









聊天机器人是现在AI技术的综合体现的一个很重要的产品形式,技术会涉及自然语言理解,即充分理解用户说的话的意思,也要涉及自然语言生成,产生合适的回答来返回给用户。由于自然语言本身形式的不确定性和复杂性,这个任务可以说是具有非常大的挑战,且效果也很难做一个非常准确和直接的评判。
但越困难的事情,越是充满了吸引力。我们团队中的成员在项目兴趣选择时,都不约而同地首选了这个聊天机器人项目。团队里有比较懂深度学习并有过一定实践经验的同学,也有对传统NLP方法有过深入研究并发表过paper的同学,还有对产品技术架构有过一定经验的成员,所以在大家聚集到工场之后,也对能够实现出一个具有初步效果的聊天机器人demo版本有着比较大的期待
技术架构初步设计
经过对市面上很多的聊天机器人,如小冰、小黄鸡、图灵机器人的测试后,我们发现其主要使用的技术还是检索式的算法,从大规模语料库中选出合适的回答,最后并辅以一定的规则系统,来对聊天机器人里出现的常见需求进行覆盖。
那我们的目标就是能实现一个能够进行基本日常对话的聊天机器人,并有一些自己的特色。所以最后经过设计,我们设计了如下产品架构方案,并将产品命名为“小猴”,希望它能够有聪明的头脑
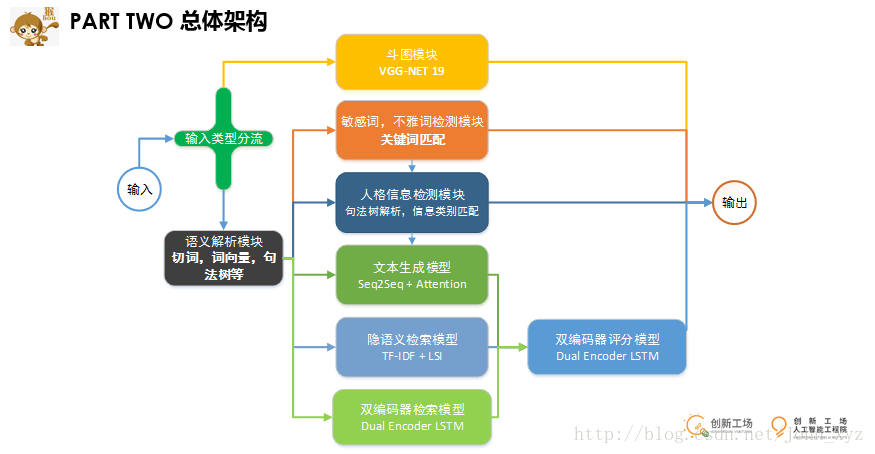
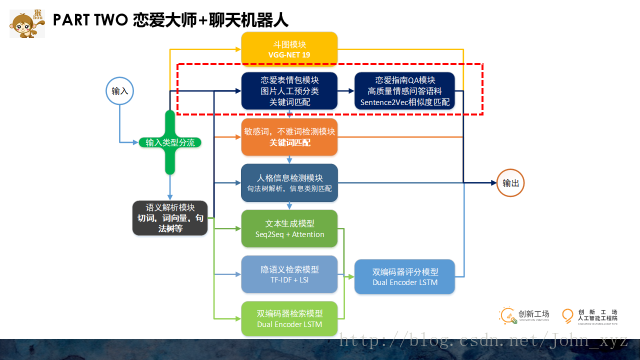
从架构图中,我们可以清楚地看到用户输入之后每一步的处理情况,系统对不同的输入进行分流,图片类型和文本类型都使用不同的模块去处理。
为了增加聊天的趣味性和输入的多样性,我们在日常的文字聊天之外增加斗图功能,即对用户的图片类型的输入也能进行一定的匹配,产生对应的图片回复,达到人类用户之间常有“斗图效果”。从技术细节上来说,我们首先从互联网上抓取大量的表情和图片,再利用VGG-NET提取特征向量,这样每个图片就可以转换成一个一维向量,对所有图片,我们可以得到一个矩阵,每一行代表每个图片的特征。对于用户输入的图片,可以通过相似度匹配找到最相似的五张图片,然后随机选取一个返回给用户。
