







2017年05月02日spark发布了稳定版2.1.1,据说是2.0+版本的spark替代了之前的JVM然后自己实现了一套JVM,说是更加节省内存了,于是满心欢喜的下载了
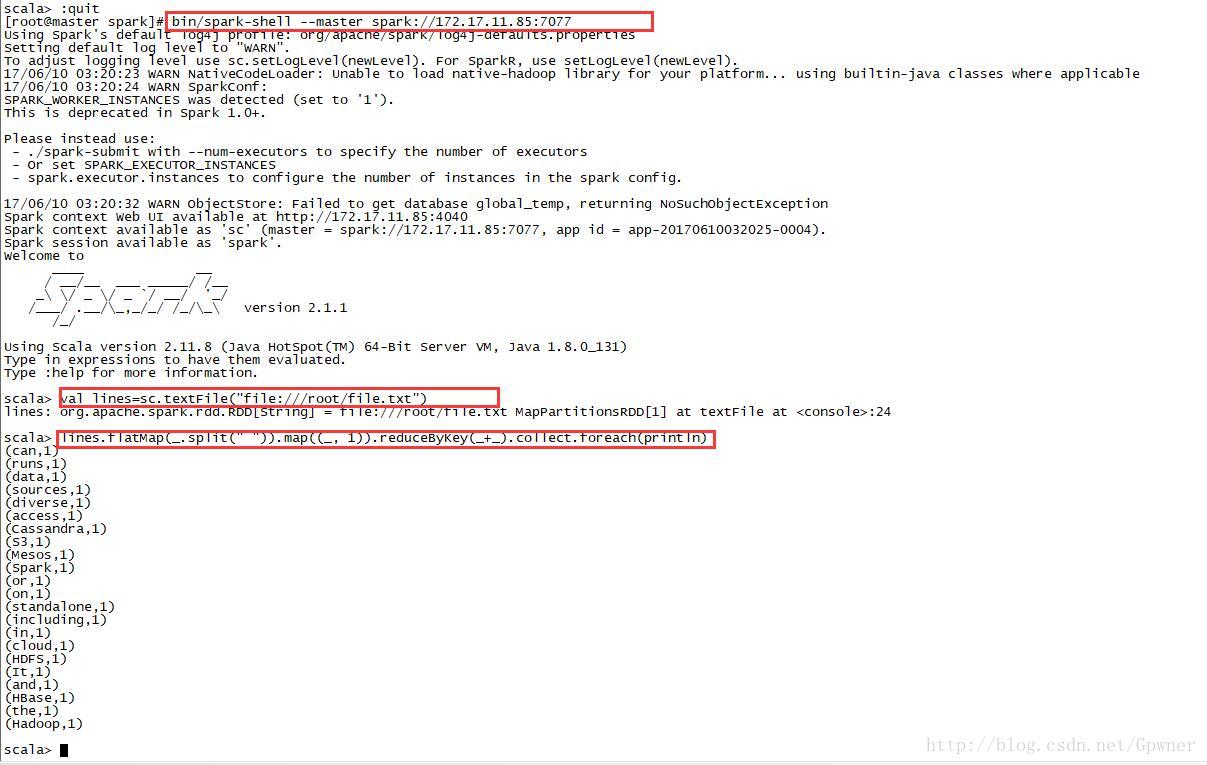
安装完成之后跑了Wordcount例子,代码是:
val lines=sc.textFile("file:///root/file.txt")
lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect.foreach(println)却得到如下的异常:
[Stage 2:=============================> (1 + 1) / 2]17/06/10 03:36:34 WARN TaskSetManager: Lost task 0.0 in stage 2.0 (TID 4, 172.17.11.86, executor 0): java.io.FileNotFoundException: File file:/root/file.txt does not exist
at org.apache.hadoop.fs.RawLocalFileSystem.deprecatedGetFileStatus(RawLocalFileSystem.java:611)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileLinkStatusInternal(RawLocalFileSystem.java:824)
at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:601)
at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:421)
at org.apache.hadoop.fs.ChecksumFileSystem$ChecksumFSInputChecker.<init>(ChecksumFileSystem.java:142)
at org.apache.hadoop.fs.ChecksumFileSystem.open(ChecksumFileSystem.java:346)
at org.apache.hadoop.fs.FileSystem.open(FileSystem.java:769)
at org.apache.hadoop.mapred.LineRecordReader.<init>(LineRecordReader.java:109)
at org.apache.hadoop.mapred.TextInputFormat.getRecordReader(TextInputFormat.java:67)
at org.apache.spark.rdd.HadoopRDD$$anon$1.liftedTree1$1(HadoopRDD.scala:252)
at org.apache.spark.rdd.HadoopRDD$$anon$1.<init>(HadoopRDD.scala:251)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:211)
at org.apache.spark.rdd.HadoopRDD.compute(HadoopRDD.scala:102)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:323)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:287)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:96)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:53)
at org.apache.spark.scheduler.Task.run(Task.scala:99)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)最终经过排查发现standalone模式下需要集群中所有机器下相同目录下有相同的要读取的文件(我这里想要读取的文件是/root/file.txt),当我把相同的文件分发到集群中其他机器上相同目录下的时候再次跑wordcount的时候问题得到解决














 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









