








 超级会员免费看
超级会员免费看

 本文记录了作者初次尝试Python爬虫的经历,通过使用urllib和re模块抓取并解析网页,提取图片URL,进而下载图片。作者强调了正则表达式在匹配图片链接中的作用,并反思了代码组织的不足,表达了对Python编程和爬虫技术的初步认识及学习的乐趣。
本文记录了作者初次尝试Python爬虫的经历,通过使用urllib和re模块抓取并解析网页,提取图片URL,进而下载图片。作者强调了正则表达式在匹配图片链接中的作用,并反思了代码组织的不足,表达了对Python编程和爬虫技术的初步认识及学习的乐趣。
这两天看了看Python的一些语法,发现Python还真的是给力呢。先不说它强大的类库,面向对象或者其他的好处,单单是爬图这一块,就已经深深的吸引到了我,于是在我的摸索之下,人生中的第一次爬虫出现了。之所以写这篇文章,是因为想以此来纪念一下。等今后技术上进步了,回过头来看看自己走过的点点滴滴,出现的这诸多的问题,想必也是一种不错的体验吧。
好了,废话不多说。
目标网址
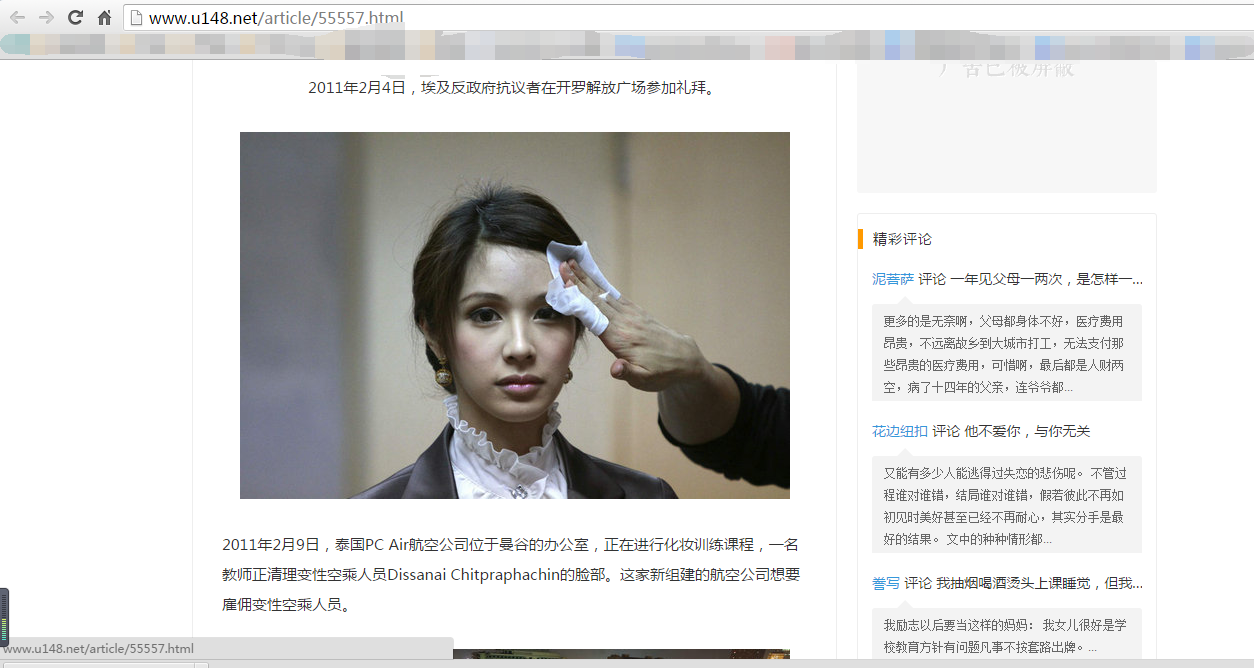
我的思路
思路上来说,很普通。
- 先利用urllib把对应的网页给抓下来
- 然后对网页进行解析,这里使用了re模块来进行正则表达式的匹配,我们需要的就是img标签而已
- 再次的使用urllib将图片对应的那个url给download下来
- 最后写入一张张图片
- 至此,完结
细节上的实现
首先是一个下载网页的过程,这里我将其封装到了一个函数中
def getHtml(url):
reload(sys)
return urllib.urlopen(url).read()然后是写入一个图片文件的过程,依然封装起来,如下:
