









一. 前言
1 . 语言要求
对于算法而言,它其实是与语言无关的,被誉为算法神书的《算法导论》中都是以伪码的形式进行编写。算法更重要的是一种思想,当你想透彻后编代码实现就不是问题了。由于不同的语言含有独特的特性,在某些语言实现算法过程中可利用其特性可更好地实现算法思想,此系列中的代码主要支持C++语言,后期会提供Java语言扩展。
2 . 基础要求
此系列博文重点讲解算法实现,默认读者
- 具备基础语言知识
- 了解数组、链表、堆栈等线性结构
- 对基本算法知识有常识性了解即可,例如递归、遍历、算法复杂度
对于以上点有基本认识概念即可(后续会介绍重点),将在此基础上进行解析。
3 .学习路径
- 线性(排序)

此系列首先会讲解线性结构,主要体现在排序算法上,稍有了解的学者应当知晓关于排序的算法并不少,通过此部分学习可深入了解许多算法思想。
- 树形结构
此部分将介绍几种重要的树形结构的算法思想、应用场景,它们之间的区别、特点、局限性等一一探究。
- 图形结构
此部分主要介绍图论相关的基础算法。
对于算法而言,编程是次要的,更重要的还是思想,例如面试中的常见的“白板编程”,便是如此,一块白板不可能让你实现多长的代码,通常十几行甚至不足十行就可以考察出你对其算法的思想理解深度。
4. 数据结构的重要性
查看以上学习路径会发现重点更偏向于数据结构,从简单的线性过渡到图结构。确实如此,数据结构在编程中的地位是承上启下的。

Linux创始人表达了如上的看法:优秀与平庸的程序员之间的区别就是数据结构的使用上,更重要的是算法与数据结构是融合一体、无法分隔的。
Algorithms + Data Structrues = Programs
算法 + 数据结构 = 编程
其实很多算法是依托于数据结构而存在的,包括面试中很多问题看似算法问题,本质还是数据结构,考察的远比我们想象的要基础,基础的重要性从来无需多言。例如微软曾面试过的代码实现堆、二叉树翻转等,无不是在考察基础。
5. 算法思想
在强调数据结构的重要性后,其中算法思想也是不容忽略:
- 分治算法:归并排序、快速排序……
- 贪心算法:最小生成树……
- 动态规划:最短路径……
- 递归搜索:树形结构……
以上所举的例子可以看出数据结构和算法之间的互相依托程度,例如在学习归并、快速排序时,实则也在探究分治算法……
每个细分领域都是算法,例如以下例子:
- 图形学
- 机器学习
- 人工智能
- 数据挖掘
- 操作系统
- 网络安全
- 高性能计算
最后,借用Donald的一句话,来展开学习算法之美~

6. IDE
此系列的所有代码测试我使用的C++编译器并非是VC++,而是CLion,整体界面、使用与我而言更加得心应手,以下是下载地址。其余C++编译器均可。
二 . 选择排序
首先开始学习的是排序算法,最基本的 O(n^2)时间复杂度的排序算法,需要了解的是最优解的时间复杂度为 O(n*logn),那为何还要学习较复杂的算法?
O(n^2)时间复杂度的排序算法编码简单,易于实现,是一些简单情景的首选!在一些特殊情况下,简单的排序算法更有效。简单的排序算法思想衍生出复杂的排序算法,作为子过程,改进更复杂的排序算法。在面试中若没有思路,不如先简单实现,再从其中优化,找到最优解。
1. 算法思想
选择排序的实现思想较为简单,例如以下gif图示,有一组不规则数字排序{8,6,2,3,1,5,7,4},需要将它们从小到大进行排序。
- 首先在数组中找出第一名的位置(即最小的数字 1),将它与目前数组中第一名(即数字8)进行交换。
- 此时数组中第一个位置已是最小数字,接着在其余位置中找寻最小数字,与其数组中目前的第二个位置进行交换。
- 后面过程依次类推,直到剩下最后一个位置,已无需排序,已为最大值。

