







 本文是吴恩达Coursera深度学习课程中关于目标检测的笔记,重点介绍了目标定位、目标检测、Bounding Box预测、交并比(IoU)、非最大值抑制(NMS)和Anchor box的概念。讲解了YOLO算法如何通过卷积神经网络实现高效的目标检测,并讨论了Anchor box如何帮助检测多个对象。
本文是吴恩达Coursera深度学习课程中关于目标检测的笔记,重点介绍了目标定位、目标检测、Bounding Box预测、交并比(IoU)、非最大值抑制(NMS)和Anchor box的概念。讲解了YOLO算法如何通过卷积神经网络实现高效的目标检测,并讨论了Anchor box如何帮助检测多个对象。
作者: 大树先生
博客: http://blog.csdn.net/koala_tree
知乎:https://www.zhihu.com/people/dashuxiansheng
GitHub:https://github.com/KoalaTree
2017 年 11 月 21 日
以下为在Coursera上吴恩达老师的 DeepLearning.ai 课程项目中,第四部分《卷积神经网络》第三周课程“目标检测”关键点的笔记。本次笔记几乎涵盖了所有视频课程的内容。在阅读以下笔记的同时,强烈建议学习吴恩达老师的视频课程,视频请至 Coursera 或者 网易云课堂。
同时我在知乎上开设了关于机器学习深度学习的专栏收录下面的笔记,以方便大家在移动端的学习。欢迎关注我的知乎:大树先生。一起学习一起进步呀!_
卷积神经网络 — 目标检测
1. 目标定位和特征点检测
图片检测问题:
- 分类问题:判断图中是否为汽车;
- 目标定位:判断是否为汽车,并确定具体位置;
- 目标检测:检测不同物体并定位。

目标分类和定位:
对于目标定位问题,我们卷积神经网络模型结构可能如下:
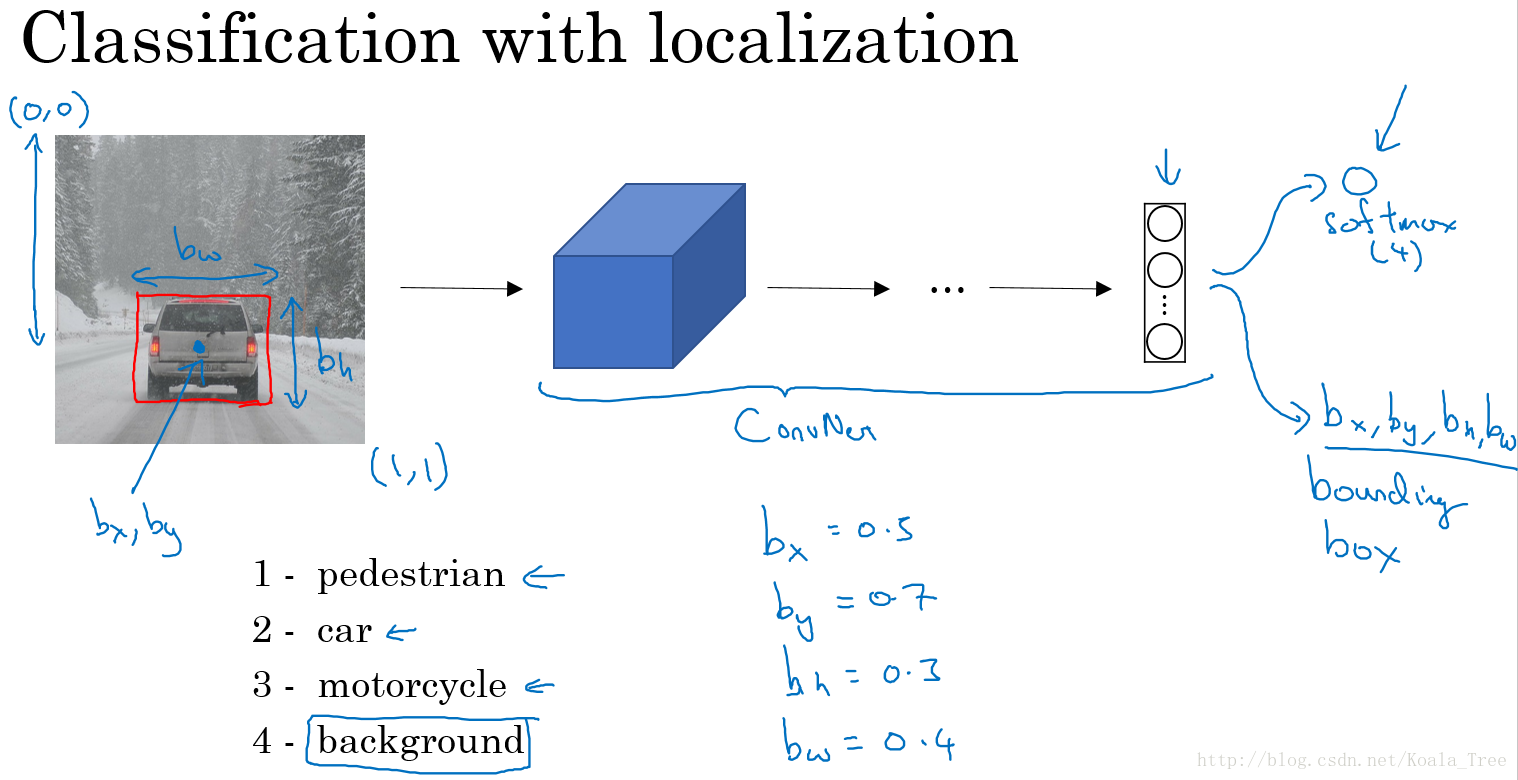
输出:包含图片中存在的对象及定位框
- 行人,0 or 1;
- 汽车,0 or 1;
- 摩托车,0 or 1;
- 图片背景,0 or 1;
- 定位框: b x 、 b y 、 b h 、 b w b_{x}、b_{y}、b_{h}、b_{w} bx、by、bh、bw
其中, b x 、 b y b_{x}、b_{y} bx、by表示汽车中点, b h 、 b w b_{h}、b_{w} bh、bw分别表示定位框的高和宽。以图片左上角为(0,0),以右下角为(1,1),这些数字均为位置或长度所在图片的比例大小。
目标标签 y:
KaTeX parse error: Undefined control sequence: \ at position 36: …ray}{l} P_{c}\\\̲ ̲b_{x}\\\ b_{y}\…
- 当 P c = 1 P_{c}=1 Pc=1时,表示图片中存在物体;
- 当 P c = 0 P_{c}=0 Pc=0时,表示图片中不存在物体,那么此时,输出 y y y的其他值为多少均没有意义,也不会参与损失函数的计算:
y = [ 0 ? ? . . . ? ] y = \left[ \begin{array}{l} 0\\ ?\\ ?\\ ...\\ ? \end{array} \right] y=⎣⎢⎢⎢⎢⎡0??...?⎦⎥⎥⎥⎥⎤
损失函数:
如果采用平方误差形式的损失函数:
- 当 P c = 1 P_{c}=1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









