







林炳文Evankaka原创作品。转载请注明出处http://blog.csdn.net/evankaka
摘要:本文主要讲了如何将hadoop的运行结果存储到mysql
工程源码下载:https://github.com/appleappleapple/BigDataLearning/tree/master/Hadoop-Demo
此文接:Hadoop实战演练:搜索数据分析----TopK计算(2)在上中我们得到Hadoop输出的关键词搜索量TopK数据格式如下,这里将当成本文计算的输入数据
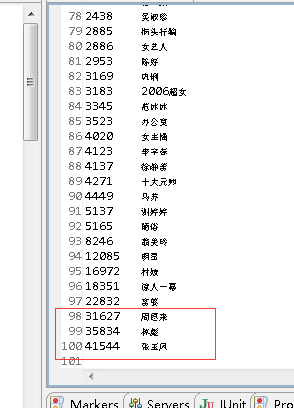
接下来我们要将这100条数据存储到Mysql
数据库建表语句:
CREATE TABLE `key_word` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`word` varchar(255),
`total` bigint(20),
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8package com.lin.keyword;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBOutputFormat;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* 功能概要:将top 搜索词保存到数据库
*
* @author linbingwen
*/
public class SaveResult {
/**
* 实现DBWritable
*
* TblsWritable需要向mysql中写入数据
*/
public static class TblsWritable implements Writable, DBWritable {
String tbl_name;
int tbl_age;
public TblsWritable() {
}
public TblsWritable(String name, int age) {
this.tbl_name = name;
this.tbl_age = age;
}
@Override
public void write(PreparedStatement statement) throws SQLException {
statement.setString(1, this.tbl_name);
statement.setInt(2, this.tbl_age);
}
@Override
public void readFields(ResultSet resultSet) throws SQLException {
this.tbl_name = resultSet.getString(1);
this.tbl_age = resultSet.getInt(2);
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.tbl_name);
out.writeInt(this.tbl_age);
}
@Override
public void readFields(DataInput in) throws IOException {
this.tbl_name = in.readUTF();
this.tbl_age = in.readInt();
}
public String toString() {
return new String(this.tbl_name + " " + this.tbl_age);
}
}
public static class StudentMapper extends Mapper<LongWritable, Text, LongWritable, Text>{
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
public static class StudentReducer extends Reducer<LongWritable, Text, TblsWritable, TblsWritable> {
@Override
protected void reduce(LongWritable key, Iterable<Text> values,Context context) throws IOException, InterruptedException {
// values只有一个值,因为key没有相同的
StringBuilder value = new StringBuilder();
for(Text text : values){
value.append(text);
}
String[] studentArr = value.toString().split("\t");
if(studentArr[0] != null){
String name = studentArr[1].trim();
int age = 0;
try{
age = Integer.parseInt(studentArr[0].trim());
}catch(NumberFormatException e){
}
context.write(new TblsWritable(name, age), null);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
DBConfiguration.configureDB(conf, "com.mysql.cj.jdbc.Driver","jdbc:mysql://localhost:3306/learning?serverTimezone=UTC","root", "linlin");
//设置hadoop的机器、端口
conf.set("mapred.job.tracker", "10.75.201.125:9000");
//设置输入输出文件目录
String[] ioArgs = new String[] { "hdfs://hmaster:9000/top_out"};
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 1) {
System.err.println("Usage: <in> <out>");
System.exit(2);
}
//设置一个job
Job job = Job.getInstance(conf, "SaveResult");
job.setJarByClass(SaveResult.class);
// 输入路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
// Mapper
job.setMapperClass(StudentMapper.class);
// Reducer
job.setReducerClass(StudentReducer.class);
// mapper输出格式
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
// 输入格式,默认就是TextInputFormat
job.setOutputFormatClass(DBOutputFormat.class);
// 输出到哪些表、字段
DBOutputFormat.setOutput(job, "key_word", "word", "total");
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
输出结果:
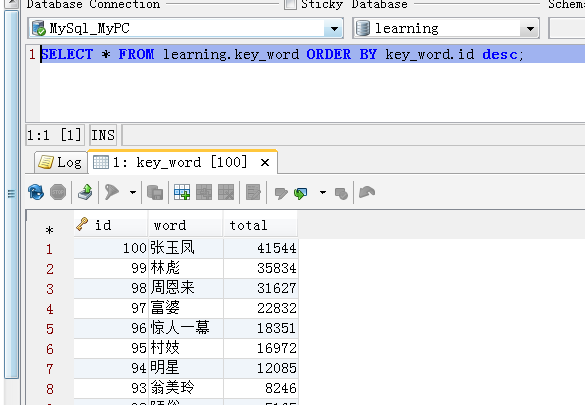
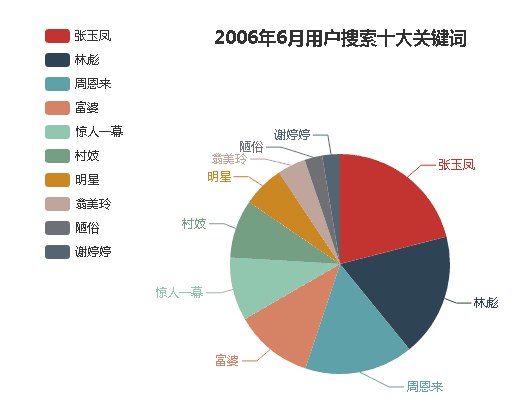
然后笔者用百度的Echars作了一个展示页面如下:















 153
153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