def writeToFile(path,name,data):
file = open(path+name,'wb')
file.write(data)
file.close()
print name+" has been Writed Succeed!"最为关键的就是使用正则表达式来匹配我需要的东西–图片,正则表达式的话,我们可以这么干,这里仅仅是针对于这篇。我们可以使用开发者工具看到如下:
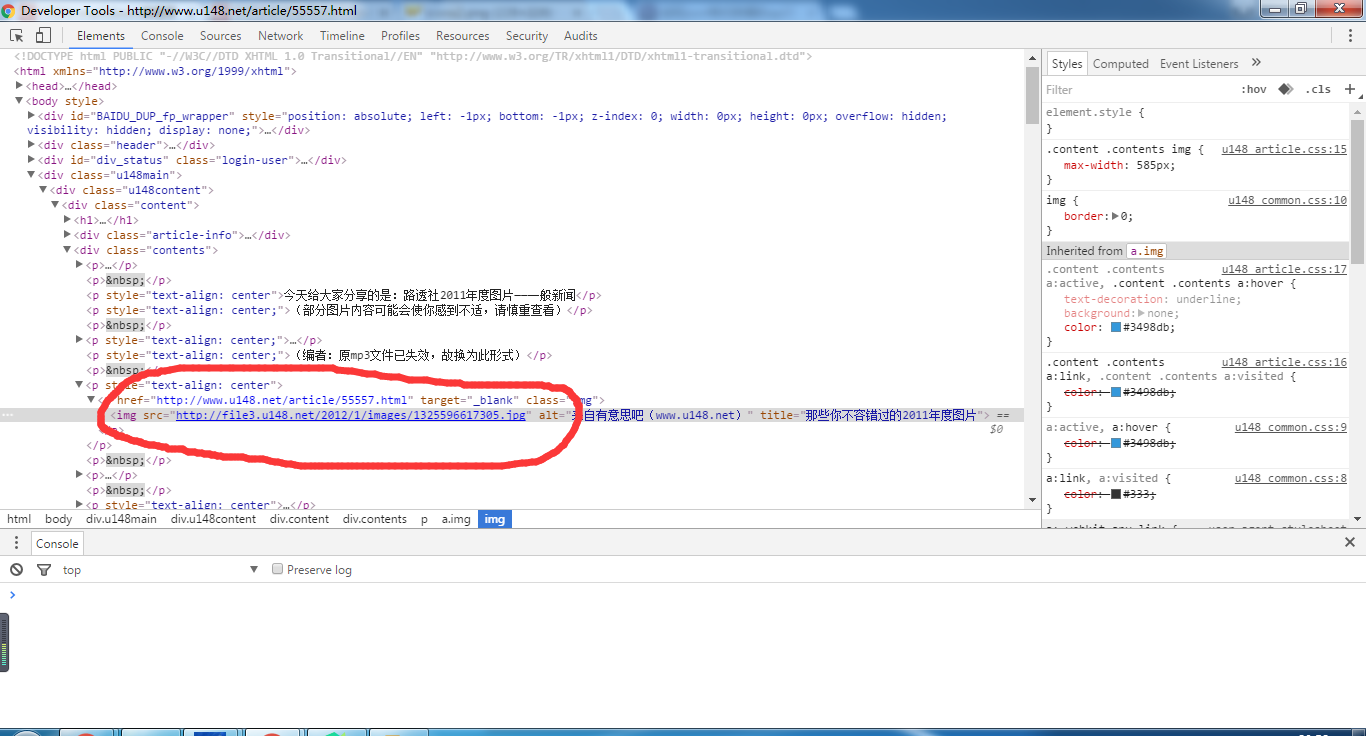
正则表达式为r'src=(.+?\.jpg)'
下面我来详细的说明一下各个参数的含义:
- r’ : 即可以忽略转义的影响,如果不写这个的话,我们需要对右斜线进行转义”\\”
- src=”” : 这里就是一个匹配格式,就是包含有src=”“开头的数据
- () : 匹配完成后返回的将是一个list,方便我们进行数据的提取
- .+?.jpg : 就是匹配任意多个以
.jpg结尾的数据,这里就是我们的图片了
好了,该做的都做好了,下面让我们看一看完整的代码吧
完整的代码
# coding:UTF-8
import urllib
import sys
import re
import os
def getHtml(url):
reload(sys)
return urllib.urlopen(url).read()
def writeToFile(path,name,data):
file = open(path+name,'wb')
file.write(data)
file.close()
print name+" has been Writed Succeed!"