而对于文本类型,则先进行语义解析,得到切词结果和word2vec等,再将语义结果依次经过敏感词检测,人格信息检测模块。如果在这一步输入能够被处理,则直接返回其对应的结果。如用户发送“SB”等骂人的话,则在不雅词汇检测中,系统就能发现,并返回类似“要做一个文明说话的宝宝哦”类似的话。
架构图中有一个环节是人格信息检测,可能有的人不理解什么叫做”人格信息检测”,其实就是去检测用户说的话是不是针对机器人自己的各种信息。因为我们发现在人类用户已知对方是聊天机器人的情况下,在聊天对话上会有相当一部分的比例是去会去询问关于机器人自身的信息,比如“你几岁了”,“你明天准备做什么“,”你的爸爸妈妈是谁“等等一系列问题。而如果想使聊天机器人能达到一个比较好的智能效果,那么就必须要给机器人设定好一个固定的人格,保证每次用户的不同问法,能够给出相同的一致的结果。
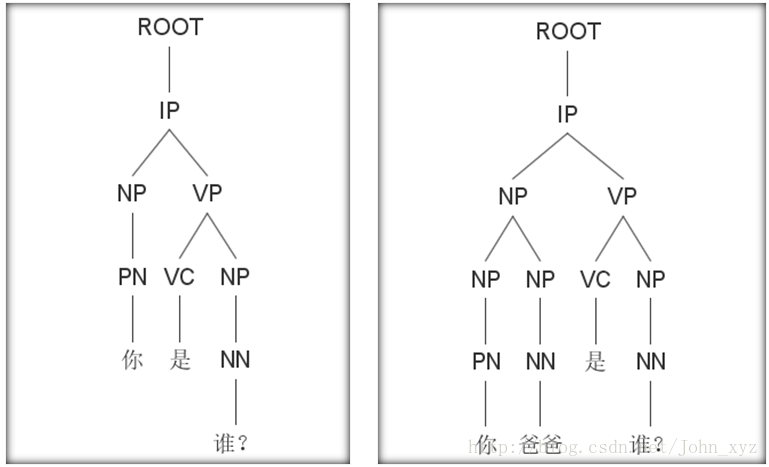
那么如果想达到这个效果,就必须要针对这个问题做出相应的一些工作和努力。我们目前采用的技术方案是句法树解析和检索相结合的方式,之所以要上句法树解析,是因为在句子级别,任何一个词的变化,都会引起语义的巨大变化。比如“你是谁?“、“你爸爸是谁?”、“我爸爸是谁?”三个问句,分别只相差一个词,如果简单只用检索模型或者深度学习的生成模型,都很难准确地做出准确的回答。这时候就只能从底层的句法依存树尝试去解析出其真正的含义。下图展示了句法解析树对于两句话的解析结果
