







首先我们详细说明一下问题:问题的输入是一列整数,其中每个整数都表示一个某种类型的对象,一对整数p,q可以被理解为“p和q是相连的”。我们假设相连是一种等价关系,意味着:
(1)自反性,p和q是相连的
(2)对称性,如果 p和q是相连的,那么q和p是相连的
(3)传递性,如果 p和q是相连的,q与r是相连的,那么r和p是相连的
本文主要介绍解决动态连通性一类问题的一种算法,使用到了一种叫做并查集的数据结构,称为Union-Find。更多的信息可以参考Algorithms 一书的Section 1.5,实际上本文也就是基于它的一篇读后感吧。原文中更多的是给出一些结论,我尝试给出一些思路上的过程,即为什么要使用这个方法,而不是别的什么方法。我觉得这个可能更加有意义一些,相比于记下一些结论。
关于动态连通性
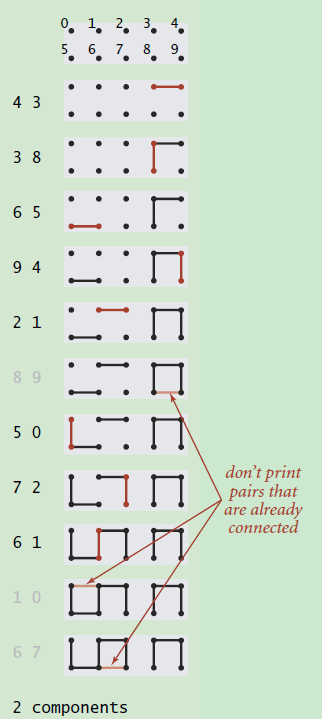
假设我们输入了一组整数对,即上图中的(4, 3) (3, 8)等等,每对整数代表这两个points/sites是连通的。那么随着数据的不断输入,整个图的连通性也会发生变化,从上图中可以很清晰的发现这一点。同时,对于已经处于连通状态的points/sites,直接忽略,比如上图中的(8, 9)。
应用
(1)网络连接判断:
如果每个pair中的两个整数分别代表一个网络节点,那么该pair就是用来表示这两个节点是需要连通的。那么为所有的pairs建立了动态连通图后,就能够尽可能少的减少布线的需要,因为已经连通的两个节点会被直接忽略掉。
(2)变量名等同性(类似于指针的概念):
在程序中,可以声明多个引用来指向同一对象,这个时候就可以通过为程序中声明的引用和实际对象建立动态连通图来判断哪些引用实际上是指向同一对象。
for(int i = 0; i < size ; i++)
id[i] = i;建模
变量名等同性(类似于指针的概念):
在程序中,可以声明多个引用来指向同一对象,这个时候就可以通过为程序中声明的引用和实际对象建立动态连通图来判断哪些引用实际上是指向同一对象。
初始化完毕之后,对该动态连通图有几种可能的操作:
(1)查询节点属于的组
(2)数组对应位置的值即为组号
(3)判断两个节点是否属于同一个组
(4)分别得到两个节点的组号,然后判断组号是否相等
(5)连接两个节点,使之属于同一个组
(6)分别得到两个节点的组号,组号相同时操作结束,不同时,将其中的一个节点的组号换成另一个节点的组号
(7)获取组的数目
(8)初始化为节点的数目,然后每次成功连接两个节点之后,递减1
算法实现
(1)用一个数组保存着每个对象所在的connected component,这种方式可以快速进行FIND,但是在union操作时需要遍历整个对象数组
(2)利用树的观点,在数组中保存每个对象节点的parent,这个每个connected component就是一棵树,这种方式union很高效,只需要更新相应节点的parent即可,但是在find的时候可能就会遍历整个树,特别是当一棵树比较高的时候。
(3)在上述2中实现union(p,q)的时候,我们用一种特定的方式将p所在的树的置为q所在树的孩子,没有考虑到树的大小,就会导致严重失衡的情况。Weighted quick-union 引入一个新的数组来保存每棵树的尺寸,总是将小树链入到大树下,实现相对的平衡。
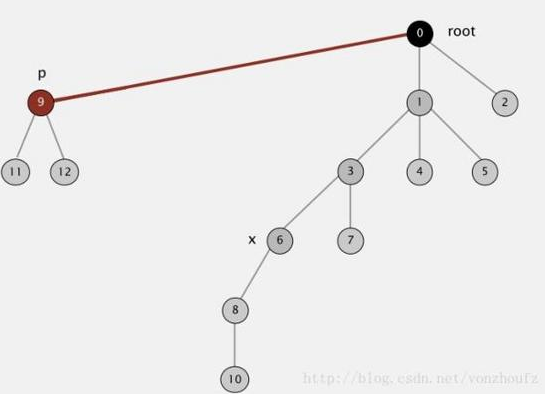
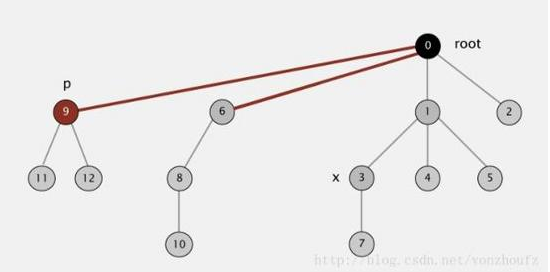
