







拦截器(比如CXF框架中的)和过滤器都是拿来做什么的???都有些什么作用???
参考链接
http://blog.csdn.net/tanggao1314/article/details/48415555CXF
框架拦截器 - 积累沉淀 - CSDN博客
CXF拦截器(Interceptor)的使用 - 熔岩 - 51CTO技术博客 http://lavasoft.blog.51cto.com/62575/167288/
目前的理解是两者都有!因为拦截器的存在就是为了扩展WS或者是CXF的功能。这种扩展总得有处理对象吧?处理的对象就是拦截器‘拦’下的,处理的动作就是由自定义的或者原生的具有一定功能的拦截器发出的。至于是扔掉还是加东西,‘服饰’之类的,就要看具体的场景了。拦截器可以说相当于是个过滤器:就是把不想要的或不想显示的内容给过滤掉。
说明:
拦截器,注意这个词的重点,是拦截!什么意思呢,如果没有它,请求就像排队的人流一样,在不设卡的条件下一股脑的往景区里冲;加上拦截器后,有两个作用,一来是验证进入景区人员的合法性(是否持有门票,是否为合法公民----》为否的自然就会被挡在门外,被拉去喝茶),二来是为了保证旅客入区的安全性(有秩序,才能有安全的保障),以更好的协调游客(客户端的请求)和景区工作人员(后台)间的关系,从另一个层面来讲,这种方式也是提升效率的方法之一!
https://zhidao.baidu.com/question/583953960492530045.html
javaweb 过滤器跟拦截器的区别和使用_百度知道
过滤器是一个程序,它先于与之相关的servlet或JSP页面运行在服务器上。过滤器可附加到一个或多个servlet或JSP页面上,并且可以检查进入这些资源的请求信息。在这之后,过滤器可以作如下的选择:
①以常规的方式调用资源(即,调用servlet或JSP页面)。
④阻止该资源调用,代之以转到其他的资源,返回一个特定的状态代码或生成替换输出。
在Servlet作为过滤器使用时,它可以对客户的请求进行处理。处理完成后,它会交给下一个过滤器处理,这样,客户的请求在过滤链里逐个处理,直到请求发送到目标为止。例如,某网站里有提交“修改的注册信息”的网页,当用户填写完修改信息并提交后,服务器在进行处理时需要做两项工作:判断客户端的会话是否有效;对提交的数据进行统一编码。这两项工作可以在由两个过滤器组成的过滤链里进行处理。当过滤器处理成功后,把提交的数据发送到最终目标;如果过滤器处理不成功,将把视图派发到指定的错误页面。(把要处理的数据用东西包装好,然后呈递给前端页面;如果包装失败,则给予其提示)
1. 拦截器是基于java的反射机制的,而过滤器是基于函数回调。
2. 拦截器不依赖与servlet容器,过滤器依赖与servlet容器。
3. 拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用。
4. 拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问。
5. 在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次(什么意思呢??由于http请求是一次性的请求(从发起请求--到返回结果结束),过滤器filter是在web.xml配置文件中设置的,当web程序部署成功后,一旦启动,这个filter就生成了。只要是在web程序的有效生命期内,这个filter都会存在,而它是在第一次时被创建的,所以就叫调用一次。而interceptor呢?它的话,因为不同的请求可能有不同的应用【比如验证啦,日志设定啦】场景,而这些拦截器又是被配置在struts.xml文件中的,相当于是web程序中的一个工具。自然就需要被多次调用!)
json类型数据和jsonp的联系和区别?
