数据不能在caffe中直接使用,需要转换成LMDB数据!所以,我们在命令行输入:
sudo sh examples/mnist/create_mnist.sh //you need to do it under the #~CAFFE_ROOT
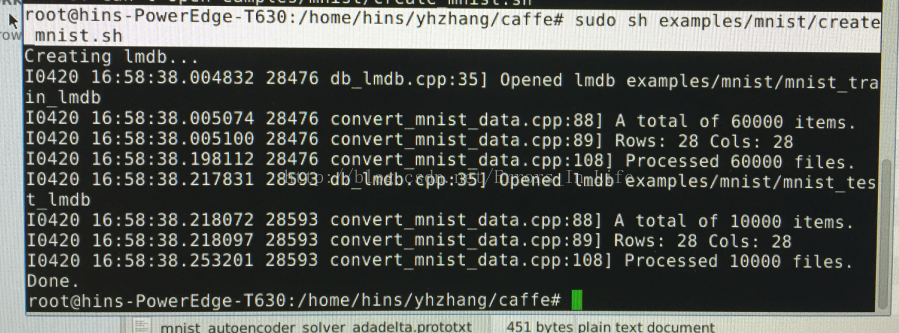
三、修改配置文件:
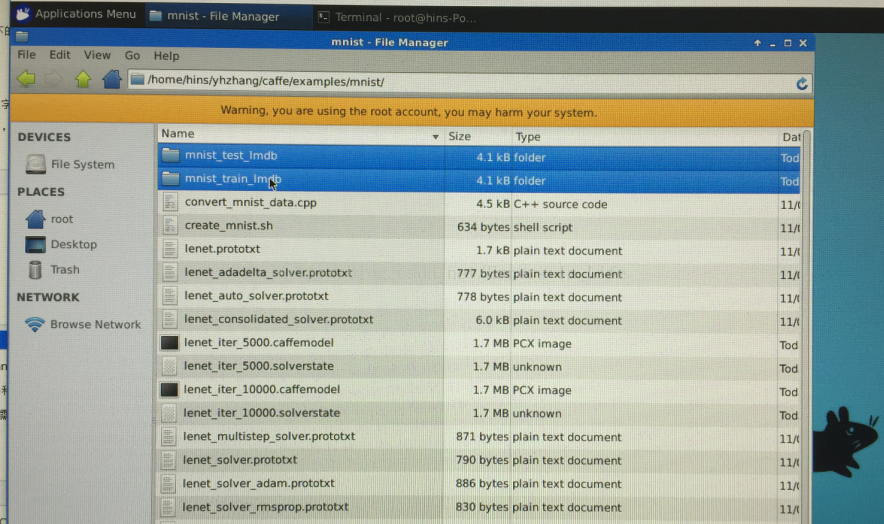
转换成功后,会在 examples/mnist/目录下,生成两个文件夹,分别是mnist_train_lmdb和mnist_test_lmdb,里面存放的data.mdb和lock.mdb,就是我们需要的运行数据。
接下来是修改配置文件,如果你有GPU且已经完全安装好,这一步可以省略,如果没有,则需要修改solver配置文件。需要的配置文件有两个:
一个是lenet_solver.prototxt,另一个是train_lenet.prototxt.
