






本文译自:http://storm.apache.org/documentation/Guaranteeing-message-processing.html
Storm会保证每个来自Spout的消息会被完全处理。本文介绍Storm是如何实现这种保证机制的,以及要让用户从Storm的可靠性能力中获益所要做的一些事情。
“完全处理的消息”意味着什么?
一个来自Spout的数据元组可能会触发基于这个这个数据元组所创建的数以千计的数据单元。例如,流式的单词计数的拓扑结构:
TopologyBuilderbuilder=newTopologyBuilder();
builder.setSpout("sentences",newKestrelSpout("kestrel.backtype.com",
22133,
"sentence_queue",
newStringScheme()));
builder.setBolt("split",newSplitSentence(),10)
.shuffleGrouping("sentences");
builder.setBolt("count",newWordCount(),20)
.fieldsGrouping("split",newFields("word"));
上述代码从Kestrel队列中读取语句,把单词分割到它们对应的单词单元,然后发送每个单词的统计计数。基于Spout输入的一个Tuple能够触发任意多个Tuple:一句话中的每个单词对应一个Tuple和一个更新计数的Tuple。消息树如下图所示:
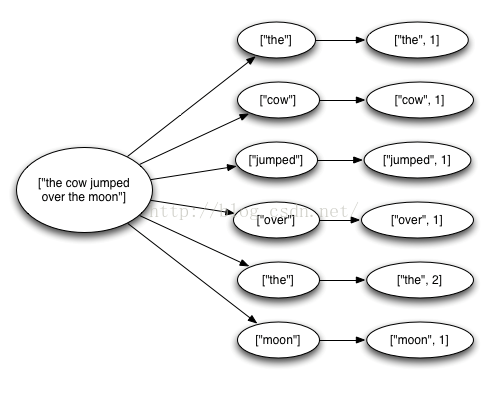
当Tuple树被耗尽并且树中的每个消息都处理完成,Storm才认为一个由Spout输入的Tuple才被完全处理。如果在指定时间里消息树没有被完全处理,那么就认为处理失败。这个超时能够使用Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS这个基本配置来配置,默认时间是30秒。
如果消息被完全处理或处理失败会发生什么?
要理解这个问题,需要先看一下一个Spout输入的Tuple的生命周期,一下是Spout实现的接口(仅供参考,详细信息请看这里)。
publicinterfaceISpoutextendsSerializable{
voidopen(Mapconf,TopologyContextcontext,SpoutOutputCollectorcollector); voidclose(); voidnextTuple(); voidack(ObjectmsgId); voidfail(ObjectmsgId);}
首先,通过调用相关Spout上的nextTuple方法从Spout中请求一个Tuple。Spout使用open方法中提供的SpoutOutputCollector对象把一个Tuple发送给相关的输出流。在发送Tuple时,Spout会提供一个用于后续标识这个Tuple的“消息id”。例如,KestrelSpout从Kestrel队列中读取消息,并使用由Kestrel为消息提供id作为消息的id。例如:
_collector.emit(newValues("field1","field2",3),msgId);
接下来,Tuple会被发送给运算器Bolt,Storm会跟踪它所创建的消息树的轨迹。如果Storm断定一个Tuple被完全处理了,那么它调用消息id所对应的原始的Spout上的ack方法。同样,如果Tuple超时。Storm会调用相关Spout上的fail方法。需要注意的是一个Tuple会通过它所创建的完全一样的Spout任务来确认成功或失败。因此如果一个Spout要跨集群执行多个任务,那么它的Tuple不会通过不同于创建它的任务来确认成功或失败。
通过上文提到的KestrelSpout再来看一下Spout都需要些什么工作来保证消息的处理。在KestrelSpout从Kestrel队列中获取消息时,它会打开消息。这意味着相关消息不会实际的离开队列,而只是被设置为“pending”状态,等待消息处理完成的确认动作。在“pending”状态的消息不会被发送给其他的队列消费者。此外,如果一个客户端断开了所有与它连接的处于“pending”状态消息,那么这些消息会被重新放回队列中。一个消息被打开时,Kestrel提供了了带有消息数据和唯一消息id的客户端。在把相关的数据元组发送给SpoutOutputCollector对象时,KestrelSpout会使用这个唯一的id作为消息id。稍后,当KestrelSpout上的ack或fail方法被调用时,KestrelSpout会给Kestrel发送一个带有消息id的确认或失败消息,这决定了对应的消息从队列中移除或放回队列中。
Storm的可靠性API是什么?
