







初次写爬虫,拿很简单的自己的csdn主页来练习一下:
打开自己的主页查看源码,发现此部分信息在标签<divclass="result"></div>
很简单的程序出了点错,发现是编码问题,记录一下
(1)出现urllib2.HTTPError: HTTP Error 403: Forbidden错误
由于网站禁止爬虫,可以在请求加上头信息,伪装成浏览器访问
(2)统一编码,匹配的字符和要查找的字符编码要统一,尤其是中文要转换为unicode
Python中的字符串有两种数据类型:str类型和unicode类型。str类型采用的ASCII编码,也就是说它无法表示中文。unicode类型采用unicode编码,能够表示任意的字符,包括中文、日文、韩文等。在python中字符串默认采用的ASCII编码,如果要显示声明为unicode类型的话,需要在字符串前面加上'u'或者'U'。
如果用中文去查找,字符串前面要加ur
(3)注意不管是search还是findall来进行匹配时,后面添加re.S,可以匹配换行符,要不然查询不到结果
其他的备选
- re.I(全拼:IGNORECASE): 忽略大小写
- re.M(全拼:MULTILINE): 多行模式,改变'^'和'$'的行为
- re.S(全拼:DOTALL): 点任意匹配模式,改变'.'的行为
- re.L(全拼:LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
- re.U(全拼:UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
- re.X(全拼:VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
此外注意查看python手册,如果预编译用再进行查询,flag 在compile参数中
pattern = re.compile(xxx,re.S)
pattern.search() //此处的search没有flag
# <!-*- coding:utf-8 -*->
import urllib2
import urllib
import re
from time import ctime
'''需要从<div class="result"></div>中取出下列信息
积分:<span>560</span> 排名:第<span>24195</span>名 访问:<span>5995</span>次
'''
headers = {'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
myCsdnUrl = u'http://my.csdn.net/kuaile123'
try :
myRequest = urllib2.Request(url=myCsdnUrl,headers=headers)
myResponse = urllib2.urlopen(myRequest)
myPage = myResponse.read()
unicodePage = myPage.decode("utf-8")
myInfo = re.search(r'<div class="result">.*?</div>',unicodePage,re.S)
if myInfo is not None:
strInfo = myInfo.group()
rankInfo = re.search(ur'积分:<span>(\d+?)</span> 排名:第<span>(\d+?)</span>名 访问:<span>(\d+?)</span>次',strInfo)
if rankInfo is not None:
print u'时间: ', ctime()
print u'积分: ' , rankInfo.group(1)
print u'排名: ' , rankInfo.group(2)
print u'访问量: ' , rankInfo.group(3)
except Exception,e:
print e
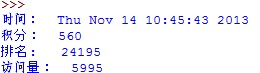
运行结果如下:















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









