






Storm保证spout发出来的每条消息都会被完全的处理。这篇文章描述了Storm是如何实现这一保证机制的以及作为一个storm的使用者我们如何从storm的这种可靠性中获益。
消息被"完整处理"的含义
由spout发出来的一个tuple(元组)会触发下游更多的tuple的生成。让我们看你这个流单词计数的topology:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new KestrelSpout("kestrel.backtype.com",
22133,
"sentence_queue",
new StringScheme()));
builder.setBolt("split", new SplitSentence(), 10)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 20)
.fieldsGrouping("split", new Fields("word"));

当这棵tuple树被完全使用并且这棵树中的所有的消息都被完全的处理过了,storm就认为spout发出的tuple(这个tuple是树中的根节点)被"完全处理"了。而当这棵树中的所有消息在特定的时间内没有被完全的处理,storm就认为该tuple就是未被完全处理的。其中,处理的时限可以通过Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS 进行设置,默认是30秒。
消息被完全处理或者未被完全处理分别会发生什么?
为了理解这个问题,我们首先来看看spout发出的tuple的生命周期。这里给出了spouts需要实现的接口作为参考:
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}_collector.emit(new Values("field1", "field2", 3) , msgId);我们用KestrelSpout来看看Spout在消息处理保证机制中做了些什么。
当KestrelSpout从Kestrel队列中获取一条消息时,它会"opens"(打开)这个消息。这意味着该消息还并没有从队列中提取出来,而是处于一种"pending"(待处理)的状态,等待确定这条消息被确实的处理完成。处于"pending"状态的消息不会被发送到该队列的其他消费者中。另外,如果客户端断开了连接,所有"pending"状态下的消息都将回归队列中的正常状态。当一个消息被"opend"(打开),Kestrel将会提供该消息的数据以及该消息的唯一的id给相应的客户端。KestrelSpout就使用这个id作为tuple的"message id"。
当KestrelSpout中的ack或者fail被调用时,KestrelSpout将会发送ack或者fail消息并附上message id给Kestrel,以便Kestrel将该消息从队列中T出或者让该消息回归正常状态等待下次"open"。
Storm的可靠性API
作为一个用户,我们使用storm的可靠性能力时需要做两件事。1.当我们在消息树中建立了新的连接的时候,我们需要告诉Storm。2.当我们处理完了单个的tuple(这里tuple是整个过程中产生的tuple不单单只根节点的那个tuple)也需要告诉Storm。通过以上两点,Storm就可以检测tuple树是否处理完成,并调用相应的ack或者fail。Storm API提供了简洁的方案来完成上述任务。
确定tuple树中的一个连接叫做"anchoring"(锚定)。Anchoring将在发送一个新tuple的时候就完成。我们看下面这个bolt例子。这个bolt将一个包含一个句子的tuple分割成多个单词tuple:
public class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}如果我们以_collector.emit(new Values(word))的方式发送tuple,显然这种方式发送的tuple是没有被锚定的。如果下游处理失败,也不会重发。我们可以根据具体的容错需要来选择相应的方式。
一个输出的tuple可以被多个输入tuple锚定。当需要进行流连接(join)或者汇聚(aggregation)时,这个功能非常有用。一个多锚定的(multi-anchored)tuple处理失败将可能会引起spouts的多个tuple的重发。通过以下方式可以完成多锚定(multi-anchored):
List<Tuple> anchors = new ArrayList<Tuple>();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors, new Values(1, 2, 3));
Storm对于DAG或者树都是支持的,但只有树结构支持pre-release(不太懂)。
锚定使得我们能够使tuple树具体化。接下来我们将学习如何来确定单个tuple的处理是否完成。这是通过OutputCollector中的ack以及fail来实现的。例如,上面的SplitSentence例子,它在发送完所有的单词tuples后进行了ack。
我们可以通过OutputCollector中的fail方法来迅速通知位于根节点的spout tuple。这样,我们就无需等到超出时限才发送fail消息。
每个tuple都必须进行ack或者fail。Storm使用内存来跟踪每个tuple,所以如果我们不进行不对每个tuple进行ack或者fail,负责跟踪tuple的任务将一直运行,直到内存用光。
大多数bolts都以种通用的模式来读取输入的tuple,发送tuple,以及在execute方法的结尾处来ack这个tuple。这种的bolts被归到了过滤器或者说简单函数这一类。Storm中有一个BasicBolt接口包含了这一模式。将SplitSentence改成BasicBolt的形式:
public class SplitSentence extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}相反,bolts进行aggregations(汇聚)或者joins(连接)时,将会推迟ack直到在批量的tuples的基础上计算出了结果之后。Aggregations以及joins将会对他们的output tuples进行多锚定。这些将会在IBasicBolt中看到。
