







本文是自己学习隐马尔科夫模型的一个总结,为了自己以后方便查阅,也算作是李航老师的《统计学习方法》的一个总结,若有疑问,欢迎讨论。
推荐阅读知乎上Yang Eninala写的《如何用简单易懂的例子解释隐马尔可夫模型?》,写的非常好。我会联系两者,来作为自己的一篇学习笔记。
隐马尔可夫模型: 隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐藏的马尔可夫链随机生成的状态的序列,称为状态序列(state sequence),每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列(observation sequenoe )。序列的每一个位置又可以看作是一个时刻。




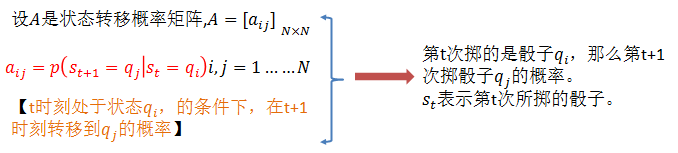

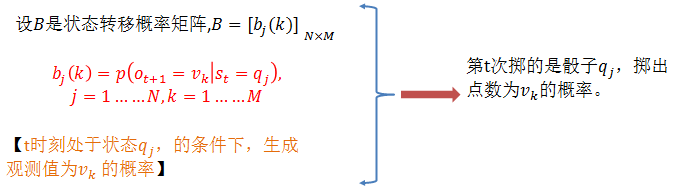

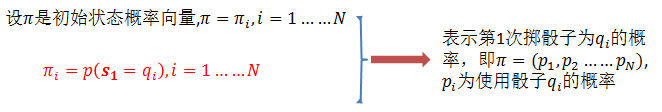
隐马尔科夫模型的3个基本问题:
(1)概率计算问题。给定模型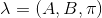
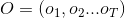
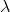
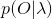
(2)学习问题。已知观测序列
(3)预测问题,也称为解码(decoding)问题。已知模型参数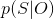
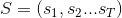
概率计算问题:
1、 直接计算方法
这种方法说白了就是暴力搜索,枚举每一种状态序列,然后在根据状态序列求出观测序列的概率。
思想很简单,可以这么想:假如我们现在已知状态序列为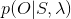
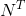
状态序列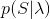
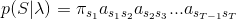
对已经假设的状态序列
,观测序列,的概率是: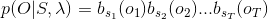
观测序列O和状态序列S同时出现的概率是:
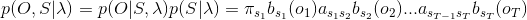
最后,对所有的状态序列S求和,即可得到观测序列O的概率
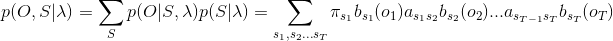
对于实现上式,很简单,
2、前向算法:
给定隐马尔可夫模型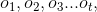
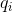
可以递推地求得前向概率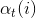
这个可以这么理解,已知选每种骰子的概率,每种骰子的输出概率,那么前t次掷骰子,掷出的点数为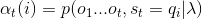
(1)初值:
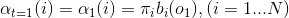 ,掷出的点数为
,掷出的点数为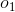 的概率,其中
的概率,其中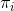 表示开始的时候选用骰子的概率】
表示开始的时候选用骰子的概率】
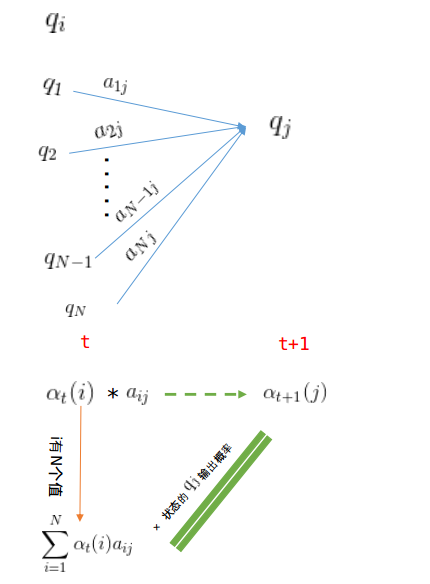
(2)递推:
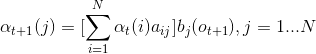
【第t+1次用骰子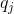
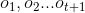
上式方括号中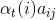
由于第t次骰子的种类有N种,因此,第t+1次使用
(3)终止:
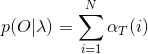
根据(2)的递推式子可以求出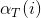
例子1(前向算法):考虑盒子和球模型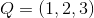
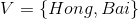
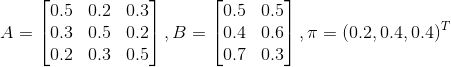
设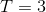
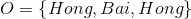
根据上面我们描述的算法,一步一步地计算,
(1)计算初值:
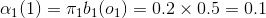
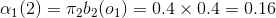
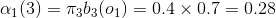
(2)递推:
当

