









Python 2.7
IDE Pycharm 5.0.3
刚开始学python,学到抓取网页URL的时候,按照书本教材,采用urllib2来抓取网页,但是遇到中文字符时候显示乱码。如果把编码格式全部默认,则会导致中文字符注释不同通过,中文打印出现问题。这里暂且说一下解决方案。
在文件开头加入这句话
# -*- coding: utf-8 -*-
这是保证你注释中文的时候,和打印中文的时候能正常显示的前提。
当然,设置在这里。如图所示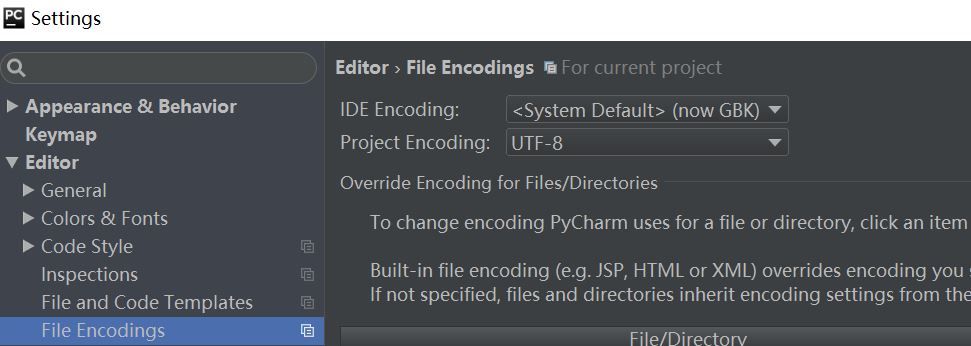
测试程序
# -*- coding: utf-8 -*-
print("这是一个测试程序test")#中文注释
import urllib2
req = urllib2.Request('http://www.csdn.com')
response = urllib2.urlopen(req)
the_page = response.read()
print the_page
可以看出,中文打印和注释都没有问题,网页抓取也没有问题。再测试一个网页
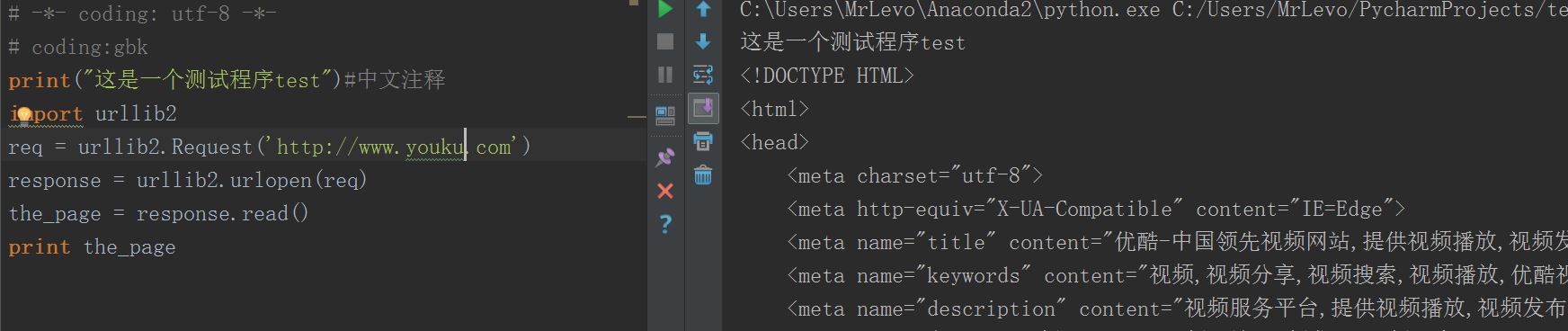
ok,优酷也正常
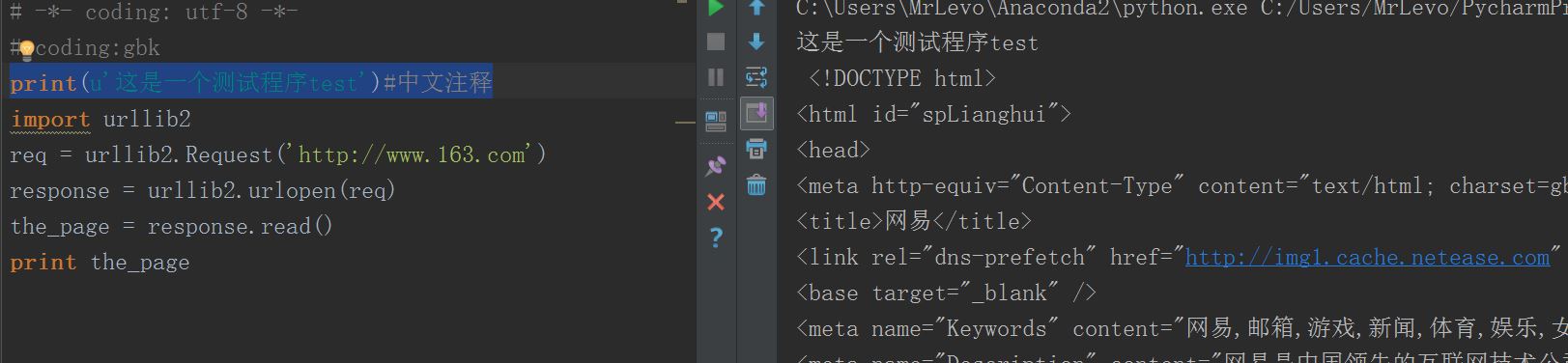
然后测试网易(搜狐同样出错)