2. 代码实现
#include <iostream>
#include <algorithm>
using namespace std;
void selectionSort(int arr[], int n){
for(int i = 0 ; i < n ; i ++){
// 寻找[i, n)区间里的最小值
int minIndex = i;
for( int j = i + 1 ; j < n ; j ++ )
if( arr[j] < arr[minIndex] )
minIndex = j; //记录数组中最小值下标
//这里使用的swap交换函数是C++标准库中内置函数,对于C++11而言此函数在命名空间std中(即 using namespace std;),而老的标准需要导入#include <algorithm>
swap( arr[i] , arr[minIndex] );
}
}
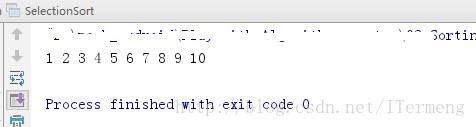
int main() {
int a[10] = {10,9,8,7,6,5,4,3,2,1};
selectionSort(a,10);
for( int i = 0 ; i < 10 ; i ++ )
cout<<a[i]<<" ";
cout<<endl;
return 0;
}结果显示
三. 使用优化
在介绍其余算法之前,需要对以上代码稍作优化,此优化并非是算法上,而是在于使用上,为了后续讲解使用更加高效。
1. 使用模板(泛型)编写算法
从以上代码可以看出此算法排序只针对于 int 类型,所以首先进行优化的便是使用模板(泛型)编写算法,这样针对的范围可扩大于浮点型、字符串,甚至于结构体。
在C++中声明为模板函数非常简单,只需在函数头前加上template<typename T>,再修改参数类型即可:
//使用模板(泛型)编写算法
template<typename T>
void selectionSort(T arr[], int n){
for(int i = 0 ; i < n ; i ++){
int minIndex = i;
for( int j = i + 1 ; j < n ; j ++ )
if( arr[j] < arr[minIndex] )
minIndex = j;
swap( arr[i] , arr[minIndex] );
}
}这样在main方法中对浮点型、字符串等类型排序兼支持,这里不多测试。
2. 随机生成算法测试用例
在优化了以上一点后,查看测试代码发现其中还有一个隐患,即测试的数据是自定义的,且数量过少,为了后续比较不同算法复杂度测试,需要满足随机生成算法测试用例的条件。
后续还有多种排序算法的复杂度需要做比较,为此创建一个新的 .h 文件SortTestHelper。
文件中的generateRandomArray辅助函数将随机生成一个int型数组,即返回值是int型指针,其中函数中的3个参数:
- n:数组中的元素
- rangeL 和 int rangeR:随机范围[rangeL, rangeR]
此随机数的生成实现是将时间作为种子,来进行随机设置,再通过遍历为数组进行赋值,其中进行取余运算来控制随机范围。代码如下:
【SortTestHelper.h】
/*
* 排序测试帮组文件
* */
namespace SortTestHelper {
// 生成有n个元素的随机数组,每个元素的随机范围为[rangeL, rangeR]
int *generateRandomArray(int n, int rangeL, int rangeR) {
//使函数健壮,检验rangeL 是否小于rangeR,调用assert函数,需要加载#include <cassert>库
assert(rangeL <= rangeR);
int *arr = new int[n];
//需要加载#include <ctime>库
srand(time(NULL));
for (int i = 0; i < n; i++)
arr[i] = rand() % (rangeR - rangeL + 1) + rangeL;
return arr;
}
// 打印arr数组的所有内容
template<typename T>