要让用户从Storm的可靠性能力中获益,必须做两件事情。首先,无论什么时候创建Tuple树中的一个新的节点都要告诉Storm;其次,处理完一个独立的的Tuple时也要告诉Storm。做完这两件事,Storm就能够检查Tuple树被完全处理完成的时机,并能够确认相关的Spout的Tuple的处理是否成功。Storm的API提供了简单的方法来做这两件事情。
在Tuple树中指定一个叫做锚点的连接节点。锚点是在发送新的Tuple时,同时设定的。例如,下例的Bolt把一整句话的Tuple分割到每个单词的Tuple中:
publicclassSplitSentenceextendsBaseRichBolt{
OutputCollector_collector; publicvoidprepare(Mapconf,TopologyContextcontext,OutputCollectorcollector){ _collector=collector; } publicvoidexecute(Tupletuple){ Stringsentence=tuple.getString(0); for(Stringword:sentence.split(" ")){ _collector.emit(tuple,newValues(word)); } _collector.ack(tuple); } publicvoiddeclareOutputFields(OutputFieldsDeclarerdeclarer){ declarer.declare(newFields("word")); } }每个单词的Tuple是通过指定emit方法的第一个输入参数(Tuple)来锚定的,在对应单词的Tuple被锚定之后,如果对应单词的处理失败,那么在树的根部的Spout的Tuple会被再次发送。
看一下如下的发送单词的Tuple方法会发生什么:
_collector.emit(newValues(word));
这种方式发送的单词的Tuple不会被锚定。这样如果下游的处理失败,那么根部的Tuple将不会被重新发送。根据Topology中需要的保障机制,有时可以适当的发送非锚定的Tuple。
一个输出的Tuple能够跟多个输入的Tuple关联,这样做有益于数据流的连接和聚合。一个多关联的Tuple如果处理失败,将会导致从对应的Spout中重新发送多个Tuple。通过指定Tuple的列表,而不只是一个单独的Tuple来设定多个关联。例如:
List<Tuple>anchors=newArrayList<Tuple>();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors,newValues(1,2,3));
多重关联会把输出的Tuple添加到多个Tuple树中。注意,这样的多重关联有可能打破树形结构并创建如下图所示的Tuple的有向无环图(DAG):
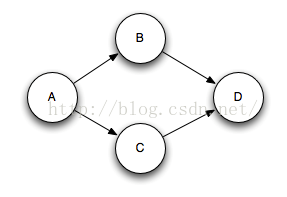
对于有向无环图(DAG),Storm能够像树形结构一样的工作(之前的版本只对树形结构有效,所以命名为“Tuple tree”)。
使用OutputCollector上的fail方法会让相关Tuple树的根节点立即失败。例如,应用程序可以选择捕获来自数据库客户端的异常,并确认失败的输入Tuple。通过明确让Tuple失败,可以让Spout的Tuple比等待超时更快的重新发送。
处理的每个Tuple都必须要确认成功或失败。Storm使用内存来跟踪每个Tuple,因此如果每个Tuple都没有确认成功或失败,那么最终会导致内存溢出。
许多Bolt都会遵循一个共同的读取一个输入Tuple的模式,并基于这种模式来发送Tuple,然后在execute方法执行之后来确认对应的Tuple。这些Bolt会分成过滤策略和简单的功能。Storm有一个叫做BasicBolt接口,它封装了这种模式。例如SplitSentence示例可以像下面这样编写:
publicclassSplitSentenceextendsBaseBasicBolt{
publicvoidexecute(Tupletuple,BasicOutputCollectorcollector){ Stringsentence=tuple.getString(0); for(Stringword:sentence.split(" ")){ collector.emit(newValues(word)); } } publicvoiddeclareOutputFields(OutputFieldsDeclarerdeclarer){ declarer.declare(newFields("word")); } }这种实现比之前的实现要简单,并且在语义上是相同的。发送给BasicOutputCollector的Tuple会自动的关联到对应的输入Tuple上,并且在execute方法执行完成时,会自动的应答其对应的Tuple。
有些时候,聚合或连接Bolt时,Tuple的应答需要延迟到基于一组Tuple完成计算之后。聚合和连接通常会跟它们对应的输出Tuple多重关联。这些情况超出了IBasicBolt的简单模式。
如何让应用程序在重播Tuple的情况下还能够正常的工作?
一如既往,在软件设计中,这个回答是“视情况而定”。Storm0.7.0引入了“事务性的拓扑”功能,它与大多数计算中的一次性消息处理的语义完全兼容。详细信息请“这里”。
Storm如何高效的实现可靠性?
