







一:软件的准备
本文搭建hadoop的软件使用清单如下:
ubuntu14.04
VMware
hadoop-2.6.4
jdk1.7.0
securitycrt(可以不使用)
二:在windows下操作linux系统的配置
在执行接下来的步骤前,必须要在vmware中安装好Ubuntu系统,否则不可继续如下步骤:
为了方便同时使用linux和windows系统,使用了securitycrt来远程控制虚拟机,首先下载一个破解版的securitycrt之后就可以连接 虚拟机了.
步骤如下:
1:在Ubuntu下
(1)输入sudo apt-get install openssh-server安装远程ssh服务(若没有ssh,首先要执行sudo apt-get install ssh)

(2)输入ifconfig来查看本机的ip地址

2:打开securitycrt
新建一个快速连接,输入要连接的主机的ip,协议选择ssh2,端口号为22,点击连接后输入密码即可

三:单机模式的环境搭建
1:Ubuntu系统下载并安装jdk
1.1将文件复制到虚拟机中的Downloads中

1.2输入命令进行解压到usr/local中
huang@ubuntu:~$ sudo tar -zxf ~/Downloads/jdk-7u79-linux-x64.gz -C /usr/local
2:配置jdk的环境变量
输入sudo vim /etc/profile,在这里修改的是所有用户的环境变量
huang@ubuntu:~$ sudo vim /etc/profile
在末尾添加几行代
##javaexport JAVA_HOME=/usr/local/jdk1.7.0_79export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATHexport PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PAT
重新启动电脑,输入验证java环境变量配置
huang@ubuntu:~$ java -version

说明环境变量配置正确
3:下载hadoop并配置
下载hadoop地址为:
http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz存放到downloads中
将文件解压到usr/local中
huang@ubuntu:~$ sudo tar -zxf ~/Downloads/hadoop-2.6.4.tar.gz -C /usr/local
配置hadoop环境变量:
huang@ubuntu:~$ sudo vim /etc/profile
加入如下代码:
##hadoopexport HADOOP_HOME=/usr/local/hadoop-2.6.4export PATH=$PATH:/usr/local/hadoop-2.6.4/bin
重新启动ubuntu使得环境变量生效
输入命令,
验证hadoop环境变量
huang@ubuntu:~$ hadoop
出现信息则表示环境变量配置正确
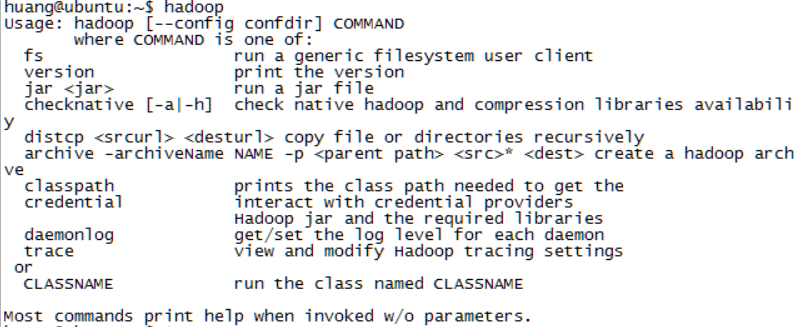
配置hadoop中的jdk路径;
进入目录
huang@ubuntu:~$ cd /usr/local/hadoop-2.6.4/etc/hadoop
编辑当中的hadoop-env.sh目录
huang@ubuntu:~$ sudo vim hadoop - env . sh
找到JAVA_HOME的字样,将其修改为自己的jdk路径
# The java implementation to use.export JAVA_HOME=/usr/local/jdk1.7.0_79
单机模式到此配置完成
单机模式
测试:
huang@ubuntu:~$ cd /usr/local/hadoop-2.6.4 #进入目录中huang@ubuntu:/usr/local/hadoop-2.6.4$ sudo mkdir input #创建input目录huang@ubuntu:/usr/local/hadoop-2.6.4$ sudo cp ./etc/hadoop/*.xml ./input #将/etc/hadoop/中所有xml文件放进input目录中huang@ubuntu:/usr/local/hadoop-2.6.4$ sudo ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'huang@ubuntu:/usr/local/hadoop-2.6.4$ cat ./output/* #查看结果
四:伪分布式的配置
1:配置ssh免密码登录
由于不同计算机间通信需要一个认证过程,配置ssh免密码登录,可以方便计算机间的相互通信,不必每次通信都进行输入密钥进行认证
生成钥匙:
huang@ubuntu:~$ ssh-keygen -t rsa
输入后不断按enter即可,最后显示

将公钥文件复制并重命名为authorized_keys
huang@ubuntu:~/.ssh$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
修改公钥文件的用户权限
huang@ubuntu:~/.ssh$ chmod 644 authorized_keys
输入ssh localhost查看是否需要输入密码

2:配置hadoop文件
进入目录
huang@ubuntu:~$ cd /usr/local/hadoop-2.6.4/etc/hadoop
编辑core-site.xml文件
sudo vim core-site.xml
修改为如下内容:(这里是设置主机名称和地址和tmp目录的位置)
<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop-2.6.4/tmp</value><description>Abase for other temporary directories.</description></property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>
编辑hdfs-site.xml文件
sudo vim hdfs-site.xml
修改为如下内容
(设置副本数量,伪分布为1,并设置datanode和namenode的目录路)
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop-2.6.4/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop-2.6.4/tmp/dfs/data</value></property></configuration>
修改成功后就要格式化文件系统
回到hadoop目录下执行:
bin/hadoop namenode -format
开启所有守护进程
./sbin/start-all.sh

如果开启失败(显示没有创建文件的权限),则需要修改hadoop文件权限
chmod 744 hadoop-2.6.4
最后使用jps命令查看守护进程
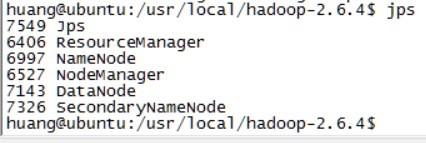
出现namenode,datanode和secondarynamenode则说明成功
到此,伪分布模式配置完成!















 1366
1366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