(4)利用path compression进一步对上述算法进行优化,在每一次root操作的时候,不单单只是追溯查询一个节点的根,而是动态的将其根节点往上推进。从而使得 component tree 越来越 平坦化 。 如下要查询节点6的根节点,在查询的最后会更新6直接指向根节点。
接下来会把3,1分别指针指向root
多种方法实现代码
--------1
//这种方式可以快速判断是否相连,但是union操作需要遍历整个对象数组
public class QuickFindUF {
// 这个数组保存着这个N个节点的所在分组
private int [] id ;
public QuickFindUF( int n) {
id = new int [n];
for ( int i = 0; i < n; i ++) {
id [ i ] = i ;
}
}
public boolean find( int p, int q) {
return id [p] == id [q];
}
// 连接p,q节点的时候,要将p所在component中的所有节点的id更新
public void union( int p, int q) {
int pid = id [p];
int qid = id [q];
for ( int i = 0; i < id . length ; i++) {
if ( id [i] == pid)
id [i] = qid;
}
}
}
-----------2
//这种方式可以快速实现俩个
public class QuickUnionUF {
// 这个数组保存着该对象的parent
private int [] id ;
public QuickUnionUF( int n) {
id = new int [n];
for ( int i = 0; i < n; i++) {
id [i] = i;
}
}
// 辅助函数,追溯节点的n的根
private int root( int n) {
while (n != id [n])
n = id [n];
return n;
}
public boolean find( int p, int q) {
return root(p) == root(q);
}
// 连接p,q节点的时候,要将p的parent的parent更新为q的parent
public void union( int p, int q) {
int parentp = id [p];
int parentq = id [q];
id [parentp] = parentq;
}
}
---------------3
public class WeightedQuickUnionUF {
private int [] id ; // id[i] = parent of i
private int [] sz ; // sz [i] = number of objs in subtree rooted at i
private int count ; // num of components
public WeightedQuickUnionUF( int N) {
count = N;
id = new int [N];
sz = new int [N];
for ( int i = 0; i < N; i++) {
id [i] = i;
sz [i] = 1;
}
}
public int count() {
return count ;
}
// 得到包含这个对象的component的ID,也就是根节点
public int root( int p) {
while (p != id [p])
p = id [p];
return p;
}
public boolean connected( int p, int q) {
