







 本文介绍了Hive作为Hadoop数据仓库工具的作用,提供类SQL查询能力,并分享了作者的使用经验和具体案例,强调了Hive在大数据分析中的价值,特别是对无开发经验的数据分析人员。文章还提出了Hive学习路线图,包括安装、使用攻略和实践测试。
本文介绍了Hive作为Hadoop数据仓库工具的作用,提供类SQL查询能力,并分享了作者的使用经验和具体案例,强调了Hive在大数据分析中的价值,特别是对无开发经验的数据分析人员。文章还提出了Hive学习路线图,包括安装、使用攻略和实践测试。
前言
Hive是Hadoop家族中一款数据仓库产品,Hive最大的特点就是提供了类SQL的语法,封装了底层的MapReduce过程,让有SQL基础的业务人员,也可以直接利用Hadoop进行数据的操作。就是这一点,解决了原始数据分析人员对于大数据分析的瓶颈。
目录
- Hive介绍
- Hive学习路线图
- 我的使用经历
- Hive的使用案例
1.Hive介绍
Hive起源于Facebook,它使得针对Hadoop进行SQL查询成为可能,从而非程序员也可以方便地使用。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务运行。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
详细地Hive安装和使用介绍,参考文章:Hive安装及使用攻略
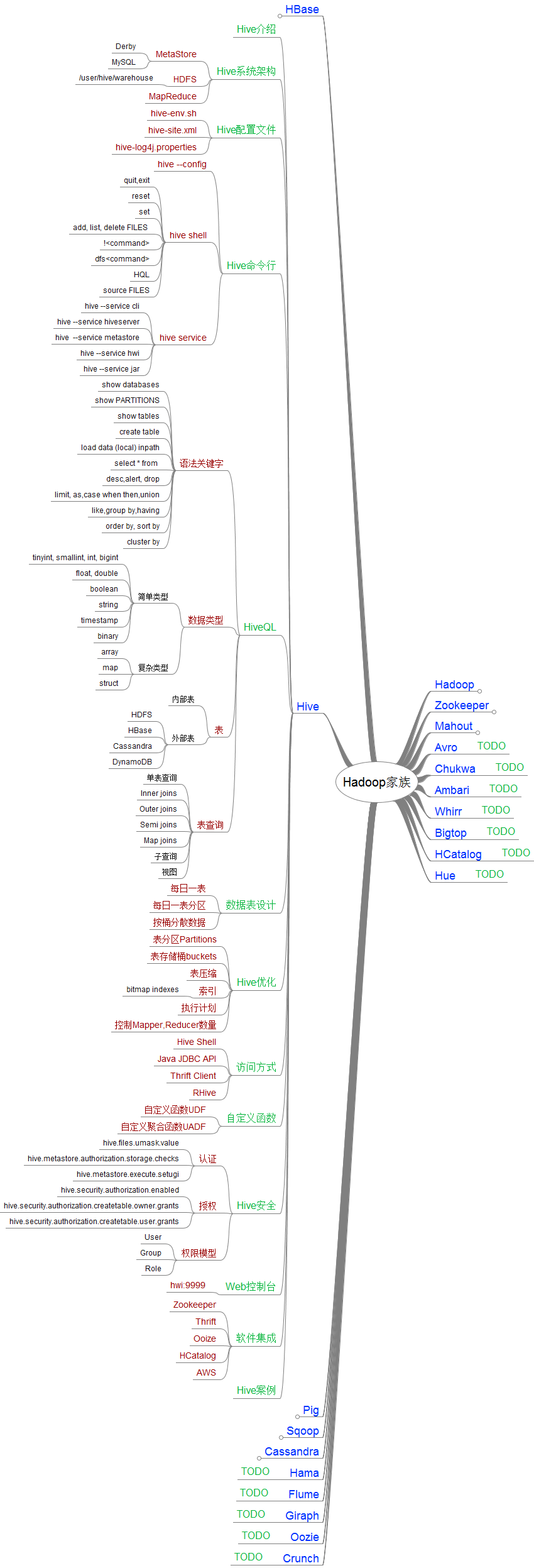
2.Hive学习路线图
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1604
1604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









