







1、背景
在复杂的分布式 架构 的应用程序有很多的依赖,都会不可避免地在某些时候失败。高并发的依赖失败时如果没有隔离措施,当前应用服务就有被拖垮的风险。服务雪崩效应是一种因 服务提供者 的不可用导致 服务调用者 的不可用,并将不可用 逐渐放大 的过程.如果所示:
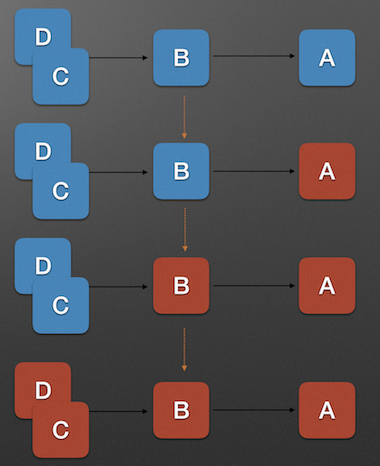
上图中, A为服务提供者, B为A的服务调用者, C和D是B的服务调用者. 当A的不可用,引起B的不可用,并将不可用逐渐放大C和D时, 服务雪崩就形成了.
例如:一个依赖30个SOA服务的系统,每个服务99.99%可用。
99.99%的30次方 ≈ 99.7%
0.3% 意味着一亿次请求 会有 3,000,00次失败
换算成时间大约每月有2个小时服务不稳定.
随着服务依赖数量的变多,服务不稳定的概率会成指数性提高.
解决问题方案:对依赖做隔离,Hystrix就是处理依赖隔离的框架,同时也是可以帮我们做依赖服务的治理和监控.
2、原理
2.1、资源隔离:Bulkheads(舱壁隔离模式)
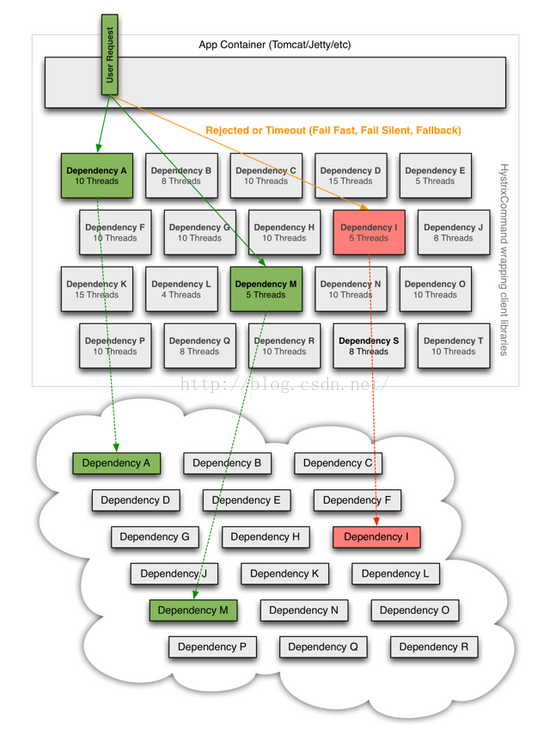
Hystrix通过将每个依赖服务分配独立的线程池进行资源隔离, 从而避免服务雪崩。假设你依赖很多个服务,你不希望对其中一个服务的调用消耗过多的线程以致于其他服务都没线程调用了。默认这个线程池的大小是10,即并发执行的命令最多只能有是个了,超过这个数量的调用就得排队,如果队伍太长了(默认超过5),Hystrix就立刻走 fallback 或者抛异常。
如下图所示, 当商品评论服务不可用时, 即使商品服务独立分配的20个线程全部处于同步等待状态,也不会影响其他依赖服务的调用.

根据你的具体需要,你可能会想要调整某个Command的线程池大小,例如你对某个依赖的调用平均响应时间为200ms,而峰值的QPS是200,那么这个并发至少就是 0.2 x 200 = 40 (Little's Law),考虑到一定的宽松度,这个线程池的大小设置为60可能比较合适.