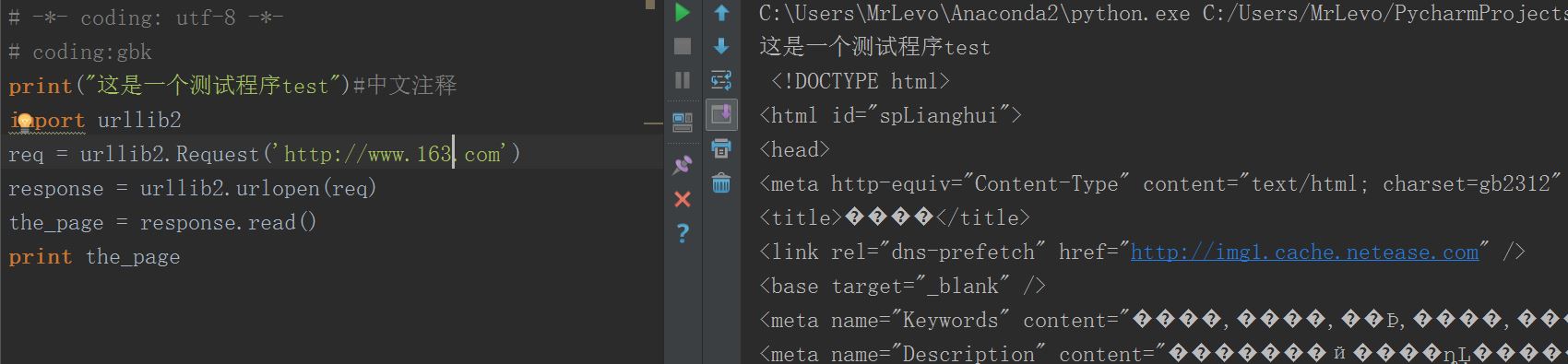
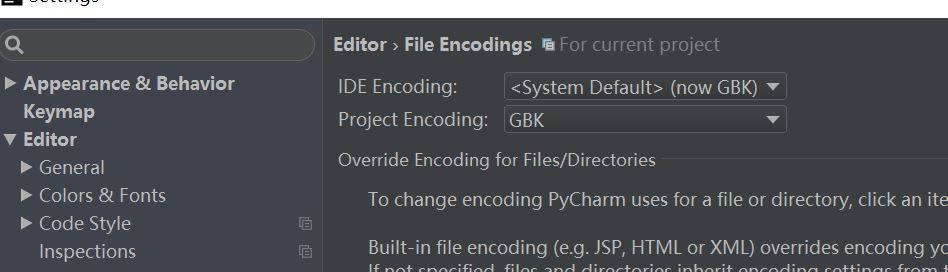
出现乱码了,解决方法如下:
修改完后测试,网页中文正常,但是,中文print乱码
修改print代码:
print(u'这是一个测试程序test')#中文注释
这样就可以正常显示网页中文和print中文;
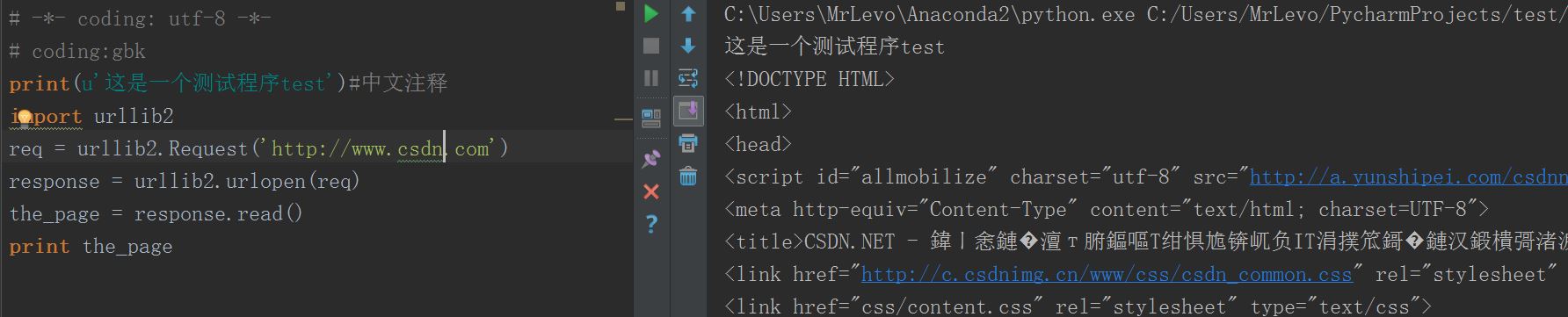
那之后重新测试csdn呢,结果肯定乱码啦,没办法,编码方式不同。
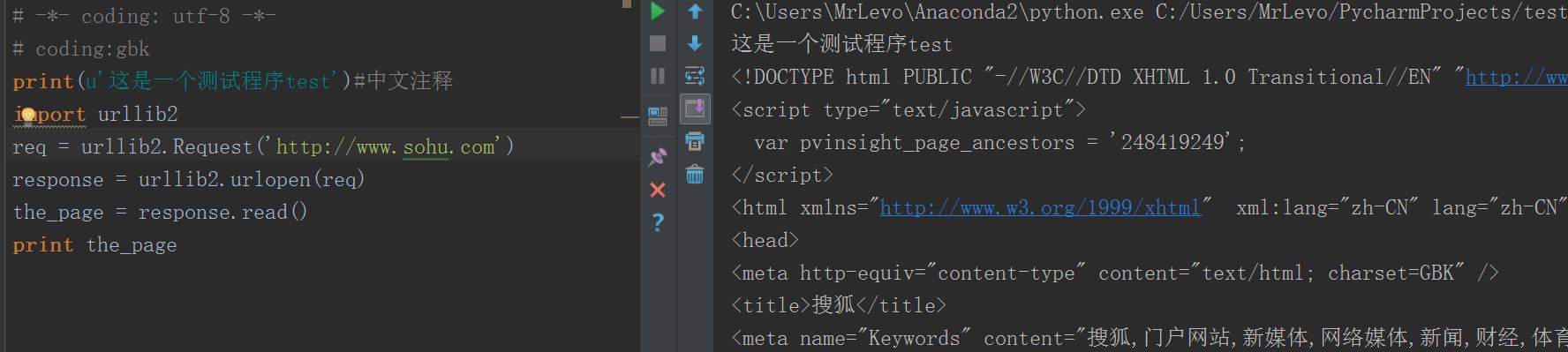
测试搜狐(和网易是一个编码方式吧)所以显示正常
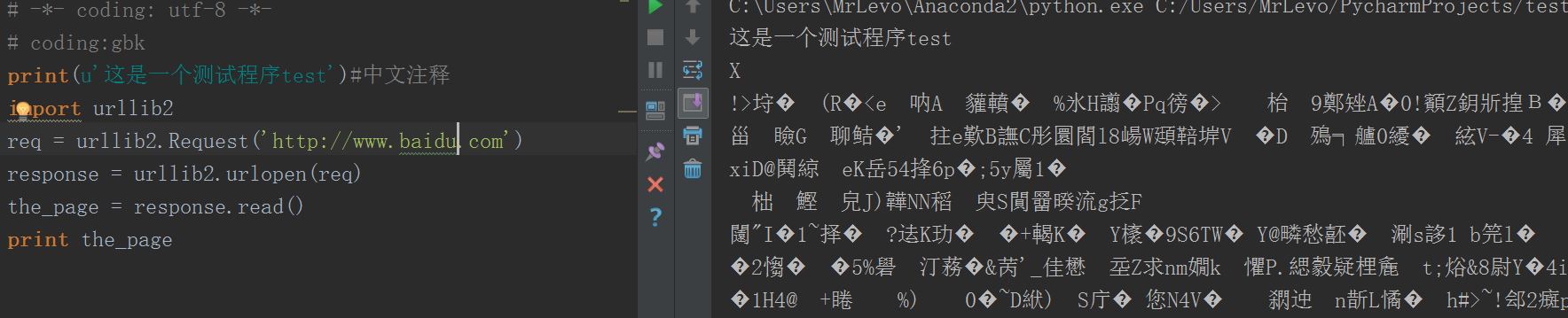
然而,最后的百度,我用urllib2无论怎么改编码格式,都抓不到,全是乱码:
有种取巧的方法,采用如下编码:
import requests
url="http://www.baidu.com"
html = requests.get(url)
print html.text7.28补充
可以采用urllib2+BeautifulSoup的方法来抓百度的网页,中文正常显示
from bs4 import BeautifulSoup
import urllib2
url='http://www.baidu.com'
html_url = urllib2.urlopen(urllib2.Request(url))
bs_url = BeautifulSoup(html_url.read(),'lxml')
print bs_url.prettify()虽然可以抓到网页,也没有乱码,但这个requests对其他网页貌似不是很友好,而且又要换编码格式,我的天(掩面哭),不然它就这样:

改成utf-8后就可以正常显示了;
小弟刚接触Python,发现些问题,只有自己摸索答案,网上的基本都看了,但是就是没有针对这款Pycharm的解决方案,斗胆放上解决策略,以后若有长进,再回来修改。
请大家不吝赐教。
6.15更新,其实只要在后面跟上decode(‘gbk’)就可以了,简单转换乱码。。。。果然我还是太幼稚了,哈哈
import urllib2
req = urllib2.Request('http://www.163.com')
response = urllib2.urlopen(req)
the_page = response.read().decode('gbk')
print the_page














 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