void printArray(T arr[], int n) {
for (int i = 0; i < n; i++)
cout << arr[i] << " ";
cout << endl;
return;
}
};算法测试调用
int main() {
int N = 20000;// 测试排序算法辅助函数
//调用帮组文件中的随机生成测试用例函数
int *arr = SortTestHelper::generateRandomArray(N,0,100000);
selectionSort(arr,N);
//调用帮组文件的打印函数
SortTestHelper::printArray(arr,N);
delete[] arr; //注意最好使用完后就delete使用的数组空间,避免占用
return 0;
}注意一个小细节,这里的主函数在测试完后及时使用delete[]释放掉了数组空间。其实即便不加也不会有问题,但是存在潜在的内存泄漏问题,所以防患于未然。
3. 测试算法性能
接下来需要在测试帮助文件中编写一个辅助函数来比较测试不同算法之间的性能差异,最简单的方式去判断算法性能就是在特定测试集上的执行时间。
注意,函数testSort中提供的几个参数较为重要:
- const string &sortName:采用的排序算法名称。
- void (*sort)(T[], int):函数指针,由于函数执行时间通过此帮助文件的辅助函数实现,所以需要传入排序函数的指针。
- T arr[]:待排序数组。
- int n:数组个数。
辅助方法中实现具体为在调用排序函数前后分别获取时间,再相减即可获取排序执行时间。
【SortTestHelper.h】
// 判断arr数组是否有序
template<typename T>
bool isSorted(T arr[], int n) {
for (int i = 0; i < n - 1; i++)
if (arr[i] > arr[i + 1])
return false;
return true;
}
// 测试sort排序算法排序arr数组所得到结果的正确性和算法运行时间
template<typename T>
void testSort(const string &sortName, void (*sort)(T[], int), T arr[], int n) {
clock_t startTime = clock();
sort(arr, n);
clock_t endTime = clock();
//调用isSorted函数测试排序是否正确无误,注意执行顺序不可放入调用clock()之前,否则该检验过程会影响真实排序效率
assert(isSorted(arr, n));
cout << sortName << " : " << double(endTime - startTime) / CLOCKS_PER_SEC << " s" << endl;
return;
}算法测试调用
int main() {
int n = 20000;
int *arr = SortTestHelper::generateRandomArray(n,0,n);
SortTestHelper::testSort("Selection Sort", selectionSort, arr, n);
delete[] arr;
return 0;
}显示结果(对20000个无序数字进行 选择排序,最终使用时间):
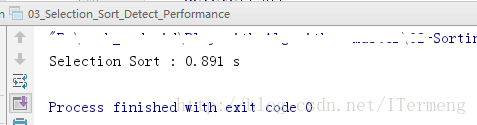
此时的main 函数看起来已经十分简洁了,其中的随机生成测试用例及排序函数过程执行时间都依赖于测试帮助文件SortTestHelper完成,而三个优化已经完成。
三. 插入排序
1. 算法思想
插入排序的思想同生活中整理扑克牌顺序有些类似,将后面的牌按照大小顺序插入到前面来。{8,6,2,3,1,5,7,4}
- 首先第一个元素8,由于它的位置是第一个,所以保持不动。
- 继续看第二个位置的元素是6,比前面的元素8小,两者交换位置。
- 继续看第三个元素2,比第二个元素8小,交换位置,此时元素2是第二个位置,再同第一个元素6进行比较,比它小继而交换位置。
- 后面过程依次类推。