当前面的模块都顺利通过,说明用户可能就是非常普通地想和你聊天,比如他说“北京是个好地方”或者“创新工场厉不厉害”之类的。而更加开放的,无法预知内容的聊天输入就交给由大语料支撑下形成的检索或者生成模型来应对。用户的输入最后会被送入由生成模型、隐语义检索模型、双编码器检索模型三个模型共同构成的开放性聊天模块,最后再将三个模块生成的候选集再次用一个双编码器模型进行评分,判断候选输出与输入之间的相关性,最终取出概率较高的一个作为最终输出。
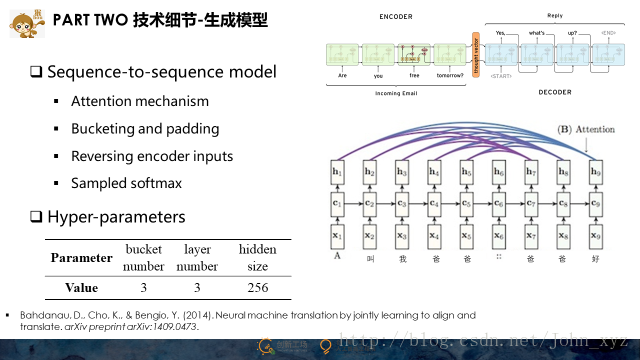
比如拿生成模型来说,我们所使用的是目前相对比较成熟的Seq2Seq+Attention模型,并在bucket,Sampled softmax等几个细节上做了一些小小的优化。
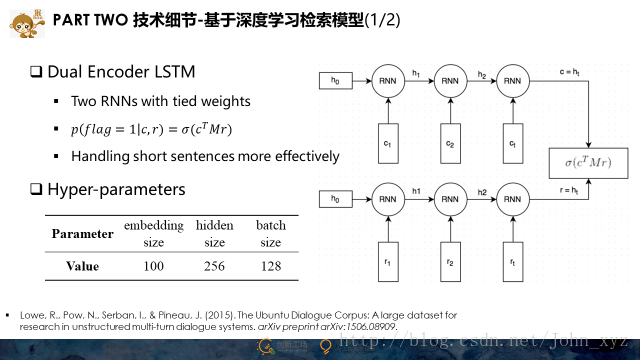
而基于深度学习的检索模型,对于长文本,我们采用的是隐语义检索模型,其基本流程是:先将我们的训练集中问答对中的问题用词袋模型映射到向量空间中,再经过去停留词,TF-IDF变换和LSI变换,可以得到一个固定维度的特征向量。基于这个特征向量,可以找到最相似的问题,最后把其答案最为最终结果。但对于短文本,该模型效果并不理想,为解决这个问题,我们采用的方案是Dual Encoder LSTM模型,其主要思想是将每一个匹配的问答看做一个分类样本,判断其是匹配的还是不匹配的,作为一个分类问题来处理。所以这个模型最后也可以被转换用来做评分模型,取出问答之间的匹配概率作为其最终得分。
按照这个架构,我们团队做了4周多的工作,完成了其中的大部分模块,并部署到了微信上,(使用itchat模块)初步打通了整个聊天机器人的流程。初步的效果图如下:
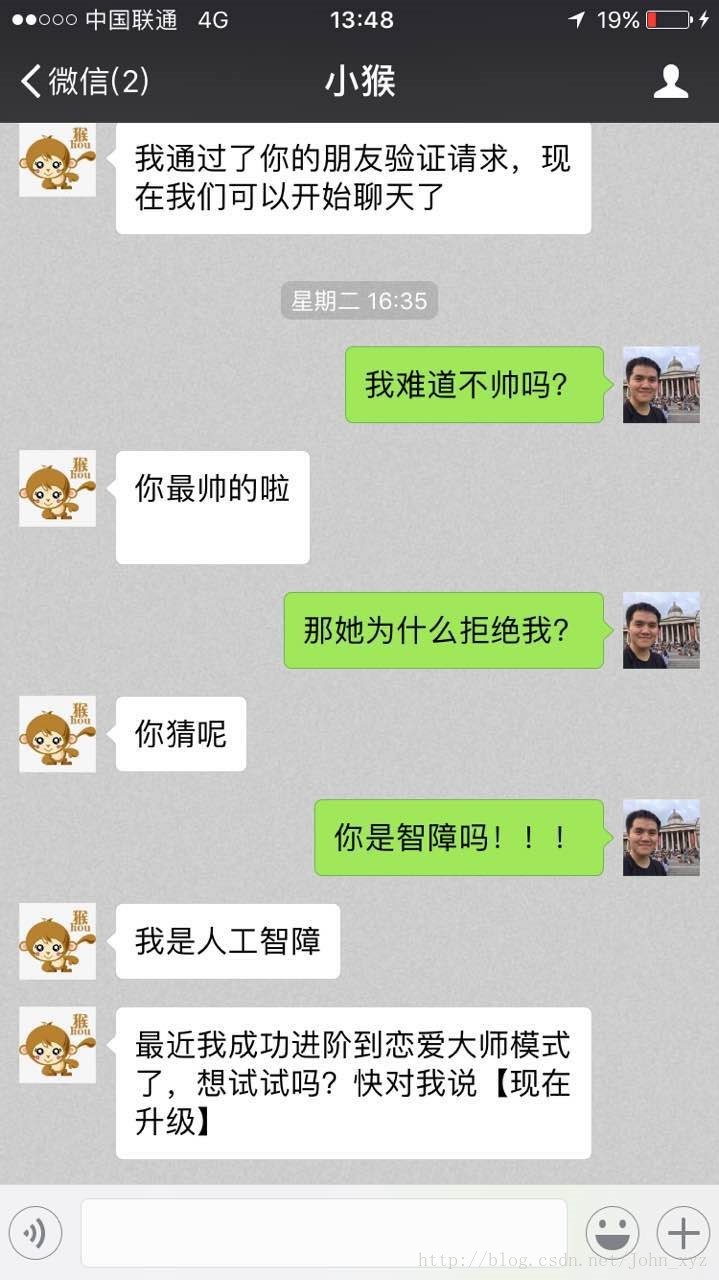
做一个更有意思的聊天机器人
但是这样的一个机器人做完之后,其回答的效果也时好时坏。但从目前我们团队的技术积累,还有从剩余时间的长度考虑上上想要有一个质的突破非常困难。