Storm的拓扑有一组叫做”acker”的任务,它们会跟踪每个输入源所产生的元组的有向无环图(DAG)。当一个”acker”看到一个有向无环图(DAG)执行完成,它就会给创建这个输入源的任务发送一个消息,相关的输入源就会应答这个消息。使用Config.TOPOLOGY_ACKER_EXECUTORS配置来设置拓扑中的acker执行器的数量。默认的TOPOLOGY_ACKER_EXECUTORS设置会跟拓扑中配置的工作者的数量相同---对于处理大量消息的拓扑,这个设置中的数量要增加。
理解Storm可靠性实现的最好的方法是看元组的生命周期和元组的有向无环图(DAG),在拓扑中创建元组时,不管是在发送器(Spout)还是运算器(Bolt)中,相关的元组都会获得一个随机的64位id。acker使用这些id来跟踪每个输入元组所产生的元素有向无环图(DAG)。
对于元组树中的每个元组都会知道所有的输入源元组的id。当把一个新的元组发射到一个运算器(Bolt)中时,来自相关锚点的输入源组的id也会被复制到新的元组中。在元组被应答时,它会把一个消息发送给与元组树变更相适应的acker任务,实际上就是告诉acker:“在这个输入元组树内我已经被执行完成,现在树中跟我链接的是新的元组。
例如:如果基于元组C创建了元组D和E,那么应答C时,元组树会做如下图所示的改变:

因为从树中删除C的同时添加了D和E, 这个树不能过早的结束。
关于Storm如何跟踪元组树有很多细节。就像前面已经提到的,在一个拓扑中可以有任意数量的acker任务。这回导致一个问题:在相关拓扑中响应一个元组时,如何知道是哪个acker任务发送的信息?
Storm使用传统hash算法把输入元组的id映射到一个acker任务上。因为每个元组在它所存在的树中都会携带输入元组的id,这样它们就会知道要与哪个acker任务进行通信。
Storm的另一个细节是acker任务所跟踪的输入任务是如何负责它们正在跟踪每个输入元组的。在输入任务发送一个新的元组时,它简单的把一个消息发送给适合的acker,并告诉它对输入元组负有责任的任务id。然后,当一个acker看到一个树被执行完成,它就会知道发送结束消息的任务。
Acker任务不会明确的跟踪元组树。对于大型带有成千上万个节点的元组树,跟踪所有的元组树会压垮acker所使用的内存,因此acker使用一个不同的策略,每个输入元组只需要一个固定数量的空间(大约20个字节)。Storm如何工作的关键以及主要的突破点之一是跟踪算法。
一个Acker任务会保存一个从输入元组id到一个值对的映射。第一个值是创建这个输入元组的任务id,随后它会被用户发送结束消息。第二个值是一个叫做ack val的64位数字。无论元组树的大小,都会使用这个ack val值来代表了整个元组树的状态,它只是对元组树中的已经创建的所有的and/or类型的元组id进行简单的与或运算。
当一个acker任务看到ack val的值变为0时,它就会知道这个元组树结束了。因为元组id是一个随机的64位数字,所以ack val的改变变成0的机率非常小。如果用数学的方法来计算一下,那么每秒中100000次响应的话,50,000,000年才会发生一个错误。即使发生了,也只会导致拓扑中发生错误的那个元组的数据丢失。
现在我们理解了可靠性的算法,接下来看一下所有的可能失败的情况,并看一下每种场景下,Storm如何避免数据丢失。
A. 因为相关的任务死掉而导致一个元组无法响应:这种情况下在对应树的根节点的输入元组会因为失败元组而超时并被重新发送。
B. 响应任务死掉了:这种情况下这个acker所跟踪的所有输入元组会因超时而被重新发送;
C. 输入源任务死掉了:这种情况下,这个输入源会负责重新发送消息。例如,像Kestrel和RabbitMQ这样的队列会在客户端断开连接时,把所有的等待状态的消息返回到相应的队列中。
如上所诉,Storm的可靠性机制是完全分布式、可扩展和容错的。
可靠性调优
Acker任务是轻量级的,所以在拓扑内不需要太多。通过Storm的UI可以跟踪这些Acker的性能情况。如果Acker任务满足不了需要,就需要添加更多的Acker任务。
如果可靠性不是很重要,也就是说在失败的情况下,不需要关注那些丢失的元组,那么通过不跟踪对应输入元组的元组树就可以改善性能。因为通常元组树中的每个元组都会一个应答消息,所以不跟踪元组树就会让传送消息的数量减半。另外,下下游的元组中几乎不需要保留id,这样就会减少带宽的使用。
有三种方法删除可靠性:
1. 把Config.TOPOLOGY_ACKERS设置为0,这种情况下Storm会在输入源发送一个元组后,立即调用对应元组上的ack方法。元组树不会被跟踪;
2. 删除可靠性相关的消息。通过SpoutOutputCollector.emit方法中的发送消息的id来关闭对个别的输入元组的跟踪;
3. 如果不介意在拓扑的下游有一个特殊的无法处理的元组的子集,就可以把它们作为一个非锚定的元组来发送,因为它们不跟任何输入元组相关联,所以如果它们不应答,也不会导致任何输入元组的失败。














 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









