







 本文介绍了如何使用朴素贝叶斯方法构建一个垃圾邮件分类器。通过贝叶斯假设和拉普拉斯平滑解决参数估计问题,讲解了在遇到未见过的单词时如何进行概率修正,以及朴素贝叶斯分类器的Python实现。
本文介绍了如何使用朴素贝叶斯方法构建一个垃圾邮件分类器。通过贝叶斯假设和拉普拉斯平滑解决参数估计问题,讲解了在遇到未见过的单词时如何进行概率修正,以及朴素贝叶斯分类器的Python实现。
问题引入
考虑构建一个垃圾邮件分类器,通过给定的垃圾邮件和非垃圾邮件的数据集,通过机器学习构建一个预测一个新的邮件是否是垃圾邮件的分类器。邮件分类器是通常的文本分类器中的一种。
朴素贝叶斯方法
贝叶斯假设
假设当前我们已经拥有了一批标识有是垃圾邮件还是非垃圾邮件的数据集,然后我们来构建一个分类器。
我们可以通过一个特征向量来表示一封邮件,向量的维度就是字典中单词的个数。如果字典中的第i个单词包含在邮件中,那个这个向量的 xi=1 ,否则 xi=0 。假设字典中单词个数为50000,那么如下向量
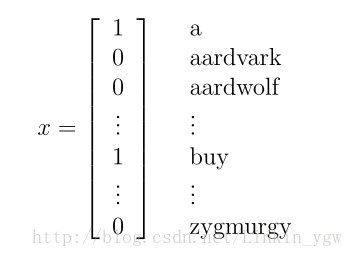
表示邮件中存在单词a,buy,而aardvark,aardwolf和zygmurgy不存在。从这里可以看到,向量的维度为字典单词的个数,这里为50000。
有了特征向量,我们来构建模型,实际上,我们需要构建的就是这样一个条件概率模型 p(x|y) ,这里字典的大小为50000,那么 x∈{ 0,1}50000 ,显然这种指数级的参数来估计是不可行的。若要构建 p(x|y) ,我们必须要做一些假设条件,我们假设每个 xi 针对给定的y具有条件独立性,这就是朴素贝叶斯假设。在这个假设条件下,例如在给定 y=1 的条件下 x200 与 x5 相互独立,即 p(x200|y)=p(x5|y,x200) ,这里需要注意的是不是假设 x200 和 x5 相互独立,而是在给定y的条件下相互独立。
朴素贝叶斯方法
有了以上的朴素贝叶斯假设,那我们可以构建我们的模型 p(x|y) ,
===p(x1,x2,x3...x50000|y)p(x1|y)p(x2|y,x1)p(x3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 200
200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