以下内容摘录,来自:
http://www.cnblogs.com/iovec/p/5312464.html#undefined
json与jsonp区别浅析(json才是目的,jsonp只是手段) - IoveC - 博客园
一言以弊之,json返回的是一串数据,而jsonp返回的则是一段脚本代码(包含一个函数调用)
json优点,xml已成前辈,同源下的前后端数据交换(嘛是同源?),
跨域请求访问资源,padding打包,json是目的&jsonp是手段,jquery已经集成了jsonp
json易于人阅读和编写,也易于机器解析和生成,相对网络传输速率较高,功能型网站前后端往往要频繁大量交换数据,而json凭借其强大的表现力和高颜值渐渐地成为理想的前后端数据交换语言。那xml前辈呢,我觉得应该会像微软的xp那样功成身退。
同源(也就是同一个资源页面里),前后端的数据交互格式自然就用的是json了。那跨域呢??就得用上jsonp了!~
当浏览器的百度tab页执行一个脚本的时候会检查这个脚本是属于哪个页面的,
jsonp原理是这样的,网站A需要获取网站B的数据,网站B说我给你们一个方法,【1. 你们使用<script src="http://www.B.com/open.js"></script>标签先获取到open.js文件(网站B的责任),这里边有你们需要的数据。2. 你们获取数据后处理数据(总得处理数据吧)的方法名必须命名为foo(数据请求者的责任和义务)】,这里相当于B网站和请求获取数据者之间建立了一个协议,要求请求者务必按照规则办事,如果请求者不能同时遵守上面两条就不能按预期获取数据。额..,这也算相当于建立了一个潜规则吧
jsonp全名叫做json with padding,很形象,就是把json对象用符合js语法的形式包裹起来以使其它网站可以请求得到,也就是将json数据封装成js文件;
json是理想的数据交换格式,但没办法跨域直接获取,于是就将json包裹(padding)在一个合法的js语句中作为js文件传过去。这就是json和jsonp的区别,json是想要的东西,jsonp是达到这个目的而普遍采用的一种方法,当然最终获得和处理的还是json。所以说json是目的,jsonp只是手段。json总会用到,而jsonp只有在跨域获取数据才会用到。
url:"http://www.B.com/open.php?callback=?",
javascript三种创建对象的方式 - dongjc - 博客园
http://www.cnblogs.com/dongjc/p/5179561.html
方法:将成员信息写到{}中,并赋值给一个变量,此时这个变量就是一个对象。
var person = (name:'dongjc', work:function() {console.log('write coding')});
<scripttype="text/javascript">
Introduce: function () { alert("Myname is " + this.name + ".I'm " + this.age); }
person.worker = 'coding'; //丰富成员信息
这与通过类创建对象有本质的区别。通过该方法创建对象时,会自动执行该函数。这点类似于php通过创建对像时,会自动调用构造函数,因此该方法称为通过"构造函数“方式创建对象。
<scripttype="text/javascript">
this.name = "dongjc"; //通过this关键字设置默认成员
var worker = 'coding'; //没有this关键字,对象创建后,该变量为非成员
this.Introduce = function () {
alert("My name is " + this.name +".I'm " + this.age);
alert("My name is " + this.name +".I'm " + this.age);
此代码一共会两次跳出对话框,原因在于创建对象是自动执行了该函数。
this关键字的使用。这里的this与php中的语法有意思类似,指调用该函数的对象,这里指的是person。
方法:先通过object构造器new一个对象,再往里丰富成员信息。
<scripttype="text/javascript">
person.Introduce = function() {
alert("My name is " +this.name + ".I'm " + this.age);
在CXF框架下的WebSerivce中,SOAP是什么?RESTful风格下的访问请求有哪些,分别都是什么意思呢?
