







 本文介绍了使用Mahout 0.8在Hadoop分布式环境中开发协同过滤算法ItemCF的详细步骤,包括数据准备、HDFS操作工具HdfsDAO、核心算法实现ItemCFHadoop以及程序运行和推荐结果的解读。
本文介绍了使用Mahout 0.8在Hadoop分布式环境中开发协同过滤算法ItemCF的详细步骤,包括数据准备、HDFS操作工具HdfsDAO、核心算法实现ItemCFHadoop以及程序运行和推荐结果的解读。
前言
Mahout是Hadoop家族中一员,从血缘就继承了Hadoop程序的特点,支持HDFS访问和MapReduce分布式计算法。随着Mahout的发展,从0.7版本开始,Mahout做了重大的升级。移除了部分算法的单机内存计算,只支持基于Hadoop的MapReduce平行计算。
目录
- mahout开发环境介绍
- Mahout基于Hadoop的分布式计算环境介绍
- 用Mahout实现协同过滤ItemCF
- 模块项目上传github
1.Mahout开发环境介绍
在 用Maven构建Mahout项目 文章中,我们已经配置好了基于Maven的Mahout的开发环境,我们将继续完成Mahout的分步式的程序开发。
本文的mahout版本为0.8。
开发环境:
Win7 64bit
Java 1.6.0_45
Maven 3
Eclipse Juno Service Release 2
Mahout 0.8
Hadoop 1.1.2
找到pom.xml,修改mahout版本为0.8
<mahout.version>0.8</mahout.version>然后,下载依赖库。
~ mvn clean install由于 org.conan.mymahout.cluster06.Kmeans.java 类代码,是基于mahout-0.6的,所以会报错。我们可以先注释这个文件。
2.Mahout基于Hadoop的分布式环境介绍
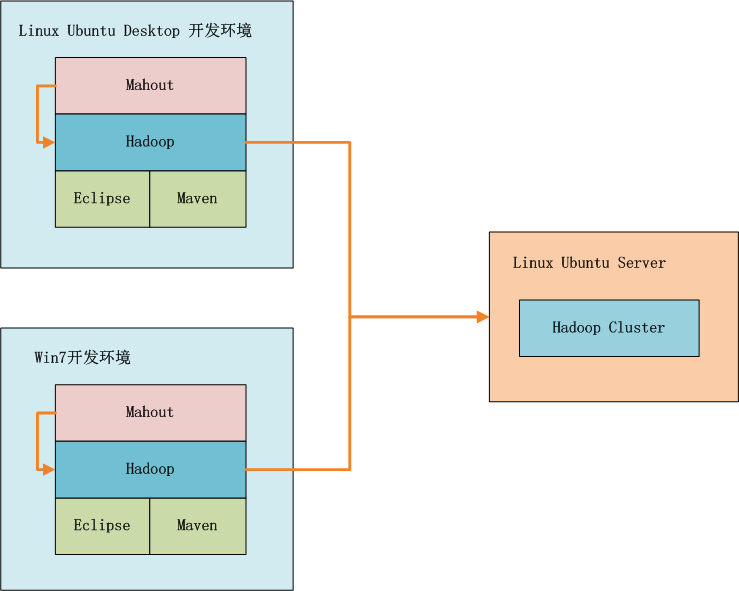
如上图所示,我们可以选择在win7中开发,也可以在linux中开发,开发过程我们可以在本地环境进行调试,标配的工具都是Maven和Eclipse。
Mahout在运行过程中,会把MapReduce的算法程序包,自动发布的Hadoop的集群环境中,这种开发和运行模式,就和真正的生产环境差不多了。
3.用Mahout实现协同过滤ItemCF
实现步骤:
- 准备数据文件: item.csv
- Java程序:HdfsDAO.java
- Java程序:ItemCFHadoop.java
- 运行程序
- 推荐结果解读
1). 准备数据文件: item.csv
上传测试数据到HDFS,单机内存实验请参考文章:用Maven构建Mahout项目
~ hadoop fs -mkdir /user/hdfs/userCF
~ hadoop fs -copyFromLocal /home/conan/datafiles/item.csv /user/hdfs/userCF
~ hadoop fs -cat /user/hdfs/userCF/item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.02). Java程序:HdfsDAO.java
HdfsDAO.java,是一个HDFS操作的工具,用API实现Hadoop的各种HDFS命令,请参考文章:Hadoop编程调用HDFS
我们这里会用到HdfsDAO.java类中的一些方法:
HdfsDAO hdfs = new HdfsDAO(HDFS, conf);
hdfs.rmr(inPath);
hdfs.mkdirs(inPath);
hdfs.copyFile(localFile, inPath);
hdfs.ls(inPath);
hdfs.cat(inFile);3). Java程序:ItemCFHadoop.java
用Mahout实现分步式算法,我们看到Mahout in Action中的解释。
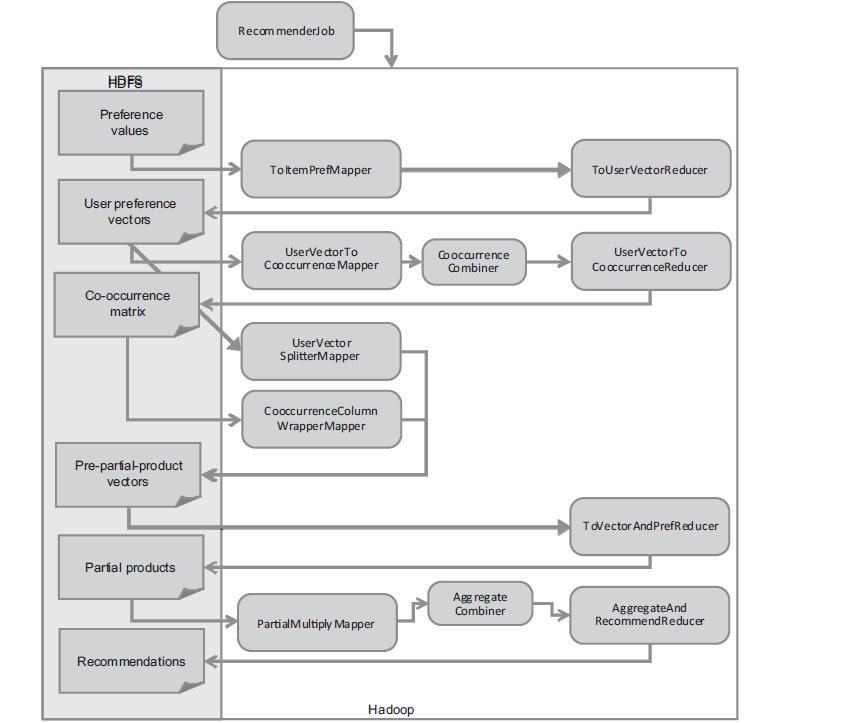
实现程序:
package org.conan.mymahout.recommendation;
import org.apache.hadoop.mapred.JobConf;
import org.apache.mahout.cf.taste.hadoop.item.RecommenderJob;
import org.conan.mymahout.hdfs.HdfsDAO;
public class ItemCFHadoop {
private static final String HDFS = "hdfs://192.168.1.210:9000";
public static void main(String[] args) throws Exception {
String localFile = "datafile/item.csv";
String inPath = HDFS + "/user/hdfs/userCF";
String inFile = inPath + "/item.csv";
String outPath = HDFS + "/user/hdfs/userCF/result/";
String outFile = outPath + "/part-r-00000";
String tmpPath = HDFS + "/tmp/" + System.currentTimeMillis();
JobConf conf = config();
HdfsDAO hdfs = new HdfsDAO(HDFS, conf);
hdfs.rmr(inPath);
hdfs.mkdirs(inPath);
hdfs.copyFile(localFile, inPath);
hdfs.ls(inPath);
hdfs.cat(inFile);
StringBuilder sb = new StringBuilder();
sb.append("--input ").append(inPath);
sb.append(" --output ").append(outPath);
sb.append(" --booleanData true");
sb.append(" --similarityClassname org.apache.mahout.math.hadoop.similarity.cooccurrence.measures.EuclideanDistanceSimilarity");
sb.append(" --tempDir ").append(tmpPath);
args = sb.toString().split(" ");
RecommenderJob job = new RecommenderJob();
job.setConf(conf);
job.run(args);
hdfs.cat(outFile);
}
public static JobConf config() {
JobConf conf = new JobConf(ItemCFHadoop.class);
