







第一次接触BP神经网络是在模式分类的课上,第二次接触是在Stanford的机器学习课上。接触多次,但都没有具体把它应用到研究中去。这次要做学术报告,打算试验一下它在分类识别中的效果如何,也逼自己具体代码实现一遍。 2013-12-20
BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层、隐层和输出层。
前言
人工神经网络(artificial neural network,ANN),简称神经网络(neural network,NN),是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具,常用来对输入和输出间复杂的关系进行建模,或用来探索数据的模式。
神经网络是一种运算模型,由大量的节点(或称“神经元”)和之间相互的联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的联接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
它的构筑理念是受到生物(人或其他动物)神经网络功能的运作启发而产生的。人工神经网络通常是通过一个基于数学统计学类型的学习方法得以优化,所以人工神经网络也是数学统计学方法的一种实际应用,通过统计学的标准数学方法我们能够得到大量的可以用函数来表达的局部结构空间,另一方面在人工智能学的人工感知领域,我们通过数学统计学的应用可以来做人工感知方面的决定问题(也就是说通过统计学的方法,人工神经网络能够类似人一样具有简单的决定能力和简单的判断能力),这种方法比起正式的逻辑学推理演算更具有优势。神经元
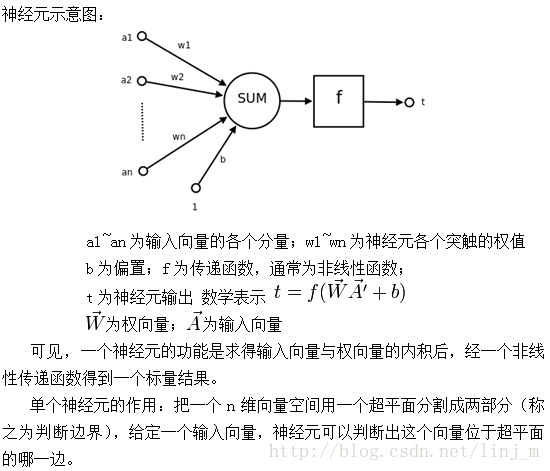
BP神经网络详解
BP神经网络是有指导训练的前馈多层网络训练算法,是靠调节各层的加权,使网络学会由输入输出对组成的训练组。类似于感知器中线性单元和非线性单元的训练算法,执行优化的基本方法仍是梯度下降法。BP算法是使用非常广泛的一种算法,最常用的转移函数是Sigmoid函数。
符号描述
训练组输入输出对:{xik,Tjk}
输出结点的输出: yjk
隐蔽层结点的输出: yhk
输入信号: xik
由输入层结点至隐蔽层结点的加权表示:Wih
由隐蔽层结点至输出层结点的加权表示: Whj
下标i、h、j分别表示某一输入结点、隐蔽层结点和输出结点,上标k表示训练对的序号,k=1,2,…,P。
xik既可以是二进制值,也可以是连续值。
输入端点数目为N。
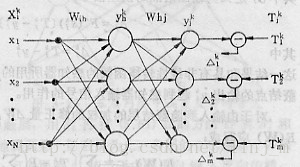
BP算法推算过程


BP训练算法实现步骤

BP的讨论
网络层次的选择:
对多层网络要确定选用几个隐蔽层。
◆Heche-Nielsen证明,当各结点具有不同的阈值时,具有一个隐蔽层的网络可以表示其输入的任意函数,但由于该条件很难满足,该结论意义不大。
◆Cybenko指出,当各结点均采用S型函数时,一个隐蔽层就足以实现任意判决分类问题,两个隐蔽层则足以实现输入向量的任意输出函数。
◆网络层次的选取依经验和情况而定,通常不宜过多。
层内结点数的确定:
◆BP网络中各层结点数的选择对网络的性能影响很大。
◆对输出结点,它取决于输出的表示方法和要识别(或分类)的输入向量的类别数目。
→比如要输出能表示8个不同向量的分类,可以用8个输出结点,一个结点表示一类,也可以采用三个输出结点,用它们的二进制编码表示8个不同的分类。
→如果用了编码方式,会减少输出结点的数量,但会增加隐蔽层的附加工作以完成编码功能,甚至有时需增加一个隐蔽层以满足要求。
◆对输入结点,输入层的结点数通常应等于输入向量的分量数目。
◆对隐蔽层结点数的选择,Nielson等指出:
除了图像情况,在大多数情况下,可使用4-5个隐蔽层结点对应一个输入结点。
在图像情况下,像素的数目决定了输入结点的数目,此时隐蔽层结点可取输入结点数的10%左右。
隐蔽层的结点数取得太少,网络将不能建立复杂的判决界面;取得太多,会使得判决界面仅包封了训练点而失去了概括推断的能力。
隐蔽层结点数的选择要根据实际情况和经验来定。
BP训练算法存在的问题
尽管BP训练算法应用得很广泛,但其训练过程存在不确定性。
◆完全不能训练
网络的麻痹现象
局部最小
◆训练时间过长,尤其对复杂问题需要很长时间训练。
选取了不适当的调节阶距(训练速率系数η)。
网络的麻痹现象
在训练过程中(如采用Sigmoid函数),加权调得较大可能迫使所有的或大部分的加权和输出sj较大,从而使得操作会在S型函数的饱和区进行,此时函数处在其导数F’(s)非常小的区域内。
由于在计算加权修正量时,σ正比于F’(s),因此当F’(s)->0时σ->0,这使得,相当于调节过程几乎停顿下来。
局部最小
BP训练算法实际上采用梯度下降法,训练过程从某一起始点沿误差函数的斜面最陡方向逐渐达到最小点E->0。
对于复杂的网络,其误差函数面在多维空间,其表面可能凹凸不平,因而在训练过程中可能会陷入某一个小谷区,称之为局部最小点。
由此点向各方向变化均使E增加,以致无法逃出这个局部最小点。
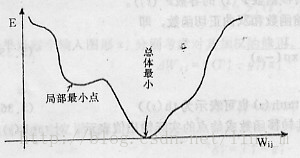
初始随机加权的大小对局部最小的影响很大。如果这些加权太大,可能一开始就使网络处于S型函数的饱和区,系统就很有可能陷入局部最小。
一般来说,要避免局部最小点可采用统计训练的方法。
→随机神经网络
阶距(训练速率系数η)大小
如果η选得太小,收敛会很慢;
如果η选得太大,可能出现连续不稳定现象。
需按照实验和经验确定η。
可取η值为0.01~1
Wasserman曾提出自适应的阶距算法,在训练过程中自动调节阶距的大小。

本文地址:http://blog.csdn.net/linj_m/article/details/9897839
更多资源请关注 博客:LinJM-机器视觉 微博:林建民-机器视觉














 2599
2599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