关于SOAP
SOAP是web service的标准通信协议,SOAP为simple object access protocoll的缩写,简单对象访问协议. 它是一种标准化的传输消息的XML消息格式。
WSDL的全称是web serviceDescription Language,是一种基于XML格式的关于web服务的描述语言。其主要目的在于web service的提供者将自己的web服务的所有相关内容,如所提供的服务的传输方式,服务方法接口,接口参数,服务路径等,生成相应的完全文档,发布给使用者。使用者可以通过这个WSDL文档,创建相应的SOAP请求消息,通过HTTP传递给webservice提供者;web服务在完成服务请求后,将SOAP返回消息传回请求者,服务请求者再根据WSDL文档将SOAP返回消息解析成自己能够理解的内容。
关于RESTful风格接口请求方式的含义解释
[译]RESTful中不同HTTP请求类型的含义 - 简书
http://www.jianshu.com/p/55a8105bb014
从服务器取回数据(只是取回数据,而不会产生其他的影响)。这是一个幂等的方法(译者注:使用相同的参数重复执行,应该能够获取到相同的结果)。
POST请求通常用来创建一个实体,也就是一个没有ID的资源。一旦这个请求成功执行了,就会在HTTP请求的响应中,返回这个新创建的实体的id。
PUT请求和POST请求类似,但是一般用来更新一个已有的实体。通过把已经存在的资源的ID和新的实体用PUT请求上传的服务器,来更新资源。
DELETE方法用来从服务器上删除资源。和PUT类似,你需要把要删除的资源的ID上传给服务器。
OPTIONS方法允许客户端请求一个服务所支持的请求方法。它所对应的响应头(response header)是Allow, 它非常简单地列出了支持的方法。
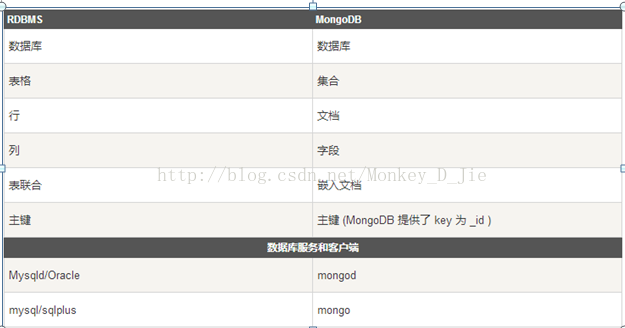
初识MongoDB
参考内容来自网络
MongoDB和数据库的对应关系
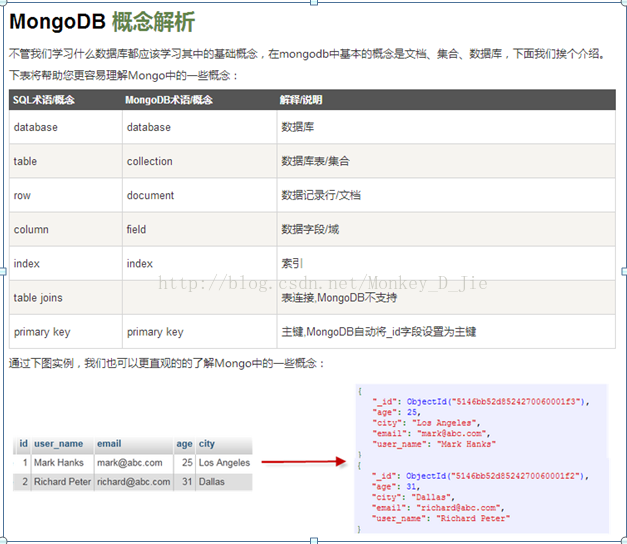
2. 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
5. 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
自定义标签库taglib的定义及其使用方法
jsp中的taglib - 大大 - CSDN博客
