







背景
好久没有更新了,原因是公司项目上线,差点被祭天。在这种惊心动魄的时候还是要抽时间做一点自己喜欢做的事情的,然而进度比预期慢了许多。
正式开始
接下来就开始记录最近的学习成果啦!
在Hadoop集群中,网络资源是非常珍贵的。因此对文件进行压缩是非常必要的,除此之外。压缩文件的另一个好处就是可以节省磁盘空间。
压缩方法介绍
我们在对文件进行压缩时,要仔细考虑使用哪种压缩方法最合适。常见的压缩格式有
表5-1
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否包含多个文件 | 是否可切分 |
|---|---|---|---|---|---|
| DEFLATE | N/A | DEFLATE | .deflate | 否 | 否 |
| Gzip | gzip | DEFLATE | .gz | 否 | 否 |
| bzip2 | bzip2 | bzip2 | .bz2 | 否 | 是 |
| LZO | Lzop | LZO | .lzo | 否 | 否 |
相比较之下,bzip2比gzip更高效,但压缩速度要慢一些。LZO压缩速度比gzip更快,但效率不高。
在Hadoop中,一个对CompressionCodec接口的实现代表一个codec。例如,GzipCodec包装了gzip的压缩和解压缩方法。(实际上每个Codec都包含了这两个方法)
我们可以利用CompressionCodec中的方法对数据进行压缩和解压。
上表中“是否可切分”一列,表示压缩算法是否支持切分。可切分的压缩格式更加适合MapReduce。gzip格式使用DEFLATE来存储压缩过的数据,DEFLATE将数据作为一系列压缩过的块进行存储。问题是,每块的开始没有指定用户在数据流中任意点定位到下一个块的起始位置,而是其自身与数据流同步。因此,gzip并不支持文件切分。但是,bzip2文件提供不同数据块之间的同步标识,因而它是支持切分的。
在MapReduce中使用压缩
主要代码
这里举一个查询每年最高气温的例子,对输出数据进行压缩。
Map
public class MaxTemperatureMapper extends MapReduceBase
implements Mapper<LongWritable, Text, Text, IntWritable>{
private static final int MISSING = 9999;
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String data = value.toString();
String year = "";
int airTemperature = 0;
if(data != null && data.length() > 0) {
String[] temp = data.split(",");
year = temp[0];
airTemperature = Integer.parseInt(temp[1]);
}
output.collect(new Text(year),new IntWritable(airTemperature));
}
}Reduce
public class MaxTemperatureReducer extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable>{
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int maxValue = Integer.MIN_VALUE;
while (values.hasNext()) {
maxValue = Math.max(maxValue, values.next().get());
}
output.collect(key, new IntWritable((maxValue)));
}
}Compression
public class MaxTemperatureWithCompression {
public static void main(String[] args) throws IOException {
if (args.length != 2) {
System.err.println("Usage: MaxTemperatureWithCompression <input path> " +
"<output path>");
System.exit(-1);
}
JobConf conf = new JobConf(MaxTemperatureWithCompression.class);
conf.setJobName("Max temperature with output compression");
FileInputFormat.addInputPath(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setBoolean("mapred.output.compress", true);
conf.setClass("mapred.output.compression.codec", GzipCodec.class, CompressionCodec.class);
conf.setMapperClass(MaxTemperatureMapper.class);
conf.setCombinerClass(MaxTemperatureReducer.class);
conf.setReducerClass(MaxTemperatureReducer.class);
JobClient.runJob(conf);
}
}运行结果
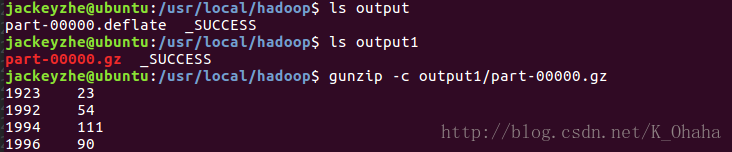
上图中,output目录下的结果为未设置要使用的压缩类,即Hadoop默认使用的是DEFLATE压缩,扩展名为.deflate。output1目录下的结果是设置使用Gzip压缩。
需要注意
验证过程中,需要注意的是,一定根据map和reduce方法的参数设置setOutputKeyClass和setOutputValueClass,否则会抛出类型转换异常,因为Hadoop默认的输出Key和Value类型分别是LongWritable和Text。
本例中map和reduce输出类型相同,如果不同,也可以单独设置中间结果的输出类型:
conf.setMapOutputKeyClass(Text.class);
conf.setMapOutputValueClass(IntWritable.class);总结
要对MapReduce进行压缩,需要把mapred.output.compress属性设置为true,另外需要设置mapred.output.compression.codec属性。如果要对map的输出结果进行压缩,则需要设置mapred.compress.map.output和mapred.map.output.compression.codec。















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