2.2、熔断器模式
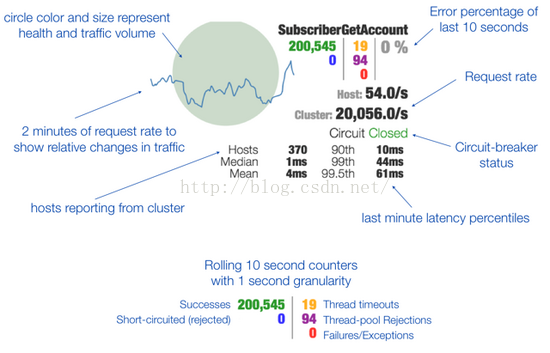
提供熔断器组件,可以自动运行或手动调用,停止当前依赖一段时间(10秒),熔断器默认 错误 率阈值为50%,超过将自动运行。
2.2.1、熔断器的原理
熔断器可以使用状态机来实现,内部模拟以下几种状态。

(1)闭合(closed)状态: 对应用程序的请求能够直接引起方法的调用。代理类维护了最近调用失败的次数,如果某次调用失败,则使失败次数加1。如果最近失败次数超过了在给定时间内允许失败的阈值,则代理类切换到断开(Open)状态。此时代理开启了一个超时时钟,当该时钟超过了该时间,则切换到半断开(Half-Open)状态。该超时时间的设定是给了系统一次机会来修正导致调用失败的错误。
(2)断开(Open)状态:在该状态下,对应用程序的请求会立即返回错误响应。
(3)半断开(Half-Open)状态:允许对应用程序的一定数量的请求可以去调用服务。如果这些请求对服务的调用成功,那么可以认为之前导致调用失败的错误已经修正,此时熔断器切换到闭合状态(并且将错误计数器重置);如果这一定数量的请求有调用失败的情况,则认为导致之前调用失败的问题仍然存在,熔断器切回到断开方式,然后开始重置计时器来给系统一定的时间来修正错误。半断开状态能够有效防止正在恢复中的服务被突然而来的大量请求再次拖垮。
各个状态之间的转换如下图:
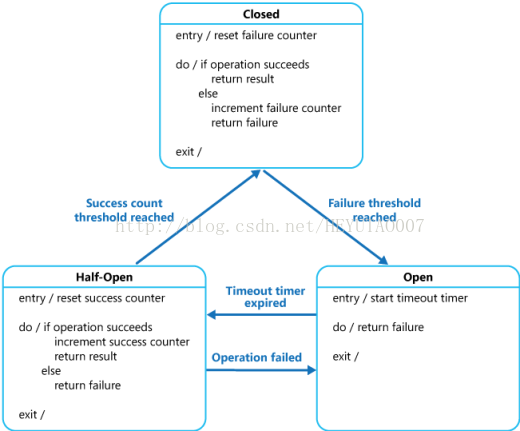
在Close状态下,错误计数器是基于时间的。在特定的时间间隔内会自动重置。这能够防止由于某次的偶然错误导致熔断器进入断开状态。触发熔断器进入断开状态的失败阈值只有在特定的时间间隔内,错误次数达到指定错误次数的阈值才会产生。在Half-Open状态中使用的连续成功次数计数器记录调用的成功次数。当连续调用成功次数达到某个指定值时,切换到闭合状态,如果某次调用失败,立即切换到断开状态,连续成功调用次数计时器在下次进入半断开状态时归零。
2.2.2、其他方案
2.3、命令模式HystrixCommand
Hystrix使用命令模式(继承HystrixCommand类)来包裹具体的服务调用逻辑(run方法), 并在命令模式中添加了服务调用失败后的降级逻辑(getFallback)。同时我们在Command的构造方法中可以定义当前服务线程池和熔断器的相关参数。
在使用了Command模式构建了服务对象之后, 服务便拥有了熔断器和线程池的功能。
public class Service1HystrixCommand extends HystrixCommand<Response> {
private Service1 service;
private Request request;
public Service1HystrixCommand(Service1 service, Request request){
supper(
Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ServiceGroup"))
.andCommandKey(HystrixCommandKey.Factory.asKey("servcie1query"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("service1ThreadPool"))
.andThreadPoolPropertiesDefaults(HystrixThreadPoolProperties.Setter()
.withCoreSize(20))//服务线程池数量
.andCommandPropertiesDefaults(HystrixCommandProperties.Setter()
.withCircuitBreakerErrorThresholdPercentage(60)//熔断器关闭到打开阈值
.withCircuitBreakerSleepWindowInMilliseconds(3000)//熔断器打开到关闭的时间窗长度
))
this.service = service;
this.request = request;
);
}
@Override
protected Response run(){
return service1.call(request);
}
@Override
protected Response getFallback(){
return Response.dummy();
}
}
2.4、观察者模式
Hystrix通过观察者模式对服务进行状态监听。每个任务都包含有一个对应的Metrics,所有Metrics都由一个ConcurrentHashMap来进行维护,Key是CommandKey.name()。在任务的不同阶段会往Metrics中写入不同的信息,Metrics会对统计到的历史信息进行统计汇总,供熔断器以及Dashboard监控时使用。
2.4.1、Metrics
Hystrix的Metrics中保存了当前服务的健康状况, 包括服务调用总次数和服务调用失败次数等. 根据Metrics的计数, 熔断器从而能计算出当前服务的调用失败率, 用来和设定的阈值比较从而决定熔断器的状态切换逻辑. 因此Metrics的实现非常重要.
2.4.2、Metrics如何统计
Metrics在统计各种状态时,运用滑动窗口思想进行统计的,在一个滑动窗口时间中又划分了若干个Bucket(滑动窗口时间与Bucket成整数倍关系),滑动窗口的移动是以Bucket为单位进行滑动的。桶中记录当前时间窗的各种事件(成功,失败,超时,线程池拒绝等)的计数。
如:HealthCounts 记录的是一个Buckets的监控状态,Buckets为一个滑动窗口的一小部分,如果一个滑动窗口时间为 t ,Bucket数量为 n,那么每t/n秒将新建一个HealthCounts对象。
1.4之前的滑动窗口实现
事件产生时, 数据结构根据当前时间确定使用旧桶还是创建新桶来计数, 并在桶中对计数器经行修改.这些修改是多线程并发执行的, 代码中有不少加锁操作,逻辑较为复杂.