http://blog.csdn.net/u011513323/article/details/38271589
标准的JSP标记可以调用JavaBeans组件或者执行客户的请求,这大大降低了JSP开发的复杂度和维护量。JSP技术也允许你自定义的taglib,其实换句话说,taglib可以看成是对JSP标记的一种扩展,正如xml是对html的一种扩展一样。taglib通常定义在tag标签库中,这种标签库存放着你自己定义的tag标签。简而言之,如果使用taglib,那么你可以设计自己的JSP标记。
一般来说,自定义tag标签主要用于操作隐藏对象、处理html提交的表单、访问或其他企业级的服务,诸如邮件和目录操作等等。自定义tag标签的使用者一般都是那些对编程语言非常精通,而且对数据访问和企业级服务都非常熟悉的程序员,对于HTML设计者来说,使得他可以不去关注那些较复杂的商业逻辑,而将精力放在网页设计上。同时,它也将库开发者和库使用者进行合理分工,自定义tag标签将那些重复工作进行封装,从而大大提高了生产力,而且可以使得tag库可用于不同的项目中,完美地体现了软件复用的思想。
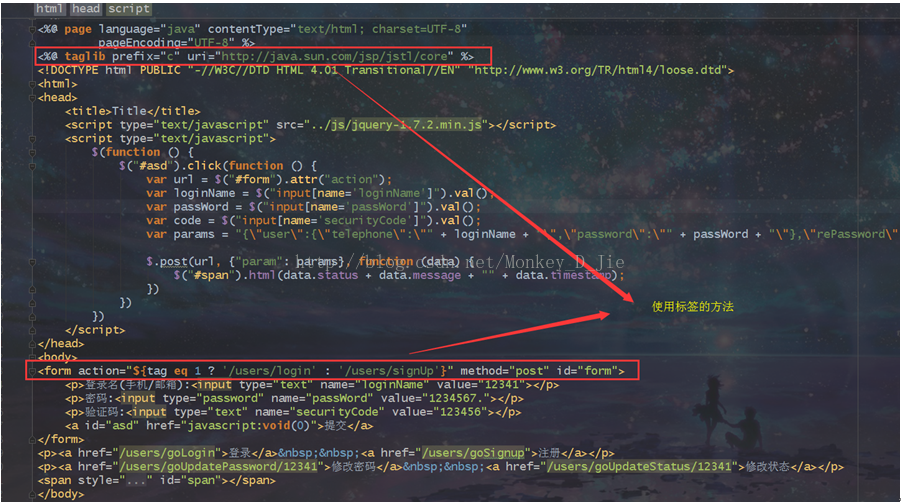
前端页面中href="javascript:void(0);"与#的区别
http://blog.csdn.net/minedayu/article/details/38172101
href="javascript:void(0);"与#的区别 - 技术分享 - CSDN博客
JavaScript将<a>标签设置为空链接有两种方式,第一种是href="#",另外一种是href=":void(0);"。两种方式都设置了标签为空链接,但是两种方式还是有些不同的地方。
href="#",当点击的时候会跳转到页面的顶部,相当于点击了一个锚点,在URL的后面也会出现一个#的标识符号。
javascript而href=":void(0);"则是要执行一个javascript的表达式。void(0)不执行也不返回任何东西,因此不会发生任何跳转。
所有设置空链接推荐用href="javascript:void(0);"
【补充内容】
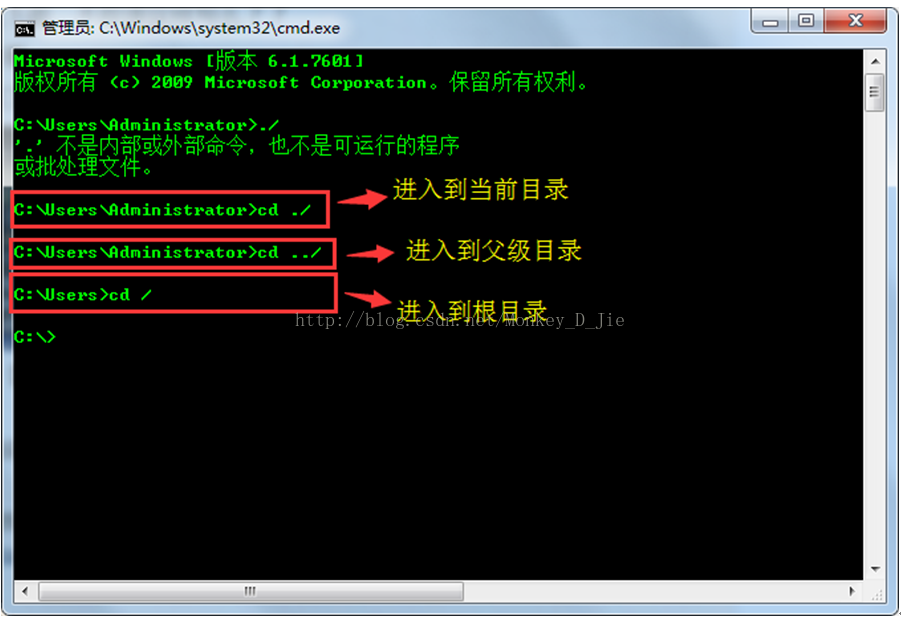
./和../以及/之间的区别?_百度知道
https://zhidao.baidu.com/question/544197599.html
当前目录./
在xml配置文件的XMLS,xsi都是干嘛的?