#url = "http://www.10danteng.com/index/pages/id/11036/"
url = 'http://www.u148.net/article/55557.html'
page = getHtml(url)
reg =re.compile(str( r'src="(.+?\.jpg)"'))
images_url = re.findall(reg,page)
# 测试一下网址是否可达
#print images_url
# 测试一下网页是否正确的下载到了内容
#print content
name = 'me'
path = "F:\\pachong\\"
#writeToFile(path,str(name)+".jpg",content)
for i, item in enumerate(images_url):
everypicture = getHtml(item)
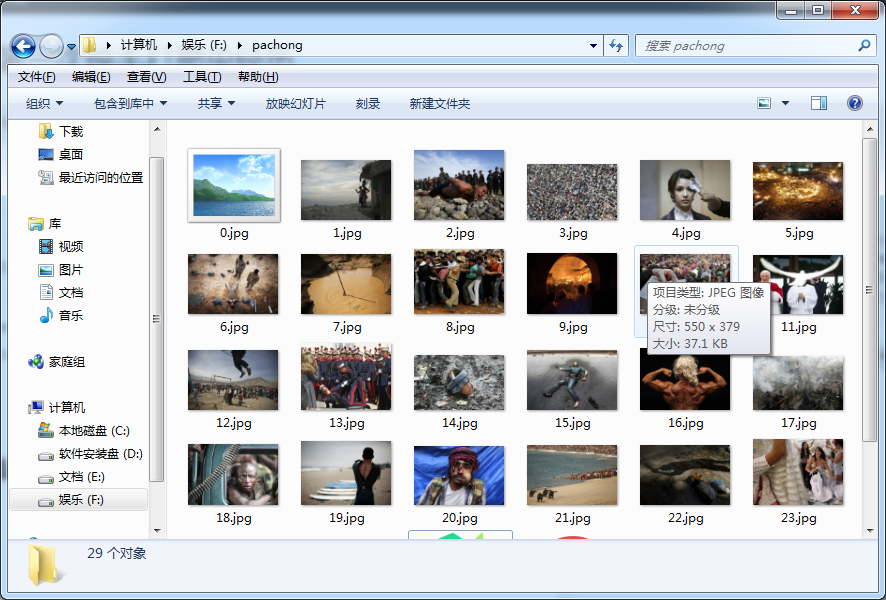
writeToFile(path,str(i)+".jpg",everypicture)最后看一下,爬到了什么
总结
代码还是很凌乱的,我应该把那个正则匹配的也封装起来的。这样方便代码的维护和减少重复代码。
通过这次的小案例,我学会了一些简单模块的使用,同时也对于Python有了一点入门的感觉了。Python就是一个人思想的代表。只要逻辑对了,顺着思路一步步的往下走。就一定可以成功完成的。另外,那就是遇到错误,不要放弃。要从错误中寻找解决的方法。
如果,你认为代码中有什么不正确的地方,或者想和本人探讨一下关于爬虫方面的问题,欢迎留言哦。
















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











