







主要熟悉下稍微复杂点的sql语句跟存储过程。总的来说,记一句sql大概就能应付很多情况了:
select from__where__group by__having__order by
SQL命令类型:
数据定义语言:DDL
数据操作语言:DML
数据查询语言:DQL
数据控制语言:DCL
数据管理命令
事务控制命令
1.建表
create table users(
id int(11) primary key auto_increment,
username varchar(20),
age int(11),
gender char(1),
birthday date,
city varchar(20),
salary float(20)
)2.修改表结构(加一列,名为company,类型varchar(20)):
alter table users add column company varchar(20);3.插入一条记录
insert into users(username,age,gender,birthday,city,salary,company) values('路飞',17,'男','1991-08-30','杭州',20000.00,'移动');4.修改记录(只改了两个字段):
update users set age=19,gender='女' where username='路飞'5.删除数据:
delete from user where id=1;6.查询(大项):
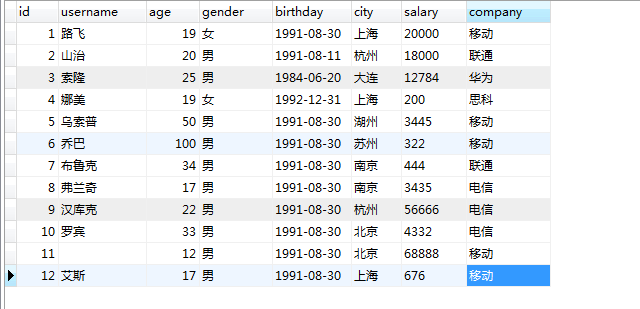
select * from users;下面的查询主要根据这张表来
order by 子句:让输出以某种方式进行排序,默认升序
select * from users where gender='男' order by age;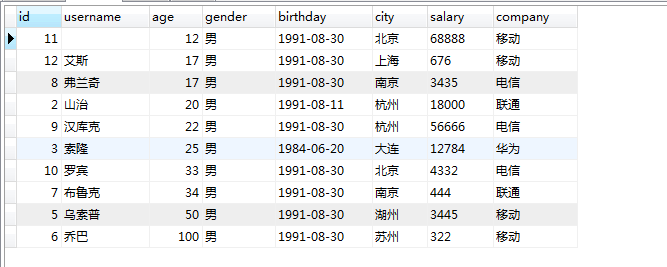
降序
select * from users where gender='男' order by age desc;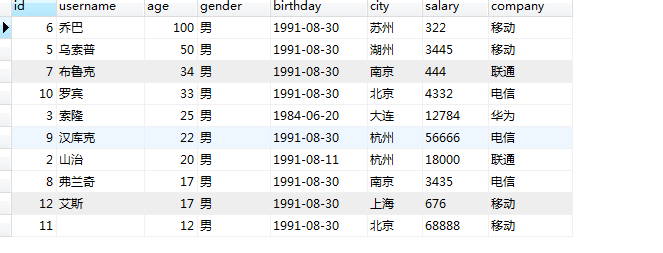
统计数量(*可以替换为某一列):
select count(*) from users;比较操作符(只举一例):
相等:=
不等:<>
大于:>
小于:<
select username,age from users where age<30;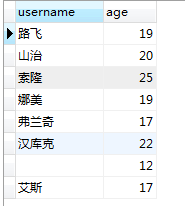
逻辑操作符:
IS NULL;
BETWEEN;
IN;
LIKE;
EXISTS;
UNIQUE;
IS NULL(与null值进行比较):
select * from users where username is null;
BETWEEN(找位于之间的记录):
select * from users where salary between 400 and 800;
IN(与指定列表比较,这个指定列表也可以是查询结果,这里这给出简单的列表):
select * from users where id in(1,4,8)
还可以是 select * from users where id in(这里面也是个select语句);
LIKE(多用于模糊查询):通配符有两个,“%””_”
where salary like ‘200%’ : 以200开头的值
where salary like ‘%200%’ :包含200的
where salary like ‘2_%_%’ :以2开头,长度至少为三的值
where salary like ‘_00%’ :第二和第三个字符是0的值
where salary like ‘%2’ :以2结尾的值
where salary like ‘_2%3’ :第二位为2,结尾为3的值
where salary like ‘2___3’ :以2开头,结尾为3,长度为五的值
select * from users where salary like '200%'
EXIST(用于指定表里是否存在特定条件的记录,与IN很像,只是这个子查询里的表是能查自己的表,IN是不能的):这个东西有够狗血的,exist子句并不返回数据,返回的是true,false,然后进行外部的主查询。
select * from users where exists (select * from users where id<5)
这条语句表达的意思是如果users表里有id<5的记录就进行外部的主查询,返回表中所有数据,注意并不是只返回id<5的数据(我扣了半天才发现)。
ALL,SOME,ANY(感觉没什么卵用,不给例子了,用到的时候再查好了)
AND OR :
select * from users where id>1 and id<5;
select * from users where id=1 or id>10;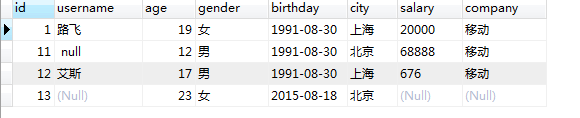
求反操作符:这些就不说了,没几个意思
<>,!=
NOT BETWEEN
NOT IN
NOT LIKE
IS NOT NULL
NOT EXISTS
NOT UNIQUE
算术操作符: 就+ - * / ;不说了。
查询汇总: COUNT , SUM , AVG ,MAX, MIN
COUNT:前面用过了
SUM: SUM([DISTINCT] COULUMN NAME)distinct会丢弃重复的数据进行计算。
select SUM(age) from users结果为391
select SUM(distinct age) from users结果为355,小于391,因为我表中有重复的年龄被丢弃了。
AVG(平均数):
select AVG(age) from users MAX(最大值):
select MAX(age) from users MIN(最小值):
select MIN(age) from users 数据排序与数组:
GROUP BY (select中出现的字段,除汇总函数外,全部要在group by 中出现,书上是这么说的,但我用mysql试了下,不在也可以–!)
ORDER BY
select username,city,age,count(*) from users group by city order by count(*)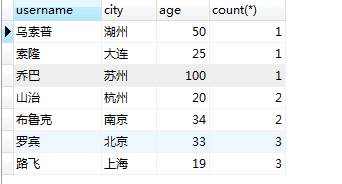
其实这个查询是有问题的,弗兰奇也是在南京的,但被覆盖了。
HAVING(相当于再加一个条件,HAVING对GROUP BY 的作用就相当于WHERE 对 SELECT的作用)
select username,city,age,count(*) from users group by city having age >20 order by count(*)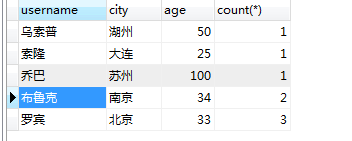
相对于上条查询19岁的路飞君已经被踢掉了。
到这里,基本的语句已经差不多了,后面还有的子查询,关联查询,组合查询,存储过程,事件,外键关联什么的,就下次再说吧。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