http://bbs.csdn.net/topics/390751819
xml中的xmlns,xmlns:xsi,xsi:schemaLocation有什么作用,如果没有会怎么样呢-CSDN论坛
我来给你解释一下吧,首先这个文件是一个xml文件,那么他里面的所有内容都符合xml语法规范,开头的<project></project>这最外层同样也是一个xml文件的标签,后面那一长串也就是所谓的属性,其中xmlns表示命名空间,xmlns="http://maven.apache.org/POM/4.0.0" 这表示默认命名空间,而下面xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 这个命名空间里面的元素或者属性就必须要以xsi:“xxxx”中说明的这种方式来写,比如schemaLocation就是他的一个属性,所以写成xsi:schemaLocation,而默认命名空间不带类似xsi这种,其实xml标签名称有个专业叫法叫做QName,而如果没有前面的xsi:这种一般叫做NCName。所以你看mvn里面的<dependency>这种就是默认命名空间下面的元素,最后那一行就表示把定义这个命名空间的schema文件给引用进来,好让eclipse这类型工具能够解析和验证你的xml文件是否符合语法规范。等同于<import namespace="xxx" schemaLocation="xxx.xsd"/>。
xsi---》这个包下又分为电焊用的,修水管儿,修共享单车的
xsi:xxxxxx-----》XXX代表的是某个包下的具体工具,比如水管包儿下的扳手,电焊包儿下的焊枪
xsd-----》就是具体工具的说明书咯,该怎么用,用在哪儿。。。是跟谁说呢?跟Eclipse说。用法对了,才能正常的展开工作嘛!
业务流程梳理上的一些注意点
http://bbs.csdn.net/topics/370259044
首先是一个大背景,即软件设计的背景
其实,对于IT业摸爬滚打多年的从业人士来说,一般都能有这样的一个认识或者共识:中国的软件业缺乏设计。
中国的软件行业人才架构是典型的金字塔型,而且我们现在工作的方式有多少公司不是站在眼前利益的角度上看问题呢。从这个角度来看,这是造成设计缺失的一个原因。
前段时间,听朋友说,印度有家公司在招纳程序员时首先要做的就是培训,最后他们给出了一个这样的结果:两名程序员经过培训后针对同一个题目编程,最后两人的代码居然完全一样,甚至是变量的命名。
我们在说设计,中国目前来说是中小公司多,而且非常多。而公司的人才架构又不可能像大公司那样,而且团队的磨合程度也需要时间的问题。不同层次的人对待同一件事物的认知程度又不一样,那么如何能够在项目中总结成一套适合自己团队体系的【沟通-设计-开发】的流程的确是一件不容易的事情。
目前软件行业有很多开发方法或流程,但这些东西不是直接拿来主义的,需要有经验的人在运用过程中不断的扩展与剔除。
实际的项目中,必定会有很多生涩难懂的业务,那么针对沟通,UML是最好的选择,开发与开发,开发与测试,经理与客户等!比较好的工具比如说EA,这东西比较好。目前我们的团队就是使用这个,支持正反向工程,支持SVN等。
刚加入公司,如何快速熟悉公司项目并快速上手 - 王学武的专栏 - CSDN博客
http://blog.csdn.net/wang_xuewu/article/details/49534281
1.它强迫你去学习“正确”的信息。如果你只获取完全必要的信息,完全必要的信息被定义为:它能让你做必要的事情。
2.它将强迫你去做你在短时间内能够实现的事情。如果任务A需要学习很多东西,而任务B需要很少,做任务B吧,它将让你花费更少的时间去学习预备知识,你将快速的完成目标。
3.它将防止你因为试图获知所有的事情这样的任务而心烦,提供给你一个更加有用的学习准则去从正确的地方开始你的工作。
如何让项目成员尽快熟悉系统业务? - 知乎
https://www.zhihu.com/question/21883136/answer/24717781
2)回到到业务系统上,了解其大致的核心业务功能模块,以及各模块之间的联系和衔接方法
3)然后再上升到架构层面,数据交互是怎样的?CS,BS,端到端等等。。以及这个业务系统在实际的应场景中的地位,它同上游(用户)和下游(数据传输)在业务上的联系,相互间协同作用。















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