return root(p) == root(q);
}
// 合并包含p,q的两个components,会考虑树的大小
public void union( int p, int q) {
int rootP = root(p);
int rootQ = root(q);
if (rootP == rootQ)
return ;
if ( sz [rootP] < sz [rootQ]) {
id [rootP] = rootQ;
sz [rootQ] += sz [rootP];
} else {
id [rootQ] = rootP;
sz [rootP] += sz [rootQ];
}
}
}
----------------4
public class WeightedQuickUnionWitchPathCompression {
private int [] id ; // id[i] = parent of i
private int [] sz ; // sz [i] = number of objs in subtree rooted at i
private int count ; // num of components
public WeightedQuickUnionWitchPathCompression( int N) {
count = N;
id = new int [N];
sz = new int [N];
for ( int i = 0; i < N; i++) {
id [i] = i;
sz [i] = 1;
}
}
public int count() {
return count ;
}
// path compression实现在这里。
public int root( int p) {
int root = p;
while (root != id [root])
root = id [root];
// 会将p以上的节点全部指向root
while (p != root) {
int newp = id [p];
id [p] = root;
p = newp;
}
return root;
}
public boolean connected( int p, int q) {
return root(p) == root(q);
}
// 合并包含p,q的两个components,会考虑树的大小
public void union( int p, int q) {
int rootP = root(p);
int rootQ = root(q);
if ( rootP == rootQ)
return ;
if ( sz [ rootP ] < sz [rootQ]) {
id [ rootP ] = rootQ;
sz [rootQ] += sz [ rootP ];
} else {
id [rootQ] = rootP ;
sz [ rootP ] += sz [rootQ];
}
}
}加权算法解决的极端情况:
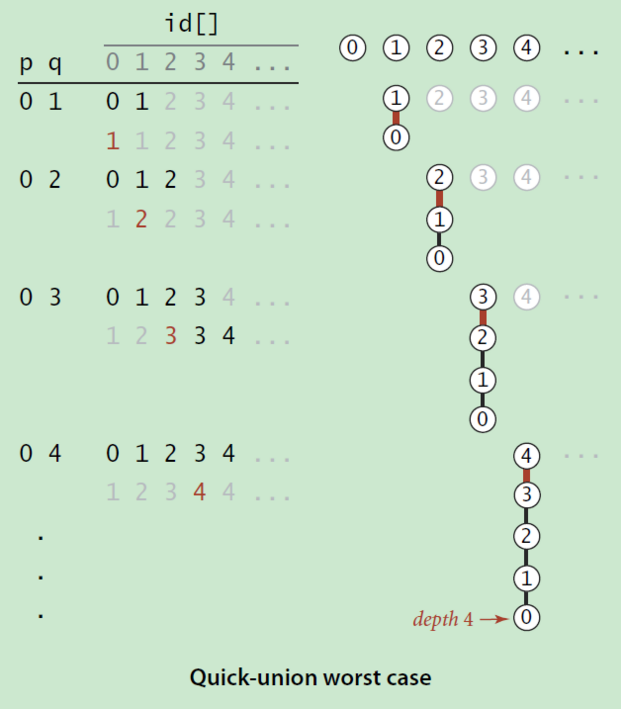
通过小树成为大树子树的方法避免上述情况的发生。
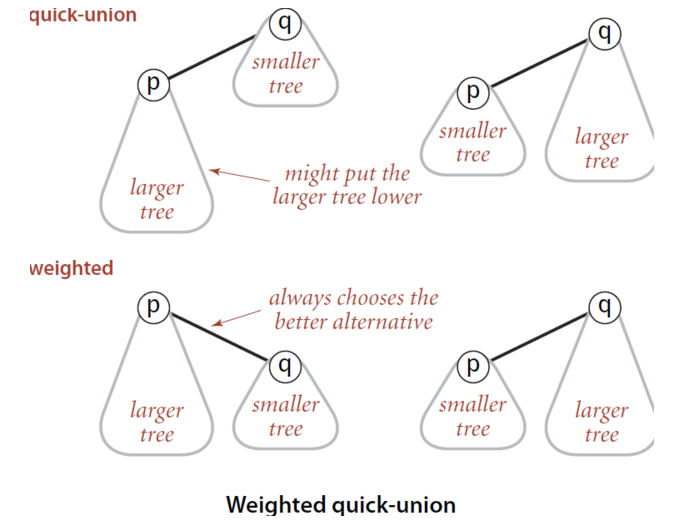
优化后的方法如图:
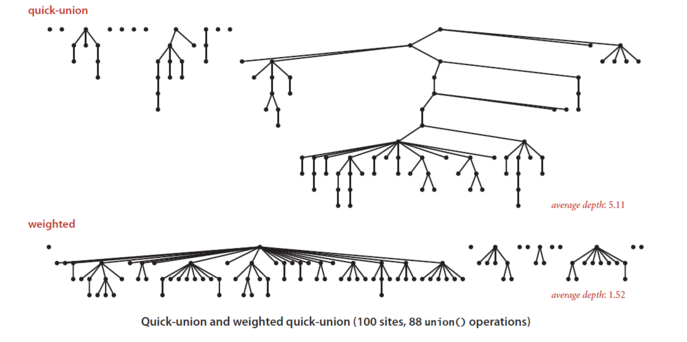
备注:可以参考《Algorithms》Fourth Edition















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