当出现tuples重发时,如何使应用运行正确(即避免重复计算)
这得依情况而定。。。Storm 0.7.0介绍了"transactional topologies"特性,可以保证在大多数计算时只发一次( exactly-once messaging)。但是,现在被弃用了,改用一个叫"Trident"的框架。以后介绍。
Storm如何有效的实现可靠性
在Storm topology中有一系列特殊的"acker"它们会为每个spout tuple追踪DAG中的tuples。当一个acker检测到一个DAG完成了,它将会发送一条消息给生成了该spout tuple的task来进行确认。(这里,大家肯定会有疑惑,每次tuple发送时都进行了ack,为什么还有acker。answer:每次的ack是告知acker本次的处理完了。而acker要进行汇总告诉根节点task所有的tuple都处理完成了)。我们可以通过Config.TOPOLOGY_ACKER_EXECUTORS来设置acker的个数。Storm默认acker的个数与worker的个数一样。--当我们需要处理大量的消息时,我们可能就需要提高这个acker的量了。
理解Storm的可靠性的最好方式是研究tuples以及tuple DAG的生命周期。当tuple在topology中生成时,无论是spout还是bolt生成的tuple,都将被赋予一个64bit的随机id。这些id就被ackers用来跟踪这个tuple DAG中的每个spout tuple。
每个tuple都知道所有与其位于同个DAG的spout tuples的id。当我们发送一个新的tuple时,spout tuple的id将会通过锚定这个方式拷贝到新的tuple中。当该tuple进行ack,它会发送一条消息给相应的acker task告诉其tupel DAG的变化情况。白话一点:该tuple说:我已经完成了该id号的spout tuple来的计算,然后这些是锚定了我的新的tuple。
举个例子,如果tuples D与E是在C的基础上生成的,那么下面就是当C ack以后,tuple DAG的变化(打红叉说明就是ack了):
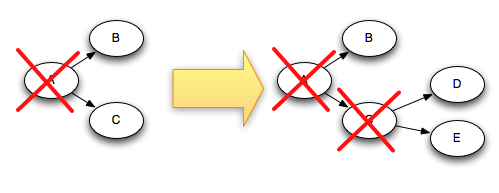
由于C被ack时,D与E又被加入到了DAG中,故这个DAG还没有被完全处理。
这里有些细节需要说明,上面已经提过,你可以自己设置任意数量的acker tasks。这就会导致出现问题:当一个tuple被ack了,它如何知道它该向哪个acker task发消息?
Storm使用取模hash的方式将spout tuple id映射给相应的acker task。前面说过所有与该spout tuple在同一个DAG的tuple都通过anchor的方式获取了spout tuple的id,所以,它们就可以更加spout tuple id向相应的acker task发送消息。
另一个细节是acker task如何知道向哪个spout task发送消息?
当spout task发出一个新的tuple时,它会向负责这个spout tuple的acker task自己的spout task id。因此acker task可以根据spout task id来确定当tuple完成后向相应的spout task发消息。
Acker tasks并不是显式的追踪tuple DAG(这会使得单单运行acker task就耗光内存),而是一种更巧妙的方式,这种方式只需要acker task为其追踪的每个spout tuple花费大约20bytes。这种追踪算法是Storm的关键,也是storm的一个主要突破。
acker task存储了一个spout tuple id到一个值对(value1,value2)的映射 。value1是spout task id用来确定acker将向哪个spout task发消息。value2是一个64bit的数字叫做"ack val"(ack变量)。ack变量代表了整个DAG的状态,ack变量只是简单的与DAG中生存以及ack时传来的tuple id进行异或。
当acker task发现ack变量的值为0时,那就说明tupleDAG已经完全处理了。因为tuple id是随机的64bit数,所以如果因为不同的数异或产生0的概率是特别小的。经数学计算,每秒10k次的ack,也需要50000000年才会出现一次上述错误情况。而且即使出现了上述错误,也仅仅是造成了一次数据的丢失,如果碰巧这次处理是失败的。
现在我们来看看,在各种失败的情况下,storm如何避免数据丢失:
·由于task died,tuple未进行ack:这种情况下,处理将超时,spout tuple将重发
·Acker task dies:这种情况下所有该Acker task跟踪下的spout tuple都将因为超时而重发
·Spout task dies:这种情况下Spout的源头将进行消息重发,例如:当与消费客户端失去连接后,Kestrel和RabbitMQ将会把所有的"待处理"消息回复正常。
你可以看到,Storm的可靠性机制是完全分布式、可扩展以及容错的。
调整storm的可靠性
Acker tasks是轻量级的,所以我们在topology并不需要部署太多。我们可以通过Storm UI来监控他的性能。如果流量不太对,我们可能就需要加大acker task的量了。
如果可靠性对你来说不太重要,我们就可以不追踪tuple了。这将使消息的传输量下降一半。另外,下游的tuple也不需要拷贝spout tuple id,这也将减少带宽使用。
我们有三种方式来移除可靠性。第一种是设置Config.TOPOLOGY_ACKERS为0 ,这种情况下,Storm将会在spout发送了tuple后就调用spout的ack方法。因此DAG就不会被追踪。
第二种方式是将消息的message id置为null。通过在SpoutOutputcollector.emit参数中设置message id为null,就可以关闭对当前spout tuple的追踪。
第三种方式就是之前提到过的,我们可以不对下游的tuple进行锚定(anchor)。















 1660
1660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