那如何让我们的聊天机器人更上一步呢?这时团队里有一个队员提出了一个idea,不妨做一个有创意的聊天机器人,专注于一个特定领域,而不是一个开放领域。既主动降低了用户期望,也可以适当减小技术难度。
最后我们选择了一个目前市面上还没有什么人做过的恋爱主题,准备以恋爱助手为切入点,以聊天机器人QA的形式向用户提供关于恋爱技巧、约会指南等的帮助。为此我们从网络上搜集了大量的具有较高质量的情感类问答语料和恋爱常用的表情包。

在算法方面我们用了基于TF-IDF的加权Embedding作为query的Sentence2Vec,最后再用相似度匹配算法检索出最匹配的问题,取出其对应较好的回答
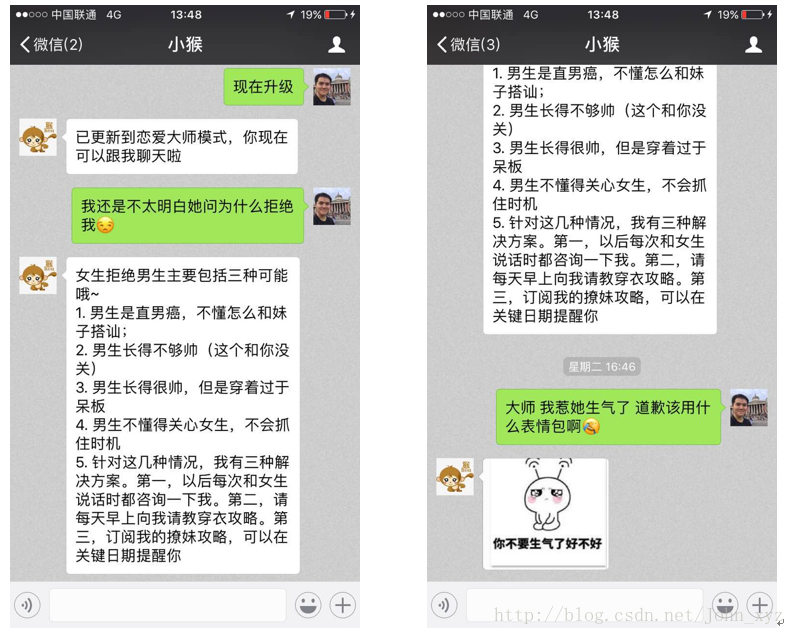
最终达成的效果图如下,用户在QA模式下输入的情感问题,会被算法进行匹配,然后按照对应的策略,取出合适的回答,返回给用户
经过6个星期的努力,最终我们完成了一个具有一定特色的,具备基本功能的聊天机器人。在这个过程中,感受很深刻的是想做一个聊天机器人,可以说比较简单,简单的是只要有充足的语料,很多模型是现成的,只要按部就班往上套,最后整合起来就能做出一个demo版本的产品。但是同时这又是很困难的,作为AI领域的“终极”任务,要非常准确地理解用户说的每一句话几乎是不可能的,而且我们所能拥有的语料终究是有限的,不可能能把世界上所有可能的对话场景都包含进来。
任重而道远,但是经过这一段时间的磨练和实践,我们也对深度学习、对AI有了更深的理解,团队成员也对各自的方向有了更多的认识。这就是最大的收获吧。
项目开源地址:https://github.com/DeeChat
2017.7.12 - 2017.8.17于创新工场人工智能工程院














 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