2. 代码实现
注意:
- 插入排序中的外层循环下标不再是从0开始,而是从1开始(从第二个元素开始对前面的元素进行比较)。
- 在每次循环里需要做的是寻找元素arr[i]前面合适的插入位置。
template<typename T>
void insertionSort(T arr[], int n){
for( int i = 1 ; i < n ; i ++ ) {
// 寻找元素arr[i]合适的插入位置
for( int j = i ; j > 0 ; j-- )
if( arr[j] < arr[j-1] )
swap( arr[j] , arr[j-1] );
else
break;
// 写法2
/*
for( int j = i ; j > 0 && arr[j] < arr[j-1] ; j -- )
swap( arr[j] , arr[j-1] );
*/
}
return;
}以上内容实现你会发现其实内循环中的判断条件有两个,所以可直接改进为写法2,将两个判断条件放在一起。
选择排序和插入排序的根本区别
插入排序的内循环在满足条件的情况下是可以提前结束的!而选择排序必须遍历每一次循环。所以插入排序理论上比选择排序更快一些。
测试选择排序和插入排序
由于测试这两个排序算法效率的准确性,所以两者的测试用例数组应相同,即需要再复制一份,在测试帮助文件中新增一个辅助方法进行数组复制。
【SortTestHelper.h】
// 拷贝整型数组a中的所有元素到一个新的数组, 并返回新的数组
int *copyIntArray(int a[], int n){
int *arr = new int[n];
//命名空间std中的函数
copy(a, a+n, arr);
return arr;
}测试主函数代码如下:
// 比较SelectionSort和InsertionSort两种排序算法的性能效率
// 此时, 插入排序比选择排序性能略低
int main() {
int n = 20000;
cout<<"Test for random array, size = "<<n<<", random range [0, "<<n<<"]"<<endl;
int *arr1 = SortTestHelper::generateRandomArray(n,0,n);
int *arr2 = SortTestHelper::copyIntArray(arr1, n);
SortTestHelper::testSort("Insertion Sort", insertionSort,arr1,n);
SortTestHelper::testSort("Selection Sort", selectionSort,arr2,n);
delete[] arr1;
delete[] arr2;
cout<<endl;
return 0;
}显示结果
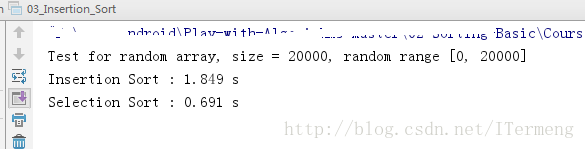
从以上结果发现这与之前的理论分析有所出入,插入排序反而比选择排序效率低。具体原因稍后解析,接下来将针对插入排序的特性来进行优化,最后你会发现在某些情况下插入排序的效率不比 O(n*㏒n)差。
3. 代码优化
(1)减少多次交换swap操作
以上发现插入排序中的内循环可提前结束性质后,可是测试结果却出乎意料。再仔细观察发现内循环中存在的swap操作比简单的比较操作更加耗时,因为swap交换中其实涉及到了3次赋值步骤,更不用说数组中的索引值访问等消耗时间。
所以这第一个优化就是避免在内循环中重复swap,只进行一次赋值操作,在内循环结束后再进行一次赋值操作,彻底避免交换操作。