首先在命令行里面打开lenet_solver_prototxt
sudo vi examples/mnist/lenet_solver.prototxt
你就会得到界面如下图所示:
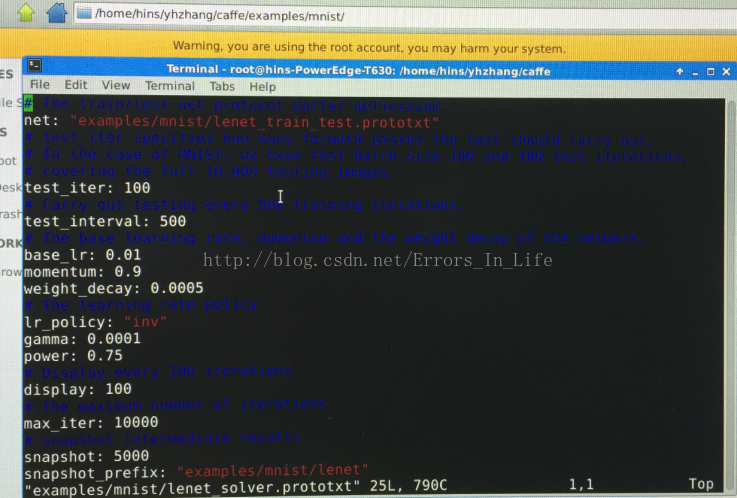
按着要求一项一项修改,就可以使得你的caffe正常运行;
四、跑起来:
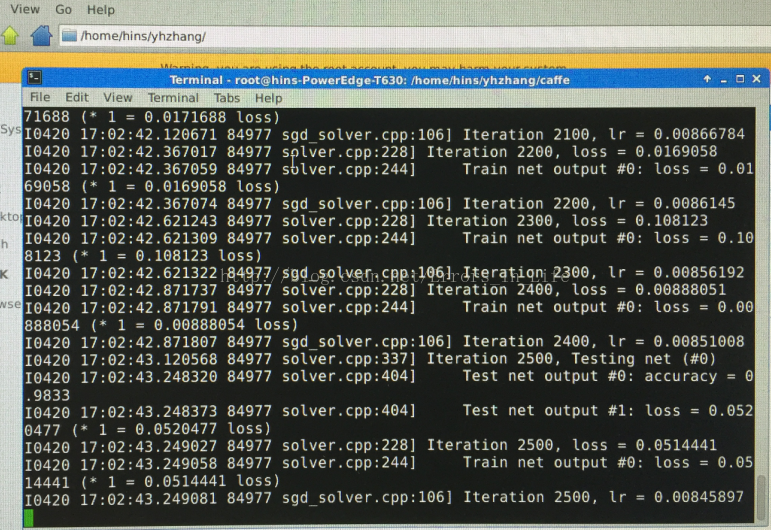
我们开始在命令行输入期待已久的训练Lenet数据的操作命令了:
sudo time sh examples/mnist/train_lenet.sh
这个训练时间根据具体事实来定义,我们实验室大概需要:30秒;
最后发现在目录:caffe/examples/mnist 下面会出现:.caffemodel的文件,这个就是我们训练出来的对应迭代次数5000、10000的训练数据!
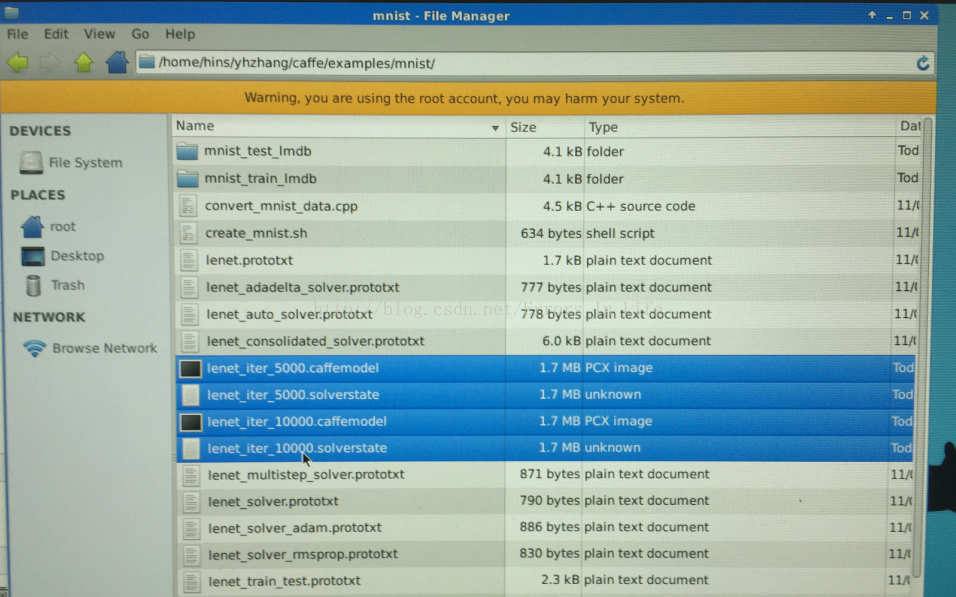
到这里,我们成功训练好了一个caffe的简单例子,这对于我们进一步熟悉、了解caffe有非常重要的意义!














 2056
2056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