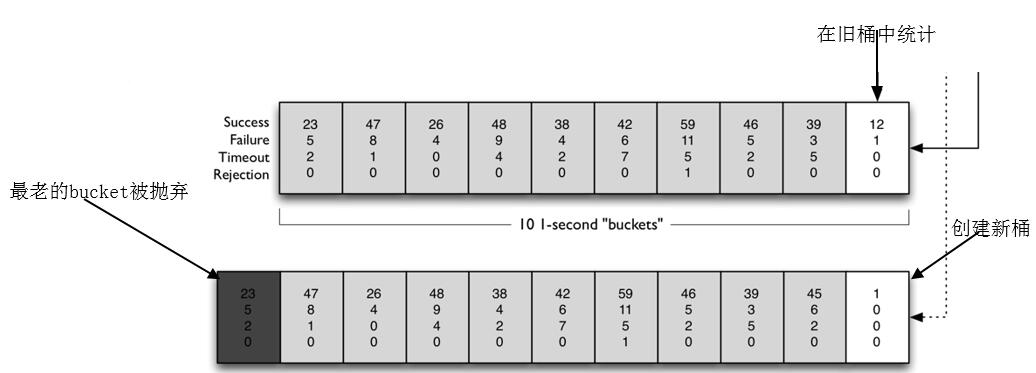
1.5之后的滑动窗口实现
Hystrix在这些版本中开始使用RxJava的Observable.window()实现滑动窗口。RxJava的window使用后台线程创建新桶, 避免了并发创建桶的问题。同时RxJava的单线程无锁特性也保证了计数变更时的线程安全. 从而使代码更加简洁。
3、Hystrix参数说明
https://github.com/Netflix/Hystrix/wiki/Configuration
Command Properties
Execution
控制HystrixCommand.run()的执行策略
execution.isolation.strategy 执行隔离策略
THREAD 每次在一个线程中执行,并发请求数限制于线程池的线程数
SEMAPHORE 在调用线程中执行,并发请求数限制于semaphore信号量的值
Thread是默认推荐的选择。
execution.isolation.thread.timeoutInMilliseconds
超时时间,默认1000ms
execution.timeout.enabled
是否开启超时,默认true
execution.isolation.thread.interruptOnTimeout
当超时的时候是否中断(interrupt) HystrixCommand.run()执行
Fallback
设置当fallback降级发生时的策略
Circuit Breaker
配置熔断的策略
circuitBreaker.enabled
是否开启熔断,默认true
circuitBreaker.requestVolumeThreshold
设置一个滑动窗口内触发熔断的最少请求量,默认20。例如,如果这个值是20,一个滑动窗口内只有19个请求时,即使19个请求都失败了也不会触发熔断。
circuitBreaker.sleepWindowInMilliseconds
设置触发熔断后,拒绝请求后多长时间开始尝试再次执行。默认5000ms。
circuitBreaker.errorThresholdPercentage
设置触发熔断的错误比例。默认50,即50%。
circuitBreaker.forceOpen
是否强制开启熔断
circuitBreaker.forceClosed
是否强制关闭熔断
Metrics
设置关于HystrixCommand执行需要的统计信息
metrics.rollingStats.timeInMilliseconds
设置滑动窗口的统计时间。熔断器使用这个时间。
默认10s
metrics.rollingStats.numBuckets
设置滑动统计的桶数量。默认10。metrics.rollingStats.timeInMilliseconds必须能被这个值整除。
metrics.rollingPercentile.enabled
设置执行时间是否被跟踪,并且计算各个百分比,50%,90%等的时间。默认true。
Request Context
设置HystrixCommand使用的HystrixRequestContext相关的属性.
requestCache.enabled
设置是否缓存请求,request-scope内缓存。默认true
requestLog.enabled
设置HystrixCommand执行和事件是否打印到HystrixRequestLog中。
ThreadPool Properties
配置HystrixCommand使用的线程池的属性。
大多数情况下默认的10个线程都是值得建议的。
coreSize
设置线程池的core size,这是最大的并发执行数量。默认10
maxQueueSize
最大队列长度。设置BlockingQueue的最大长度。默认-1。
如果设置成-1,就会使用SynchronizeQueue。
如果其他正整数就会使用LinkedBlockingQueue。
queueSizeRejectionThreshold
设置拒绝请求的临界值。只有maxQueueSize为-1时才有效。
设置设个值的原因是maxQueueSize值运行时不能改变,我们可以通过修改这个变量动态修改允许排队的长度。默认5
keepAliveTimeMinutes
设置keep-live时间。默认1分钟
这个一般用不到因为默认corePoolSize和maxPoolSize是一样的。














 8408
8408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