conf.setJobName("ItemCFHadoop");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
return conf;
}
}RecommenderJob.java,实际上就是封装了,上面整个图的分步式并行算法的执行过程!如果没有这层封装,我们需要自己去实现图中8个步骤MapReduce算法。
关于上面算法的深度剖析,请参考文章:R实现MapReduce的协同过滤算法
4). 运行程序
控制台输出:
Delete: hdfs://192.168.1.210:9000/user/hdfs/userCF
Create: hdfs://192.168.1.210:9000/user/hdfs/userCF
copy from: datafile/item.csv to hdfs://192.168.1.210:9000/user/hdfs/userCF
ls: hdfs://192.168.1.210:9000/user/hdfs/userCF
==========================================================
name: hdfs://192.168.1.210:9000/user/hdfs/userCF/item.csv, folder: false, size: 229
==========================================================
cat: hdfs://192.168.1.210:9000/user/hdfs/userCF/item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
2013-10-14 10:26:35 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2013-10-14 10:26:35 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:35 org.apache.hadoop.io.compress.snappy.LoadSnappy
警告: Snappy native library not loaded
2013-10-14 10:26:36 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0001
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:36 org.apache.hadoop.io.compress.CodecPool getCompressor
信息: Got brand-new compressor
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000000_0' done.
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:36 org.apache.hadoop.io.compress.CodecPool getDecompressor
信息: Got brand-new decompressor
2013-10-14 10:26:36 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 42 bytes
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0001_r_000000_0 is allowed to commit now
2013-10-14 10:26:36 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/preparePreferenceMatrix/itemIDIndex
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_r_000000_0' done.
2013-10-14 10:26:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0001
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=187
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=3287330
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=916
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=3443292
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=645
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=229
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=46
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map input records=21
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=14
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=84
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=376569856
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=116
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Combine input records=21
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Combine output records=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map output records=21
2013-10-14 10:26:37 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0002
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0002_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0002_m_000000_0' done.
2013-10-14 10:26:37 org 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