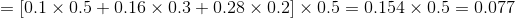

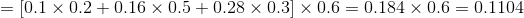

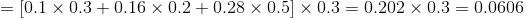
当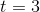
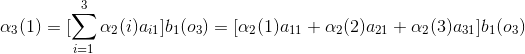
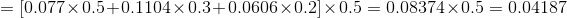

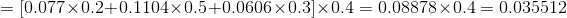
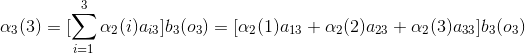

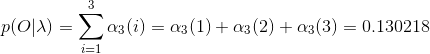
3、后向算法
给定隐马尔可夫模型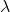
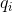
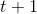
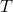
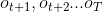
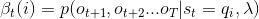
可以递推地求得后向概率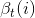
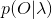
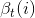
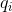
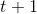
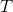

(1)初值
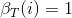
【解释:已知最后一次所用的骰子为
(2)递推
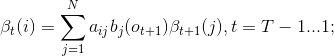
(3)终止
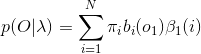
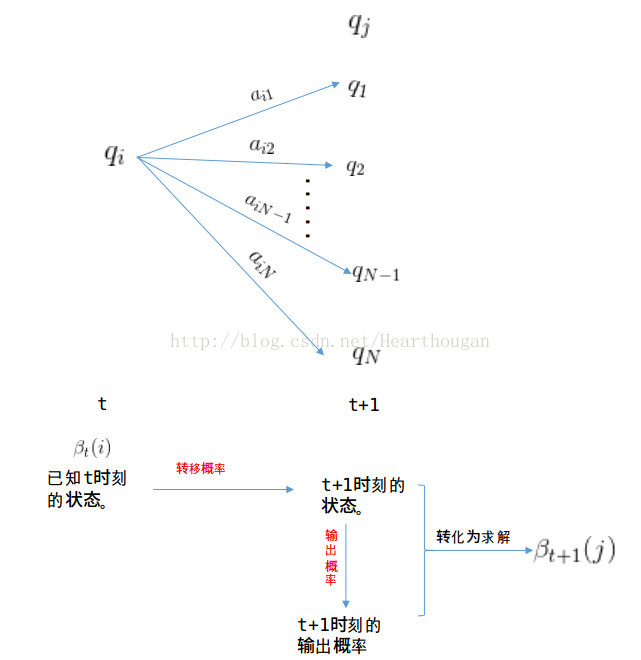
后向算法依旧是解决概率计算问题,只不过是两种计算方式,计算结果应该是和前向算法相同,可以用例1验证一下,如下:
例2(后向算法),考虑盒子和球模型

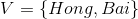
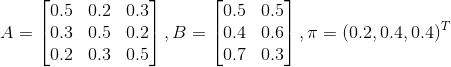
设

我们仍然根据上面的算法描述,一步一步地计算,
(1)计算初值
当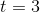

(2)递推
当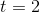
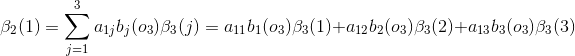
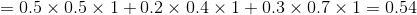
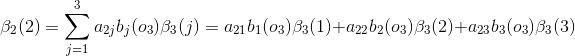
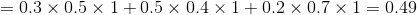
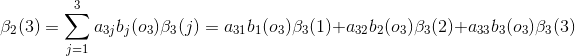
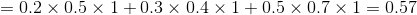
当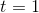
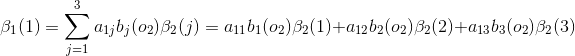
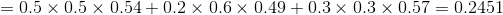
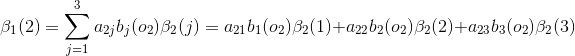
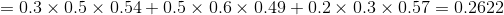
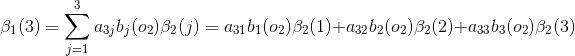

(3)终止

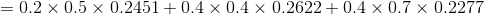
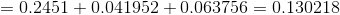
可以根绝前向算法和后向算法的定义,将两种计算方式结合起来,如下:















 8475
8475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