查看以上GIF演示过程,这里以第三个元素2进行示例讲解(找到元素2应该待的位置){6,8,2,3,1,5,7,4}:
- 在进行第三个元素2比较之前,先将元素值2复制一份保存起来再开始比较。
- 第三个元素2比第二个元素8小,即2不应该在这个位置。此时不进行交换操作,而是进行赋值,将第三个元素赋值为8。
- 接下来考虑2是否应该在第二个元素8的位置,将2同第一个元素6比较,比它小,即2不应该在这个位置。此时不进行交换操作,而是进行赋值,将第二个元素赋值为6。
- 最后来看2是否应该放在元素6的位置,发现元素6的位置就是第一个位置,所以最后直接第一个元素赋值为2。
其实算法的逻辑并无改变,只是将原来满足条件下的一次次交换修改成了赋值操作,性能得到提高。
代码实现:
for( int i = 1 ; i < n ; i ++ ) {
// 寻找元素arr[i]合适的插入位置
// 写法3
T e = arr[i];
int j; // j保存元素e应该插入的位置
for (j = i; j > 0 && arr[j-1] > e; j--)
arr[j] = arr[j-1];
arr[j] = e;//赋值操作
}
return;
}测试结果

此时再次查看两种算法的时间所耗,发现插入算法已经优于选择排序!
这里需要注意一点,插入排序的优异性在于内循环可以提前结束,即在部分有序的数组中进行排序,性能会更加优异,两者的差异会更大。而且需要注意的是在处理实际数据时,其实数字之间比较有序,只是个别并无太多无序性,所以插入排序的高效性此时更为有用。
下面在SortTestHelper中再加入一个辅助函数来生产一个近乎有序的数组供测试用,实现较为简单,代码如下:
【SortTestHelper.h】
// 生成一个近乎有序的数组
// 首先生成一个含有[0...n-1]的完全有序数组, 之后随机交换swapTimes对数据
// swapTimes定义了数组的无序程度:
// swapTimes == 0 时, 数组完全有序
// swapTimes 越大, 数组越趋向于无序
int *generateNearlyOrderedArray(int n, int swapTimes){
int *arr = new int[n];
for(int i = 0 ; i < n ; i ++ )
arr[i] = i;
srand(time(NULL));
for( int i = 0 ; i < swapTimes ; i ++ ){
int posx = rand()%n;
int posy = rand()%n;
swap( arr[posx] , arr[posy] );
}
return arr;
}近乎有序的数组测试结果
int main() {
int n = 20000;
// 测试近乎有序的数组
int swapTimes = 100;
cout<<"Test for nearly ordered array, size = "<<n<<", swap time = "<<swapTimes<<endl;
arr1 = SortTestHelper::generateNearlyOrderedArray(n,swapTimes);
arr2 = SortTestHelper::copyIntArray(arr1, n);
SortTestHelper::testSort("Insertion Sort", insertionSort,arr1,n);
SortTestHelper::testSort("Selection Sort", selectionSort,arr2,n);
delete[] arr1;
delete[] arr2;
return 0;
}
以上20000个数字,其实任意交换100对数字,最后排序的结果,插入排序明显优于选择排序太多,这也体现出在特定情况下(近乎有序的数字排序)插入排序的高效性!
四. 冒泡排序
1. 算法思想
这里简单说明一下冒泡排序,它的原理是从数组的第一个位置开始两两比较array[index]和array[index+1],如果array[index]大于array[index+1]则交换array[index]和array[index+1]的位置,止到数组最后一个元素比较完。
2. 代码实现
for (i = 0; i < n; i++)
{
for (j = i + 1; j < n; j++)
{
if (str[i] > str[j])
{
swap(&str[i], &str[j]);
}
}
} 3. 代码优化
以上是教科书、网络中最常见的一种慢跑排序实现方法,但是从优化的角度来思考,会发现每一趟Bubble Sort都将最大的元素放在了最后的位置,所以下一次排序,最后的元素可以不再考虑。此优化方法虽简单,但时间性能较于之前版本更佳。
void bubbleSort( T arr[] , int n){
bool swapped;
do{
swapped = false;
for( int i = 1 ; i < n ; i ++ )
if( arr[i-1] > arr[i] ){
swap( arr[i-1] , arr[i] );
swapped = true;
}
n --;
}while(swapped);
}五. 思维拓展
1. O(n^2)算法思考
这一篇博文主要学习了O(n^2)的排序算法:
- 其中选择排序实现简单,但是弊端明显,两重循环中的每次循环都要完成,效率较慢。
- 虽然插入排序的时间复杂度也是O(n^2),但是在数组近乎有序情况下,效率甚至比 O(n* logn)的还要高,有着重要的实际意义。
- 而冒泡排序中不可避免的会有许多交换操作,整体性能没有插入排序好,后续不会经常使用。
2. 希尔排序
在了解了插入排序的优点后,可通过它引出一种新的排序方法,即希尔排序,整体思路就是插入排序衍生,插入排序中是每个元素和之前1个元素进行比较,而希尔排序是每个元素和之前的t个元素进行比较,t从一个大值慢慢缩小成1,无序数组渐变为有序数组,时间复杂度发送质变!时间复杂度为O(n^(3/2))
代码如下:
template<typename T>
void shellSort(T arr[], int n){
// 计算 increment sequence: 1, 4, 13, 40, 121, 364, 1093...
int h = 1;
while( h < n/3 )
h = 3 * h + 1;
while( h >= 1 ){
// h-sort the array
for( int i = h ; i < n ; i ++ ){
// 对 arr[i], arr[i-h], arr[i-2*h], arr[i-3*h]... 使用插入排序
T e = arr[i];
int j;
for( j = i ; j >= h && e < arr[j-h] ; j -= h )
arr[j] = arr[j-h];
arr[j] = e;
}
h /= 3;
}
}
3. 下篇预告
虽然ShellSort是这四种排序算法中性能最优的排序算法,但是在排序算法中的最优解还是O(n*logn),所以在在下一篇博文中进行讲解,涉及的知识点:
- 归并排序法思想、实现、优化
- 自底向上的归并排序算法
- 快速排序法
- 随机化快速排序法
- 双路快速排序法
- 三路快速排序法
声明此系列记录于liuyubo老师算法讲解而衍生出来,在此感谢,下面是github地址附有源码,可供大家下载学习。
liuyubobobo老师的github地址
终于开始系统地啃算法和数据结构了,之前参加过算法小比赛,总感觉有些晦涩难懂,还有些畏惧心理,不愿狠下心来学习。最后还是下定决心好好学习这内功心法,算法之路,任重而道远~
若有错误,虚心指教~














 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









